
A Survey on the LLM Released in Q1 2025
A Comprehensive Analysis of Q1's Breakthrough Language Models and Their Strategic Implications


Introduction
When OpenAI released o3 in late December 2024, it set a new bar for AI reasoning models. With its ability to “think” through multiple solution paths before producing an answer, o3 achieved breakthrough performance on complex tasks like mathematics and coding. Just weeks later, DeepSeek countered with R1 - an open-source model challenging o3’s abilities at a fraction of the cost.
This face-off highlights the growing rivalry between open and closed-source AI approaches. Companies like OpenAI and Google keep their best models locked behind APIs, charging premium prices for access. Meanwhile, organizations like DeepSeek and Mistral make powerful models freely available for anyone to download and modify.
The tension goes beyond business models. 2024 data shows that 41% of organizations actively replace closed models with open alternatives, citing concerns about data sovereignty, customization freedom, and cost efficiency. Yet closed models maintain advantages in raw performance, leading benchmarks by 5-15% on average tasks.
This pattern extends across both model types released in Q1 2025:
Open-source leaders (DeepSeek R1, QwQ-32B, Mistral Small 3) offer impressive capability-to-cost ratios
Closed-source leaders (GPT-4.5, Claude 3.7, Gemini 2.5) push performance boundaries at premium prices
In this article, we’ll explore these models, compare their strengths, and provide practical guidance on which options make sense for different needs and budgets. Whether you’re a researcher, business leader, or curious observer, this guide will help you navigate the rapidly evolving AI landscape of 2025.
Open-Source Foundation Models: Democratizing Advanced AI
The first quarter of 2025 brought some significant surprises in open-source AI. The most shocking? Smaller models are now punching way above their weight class.
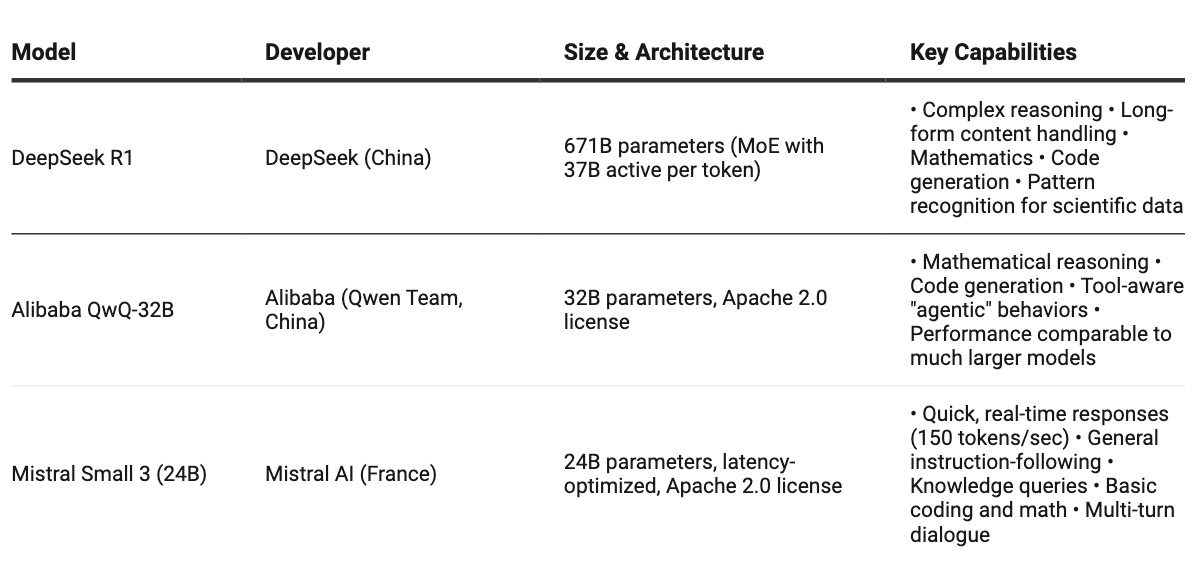
Take Mistral Small 3, a 24-billion parameter model from France. Despite being tiny compared to giants like GPT-4, it scores an impressive 81% on the MMLU benchmark (a test of college-level knowledge). Even more impressive, it runs at 150 tokens per second - about three times faster than models triple its size. This means it can actually run on your laptop if you have 32GB of RAM!
Alibaba’s QwQ-32B shows similar efficiency. At just 32 billion parameters, it somehow matches the performance of DeepSeek R1 - a model 20 times larger - on complex question answering. How? Alibaba focused heavily on reinforcement learning during training, teaching the model to reason step-by-step rather than just memorize patterns.
Meanwhile, DeepSeek R1 represents the other approach - going big. At 671 billion parameters, it's the largest open-source model ever released. But it's not just big for show. DeepSeek uses a clever "Mixture-of-Experts" design, where only a tiny portion (37B) of the model activates for any given task. This makes it much more efficient than its size suggests.
What’s really interesting is where these models come from - China and France, not the US tech giants. This regional diversity is pushing innovation in different directions:
Chinese models focus on raw capabilities and efficiency
European models prioritize speed and practical deployment options
All prioritize open access under permissive licenses
The gap between open and closed models is narrowing fast. DeepSeek R1 ranked fourth on Chatbot Arena (a blind comparison test)—higher than many commercial offerings. Both smaller models outperform proprietary systems from just a year ago.
Each model makes different tradeoffs:
DeepSeek R1: Maximum capability, but needs serious hardware
QwQ-32B: Great balance of reasoning power and practical size
Mistral Small 3: Optimized for speed and everyday deployment
This means developers now have real choices rather than just taking whatever scraps big tech companies decide to release. Want to run AI locally? Mistral’s your choice. Need maximum reasoning power but can’t afford API fees? DeepSeek has you covered. Building a product that needs strong reasoning without breaking the bank? QwQ-32B fits perfectly.
3. Closed-Source Foundation Models: Pushing the Boundaries
The closed-source landscape in early 2025 reveals an intense battle among tech giants, with reasoning capabilities becoming the new frontier.
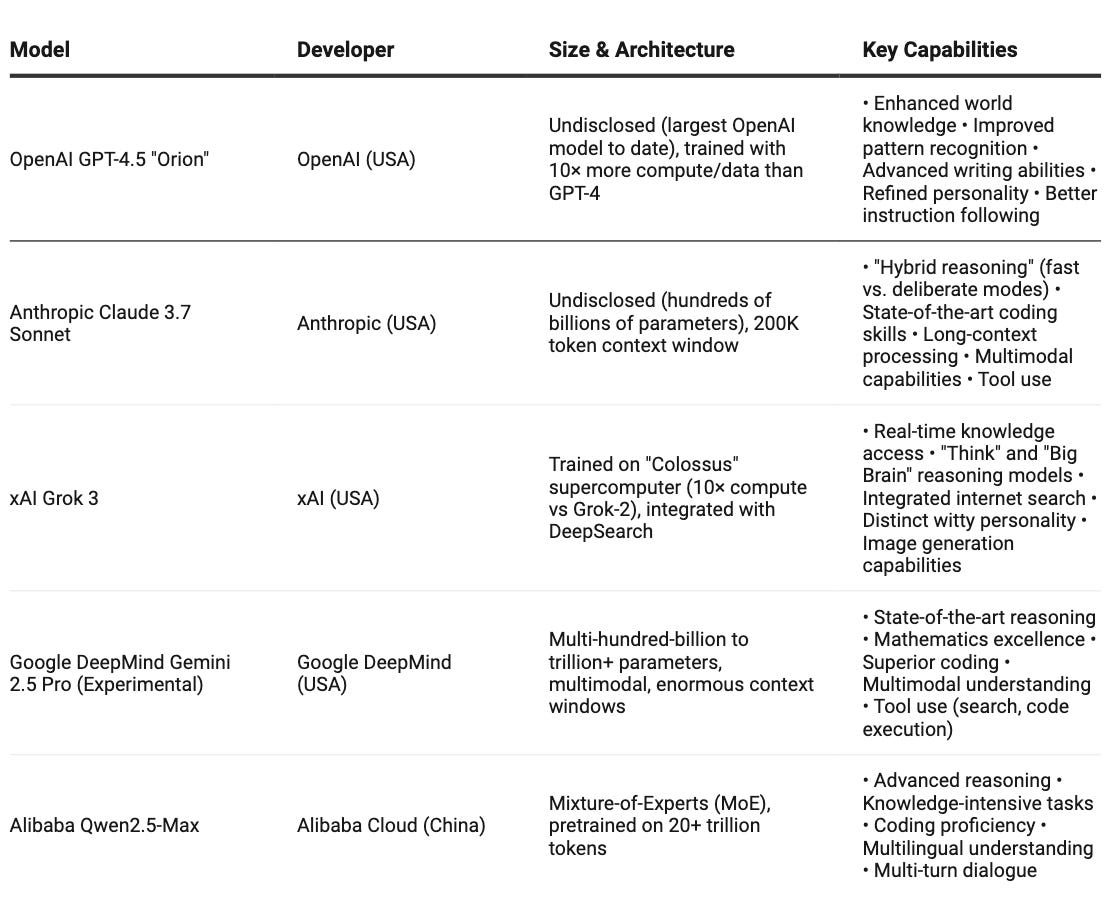
Google DeepMind’s Gemini 2.5 Pro leads the pack, claiming the #1 spot on LMArena with a significant margin. It's the first "thinking model" that deeply integrates chain-of-thought reasoning into its responses. With state-of-the-art math and coding skills, it achieved an impressive 63.8% on SWE-Bench, far exceeding competitors.
OpenAI’s GPT-4.5 "Orion" represents an evolution rather than a revolution. Trained with 10x more compute than GPT-4, it shines in reducing hallucinations and following instructions more precisely. OpenAI calls it their "most knowledgeable model yet," but interestingly, they don’t consider it a "frontier" breakthrough.
Anthropic’s Claude 3.7 Sonnet introduces a fascinating innovation - “hybrid reasoning.” It can respond instantly or engage an extended thinking mode for complex problems. With a massive 200K token context window and industry-leading 70.3% on the SWE-Bench coding benchmark, it's particularly suited for software development and data analysis.
Meanwhile, Alibaba’s Qwen2.5-Max shows China isn’t just competing - it’s leading in some areas. It scores 89.4% on Arena-Hard (beating DeepSeek R1’s 85.5%) and demonstrates impressive reasoning while requiring fewer computational resources, thanks to its Mixture-of-Experts design.
Elon Musk’s xAI Grok 3 takes a different approach, focusing on real-time knowledge through its DeepSearch tool. It introduces specialized modes (like “Think" and “Big Brain”) and maintains a distinctly witty personality, though performance-wise, it sits slightly behind the largest models on standard benchmarks.
Each model takes a slightly different approach:
Google focuses on raw reasoning power and mathematics
OpenAI prioritizes reduced hallucinations and writing quality
Anthropic emphasizes hybrid modes and coding abilities
Alibaba balances performance with computational efficiency
xAI integrates real-time knowledge and personality
The trend is clear - closed models are differentiated through specialized reasoning modes, real-time knowledge integration, and efficiency innovations, not just raw scale.
The East-West AI competition intensifies, with Chinese models increasingly matching or exceeding their Western counterparts.
The East-West AI competition intensifies, with Chinese models increasingly matching or exceeding their Western counterparts.
4. Finding Your Match: Who Should Use What
With so many powerful models available, which one fits your needs? Let’s break it down:
For researchers with limited budgets:
DeepSeek R1 offers cutting-edge capabilities without API costs
Fine-tune QwQ-32B for specialized research - it’s smaller but surprisingly capable
Access to model weights means unlimited experimentation
For businesses building products:
API options: Claude 3.7 for complex reasoning, GPT-4.5 for reliability
Self-hosted options: Mistral Small 3 offers great speed-to-performance ratio
Consider total cost: APIs can be cheaper for low volume, self-hosting for high volume
For specialized needs:
Coding: Gemini 2.5 Pro (63.8% on SWE-Bench) or Claude 3.7 (70.3%)
Math/reasoning: DeepSeek R1 excels at complex problem-solving
Real-time data: Grok 3’s DeepSearch provides up-to-the-minute responses
Long document processing: Claude 3.7's 200K token context is unmatched
For deployment constraints:
Mobile/edge: Mistral Small 3 runs on high-end laptops
On-premises: QwQ-32B offers great performance-to-resource ratio
API-only: Most closed-source options require no infrastructure
Performance vs. accessibility tradeoffs:
Closed models lead by 5-15% on most benchmarks but cost more
Open models offer 80-90% of capabilities at a fraction of the cost
The gap is narrowing every quarter - today’s closed capabilities are tomorrow’s open ones
Choose based on your specific needs rather than hype or size. Sometimes a smaller, more focused model outperforms giants on specialized tasks - and almost always runs faster and cheaper.
Conclusion
As we look toward the rest of 2025, the data points to several clear trends in AI development. Open models are expected to close the performance gap with closed models. By year-end, they should be within 5% of closed-source capabilities, based on industry analyses.
Enterprise adoption is speeding up. McKinsey data shows that 73% of businesses use open-source models for internal processes. Also, 58% apply closed models for customer-facing applications. This hybrid approach will become the new standard.
The most significant shift will be AI's transition from general tools to specialized reasoning engines. Innovations in model context protocol, test-time search, transparent chain-of-thought, and hybrid reasoning will go beyond just technical benchmarks. They will change everyday applications too.
The AI landscape will provide more options at lower costs for people and organizations. Differentiation will shift from basic skills tounique strengths. It will allow for flexible deployment and match specific needs.