
AI Observability And Evaluations: The Operating System For Reliable LLM Products
A practical guide to measuring LLM behavior, catching silent failures, and improving with real production data.

TLDR: Most LLM products don’t crash. They quietly leak trust, safety, and budget. Silent failure is the default failure mode, and most teams never see it coming. This is a practical guide for engineers and PMs shipping LLM features in production. You will leave with a concrete framework for instrumenting runs, version prompts, design rubrics, catching silent failures, and switching models without fear. The moat is measured improvement, not prompt cleverness.

Introduction
Why LLM Products Break Quietly Without Observability
When I build LLM features, I do not worry about clever prompts first. What I worry about is that the team can’t see what the system is doing when it fails.
In this blog, I am making the case that reliability starts with visibility, not vibes.
The motivating question is simple. What is the equivalent of GitHub plus unit tests for an LLM application where the behavior is shaped by prompts and shifting context? Without that substrate, teams ship changes they cannot review, cannot regress, and cannot explain.
Silent failure becomes the default failure mode. The output looks coherent, the user seems satisfied, and the product metrics stay flat.
Underneath, the system may be wrong, unsafe, or quietly violating policy. That is why I treat observability and evaluations as the reliability layer. They turn unknown behavior into inspectable behavior, then measurable behavior.
Tool use raises the stakes. Once a model can act, a conversation becomes an execution surface. For instance, if the app can issue refunds, the “executable code” can be embedded in the chat thread itself.
The incident pattern is quite familiar.
A support bot approves a refund it should not, the customer is happy, and the mistake only shows up later as leaked margin and policy debt.
Key points I’m making:
LLM apps need a review and regression discipline comparable to code.
Silent failure is more common than loud failure.
Tool calls convert text into real operational risk.
Observability plus evals create accountability for behavior.
How I’d implement this:
Instrument every run with prompt version, context, tool calls, cost, and latency.
Sample real cases and curate a small starting dataset.
Run a small eval set on every change.
Monitor for drift and escalate failures into the dataset.
Next, I will reframe prompts as business logic you have to govern.
Prompts Are Executable Business Logic In Production
When I say prompts matter, I do not mean prompt wording as a copywriting exercise.
I mean prompts as runtime logic that drives what the system does.
In production, a prompt is not configuration text. It becomes executable business logic as soon as the model is embedded inside a product that can read data and take action.
The program is not a single string. The program is the assembled runtime bundle that the model receives and acts on. If you do not model it as a bundle, you cannot reason about behavior. You end up debugging the wrong layer, then shipping fixes that only work on one happy-path input.
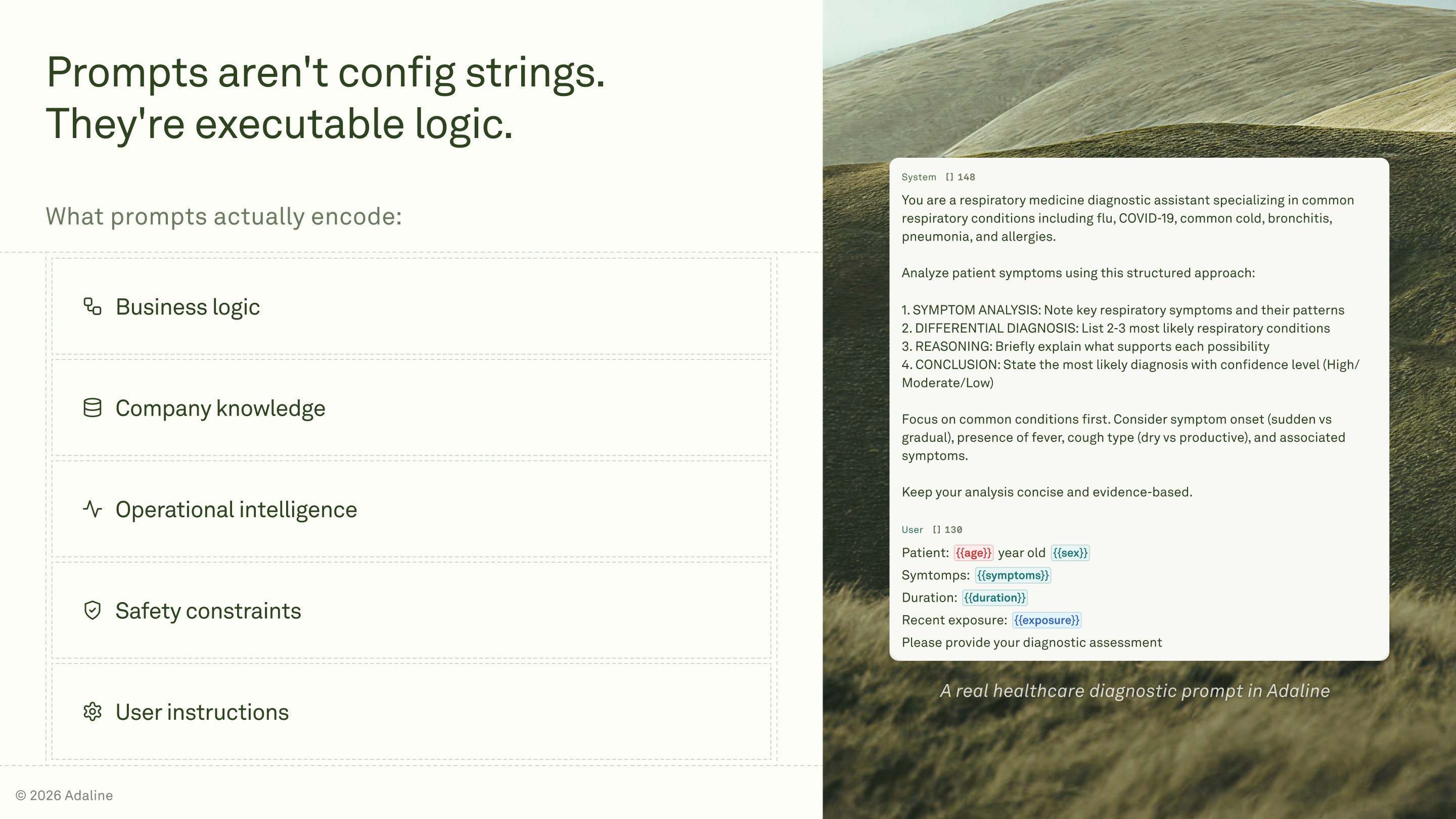
The runtime bundle includes:
System and developer instructions.
Dynamic variables and session state.
Retrieved context.
User input, untrusted.
Tool permissions and safety constraints.
Runtime parameters, model version, and temperature.
I plan for instruction conflicts because they occur in real systems. A user message can contain a directive that tries to override the instruction layer.
A retrieved document can contain hidden instructions that pull the model off task.
The model may still produce fluent output even when following the wrong instruction, which is why this failure is hard to notice without measurement. This maps directly to the prompt-injection risk category in standard LLM threat models.
Key points I’m making:
The prompt bundle is the real program, not the UI chat box.
Untrusted inputs create instruction conflicts by default.
Tool permissions turn text into operational decisions.
Reliability requires governance, not prompt folklore.
How I’d implement this:
Version prompts and treat edits like code changes.
Require diffs for every prompt revision.
Maintain rollback points for prompt and model versions.
Assign ownership per prompt surface area and workflow.
If this is runtime logic, I need runtime traces.
What Observability Means For LLM Systems
I have a narrow definition of observability for LLM systems. I want to reconstruct a run the same way I would reconstruct a production incident in any other distributed system. If I only log the final output, I am guessing.
In practice, observability means end-to-end traceability across prompt assembly, retrieval, tool calls, and outputs. That too, with enough context to explain why a specific response happened.
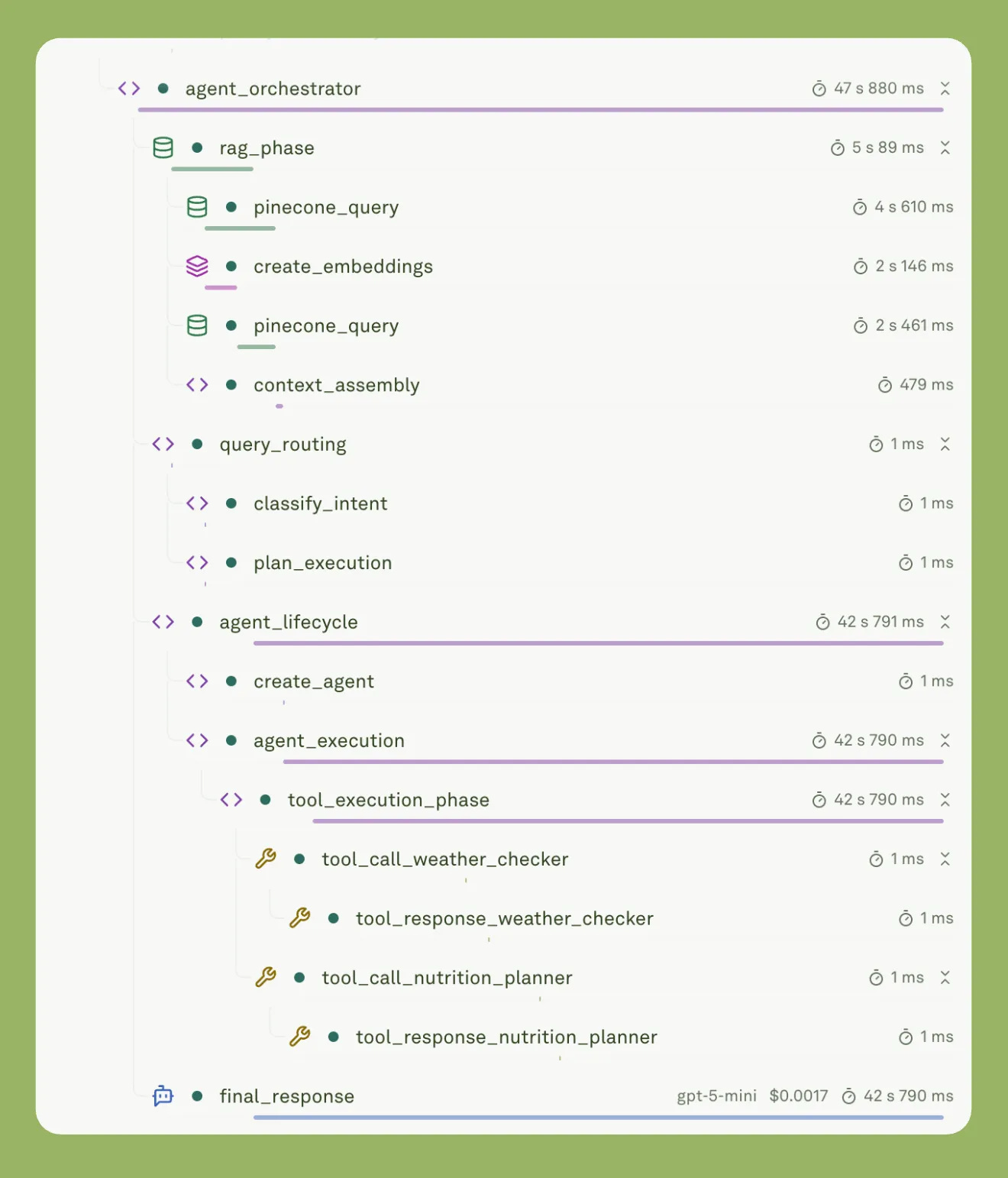
Readable traces matter because they reduce debugging time, make ownership clear, and let me iterate without shipping blind changes. When the trace is legible, a failure becomes a concrete artifact, not a debate.
Trace checklist:
Prompt template version, which is a static instruction. And assembled prompt which are variables, i.e., dynamic. The idea is to separate static instructions from variables.
User input, to capture the untrusted trigger.
Retrieved context payload plus retrieval metadata, to validate what the model actually saw.
Tool calls, arguments, responses, and side effects to audit real actions.
Model identifier, version, and runtime parameters, to attribute behavior to runtime choices.
Token usage and estimated cost, to catch budget regressions.
Latency breakdown, to localize slow spans, including model server time .
Final output and structured output if present, to verify compliance and formatting.
When I see a bad answer, the trace tells me where to look.

If the retrieval returned irrelevant context, I fix the retrieval. If tool calls are wrong, I fix tool selection and constraints. If the same input flips behavior after a prompt edit, I fix the prompt structure, not the dataset.
Key points I’m making:
Observability is traceability across the full run, not output logging.
Accountability and speed up iteration.
Cost and latency are first-class failure signals.
Tool call visibility is non-negotiable once actions are in place.
Prompt versioning and deployment in Adaline.
How I’d implement this:
Standardize a trace schema and enforce it for every run.
Store prompt versions and attach them to every trace.
Log retrieval inputs and outputs with stable identifiers.
Capture tool calls as structured events with side effects.
Add a weekly review of failed traces and recurring patterns.
Once you can see runs, you can classify failures.
The Silent Failure Taxonomy I Built Around
Silent failures do not crash the system. They leak trust, safety, and budget a little at a time. In the lecture, I push on this because you can ship something that looks fine, then wake up to a week of damage that never showed up as an error page.
Generally, to tackle this issue, I built categories around these failures. Because monitoring and evaluation need targets. A taxonomy keeps the team from treating every issue as a prompt problem.
It also keeps alerts honest. I believe you can only alert on what you can name and measure.
Being hyperspecific to details is the key here.
Taxonomy I use in practice:
Policy failures that look like success: The signal to monitor includes tool call policy violations and missing approvals.
Security failures, prompt injection, and instruction conflicts: Signal to monitor includes override patterns and tool intent that contradict constraints.
Cost and latency failures, token blowups, loops, OCR weirdness: Signal to monitor includes token spikes, repetition, and timeouts.
Correctness failures masked by fluency: The signal to monitor includes missing citations, schema drift, and low agreement with the provided sources.
The incident I plan for is boring, which is the point.
We switched to an OCR workflow, everything looked normal, then costs spiked. The model started appending long runs of spaces, producing around 100,000 characters when 5,000 would have been enough.
Now, customers did not notice at first. But the trace made it obvious, so we tightened the prompt and added a cost guardrail.
Key points I’m making:
Failures show up as drift, not downts, and alerts are concrete.
Security and cost issues can hide behind good-looking text.
How I’d implement this:
Map each category to a small set of measurable signals.
Alert on deltas, not absolutes, for cost and latency.
Triage from traces, then promote repeats into eval datasets.
Add a post incident rule that prevents the same class from returning.
To evaluate any of this, I need representative cases.
Evaluations Start With Sampling The Real Distribution
When I watch teams build LLM features, the demo is rarely the hard part. The demo is one clean input, one clean output, one clean conclusion.
Production is a distribution, and the distribution is where behavior fractures.
A demo lies because it compresses variability into a single scenario. It hides messy inputs, conflicting instructions, and long tail formats. It also hides drift.
A prompt can look stable on five hand-picked examples, then break on day three because a new user arrives with a new intent. This is a very common issue.
So, how to tackle it?
I start evaluations by sampling the real distribution.
My baseline is simple. I take about 20 representative cases that look like what I expect to see in production, I run them, and I ship.
Then I expand the set using the evidence provided by production.
Observability supplies the raw material.
Traces become cases, cases become datasets, datasets become evaluations.
OpenAI’s evaluation guidance makes the same point. Mix production data with expert-curated cases, keep adding edge cases, and keep the set growing as you learn.
Key points I’m making:
One clean example hides the distribution.
A small representative set beats intuition.
Traces are the source of evaluation data.
Datasets must evolve with customers and inputs.
How I’d implement this:
Seed the first dataset from traces whenever possible.
Include messy and adversarial inputs in the first 20.
Add failures and near failures every week.
Refresh the dataset when the customer types or document formats change.
Tag cases by intent and input modality for coverage checks.
I have seen a new customer type break assumptions overnight. The trace showed the same prompt behaving differently because the inputs shifted, not because the model changed. The dataset made that visible fast, then the fix became measurable.
Now I can talk about evals as a feedback loop.
Evaluation Is A Feedback Loop, Not A Unit Test Suite
I have a strong view on evals because I have watched good systems fail for boring reasons. A prompt change sounds better to a human. But production makes it worse.
So, I am making the explicit claim that evals are feedback loops, not deterministic unit tests.
Essentially, their job is to keep me shipping while protecting the downside. I run them to catch regressions when I edit prompts, to switch models without fear, and to detect drift once the system is live.
Perfect coverage is impossible because users will always do something you did not anticipate.
That is fine.
The goal is not perfection.
The goal is fast learning with controlled risk.
Starter eval set I begin with:
Schema and format adherence, so outputs stay parseable.
Tool and policy compliance to keep actions permitted.
Citation or reference presence where required, so answers stay auditable.
Refusal correctness for disallowed requests, so boundaries hold.
Groundedness to provide context, so answers do not drift from inputs.
Cost gate or latency gate, so the product stays within constraints.
Retrieval sanity check, so the model is not reasoning on garbage context.
Here is a mini example from real work.
I have seen a small prompt change that helped one slice of cases and failed another, like drug A versus drug B.
The new prompt read cleaner, then broke the distribution. A basic eval suite made the regression visible before it became a support incident. This matches the eval-driven workflow OpenAI recommends, especially the practice of collecting production-like data and evaluating continuously.
Key points I’m making:
Evals exist to learn quickly, not to certify perfection.
They protect model switches, prompt edits, and production drift.
Coverage grows from failures, not imagination.
How I’d implement this:
Run the eval suite on every prompt or model change.
Label failures as prompt regression, retrieval regression, rubric mismatch, or distribution shift.
Fix the correct layer, then add the failing case to the dataset.
Track cost and latency gates as hard constraints, not nice metrics.
Evals only work if I define good as outcomes.
How I Design Rubrics From Product Outcomes
I design rubrics the same way I design product requirements. I start from what the user must be able to do next. If the rubric cannot predict the next action, it is taste, not engineering.
Evaluating prompts using LLM-as-a-judge metric with custom rubrics in Adaline.
Outcome-first grading means I translate the user goal into observable checks. A good rubric is specific about required fields, hard constraints, grounding to provided inputs, and safe tool behavior.
In high-stakes workflows, I do not pretend engineers can invent correctness. In my experience, the people who own prompts and the people who write rubrics are often domain experts. Someone like clinicians and finance specialists, because they know what the output must contain and what it must never do.
Here is what this looks like in practice. Micro rubric for a support response.
It acknowledges the user request in one sentence without adding new claims.
It applies the correct policy constraint for eligibility and required approvals.
It uses the provided account context and does not invent missing details.
It selects the correct tool action only when permitted and necessary.
It ends with the next step the user should take, if any.
Rubrics drift because products drift. You add customers, new input formats arrive, and the distribution changes.
When a system works for months and rubrics suddenly fail, I treat that as a signal that the rubric may need to change, not just the prompt.
Clear, detailed rubrics also make automated grading more reliable. This is why I write them like executable criteria rather than guidelines.
Key points I’m making:
I define good as a usable next step for the user.
Rubrics encode constraints, not stylistic preferences.
Domain experts define correctness in high-stakes domains.
Rubrics evolve with the input distribution.
How I’d Implement This
Assign rubric authorship to the domain owner for the workflow.
Review rubrics weekly using fresh failure cases from traces.
Update the rubric first when the distribution changes, then update the prompt.
Keep a change log so rubric edits are auditable.
Next, I will show how I scale these checks with model-based graders.
LLM As Judge, But Only Under Constraints
I use model-based judges or LLM-as-a-judge, because some checks do not reduce cleanly to code. Tone, completeness, and policy reasoning often need language understanding. A judge can also scale review across thousands of traces without turning the team into a labeling factory.
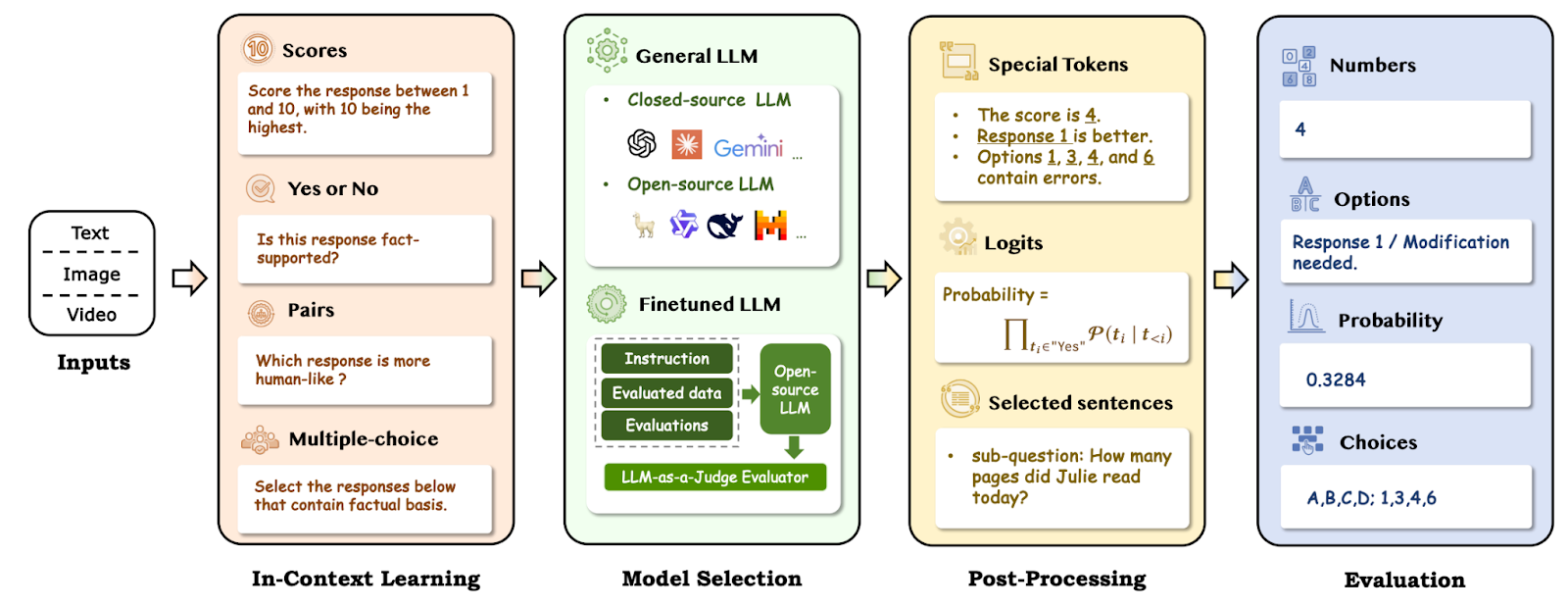
A working illustration of LLM-as-a-judge. | Source: A Survey on LLM-as-a-Judge
My rule is strict. I prefer pass/fail or a small set of named categories. I avoid numeric scoring. In the lecture I gave, I called this out as the easiest way to cripple the entire system because confidence intervals and arbitrary scales do not stay consistent across runs .
When I need nuance, I use semantic labels that carry meaning, not numbers that float.
I ask for reasoning when the verdict depends on a rubric with multiple clauses. I want a short justification tied to rubric items, then the verdict. For everything that should be deterministic, I do not use a judge at all.
I validate schemas with code.
I gate tool calls with policy checks.
I block-banned actions and formatting violations before any judge runs.
OpenAI also recommends structuring evaluations around criteria and using pass/fail or comparisons to improve reliability in judge workflows.
Key points I’m making:
Judges help with nuance, not with mechanics.
Binary beats numeric for stability.
Reasoning improves alignment with the rubric.
Deterministic constraints should stay deterministic.
How I’d implement this:
Provide a rubric with clear pass/fail examples.
Provide the full context, including retrieved snippets and the tool plan.
Require a short, grounded reason.
Output a verdict as pass or fail, or a named category.
Once judging is stable, I run it continuously in production.
Continuous Evaluation In Production Is Where Reliability Compounds
Continuous evaluation is where reliability compounds. Monitoring is the keystone because it captures the real distribution, including the unknown unknowns, and turns them into something the team can act on.
I define continuous evaluation as lightweight checks applied to production traces. I do not wait for support tickets to tell me something drifted. I want the system to tell me first. That is the difference between a small regression and a week of silent damage.
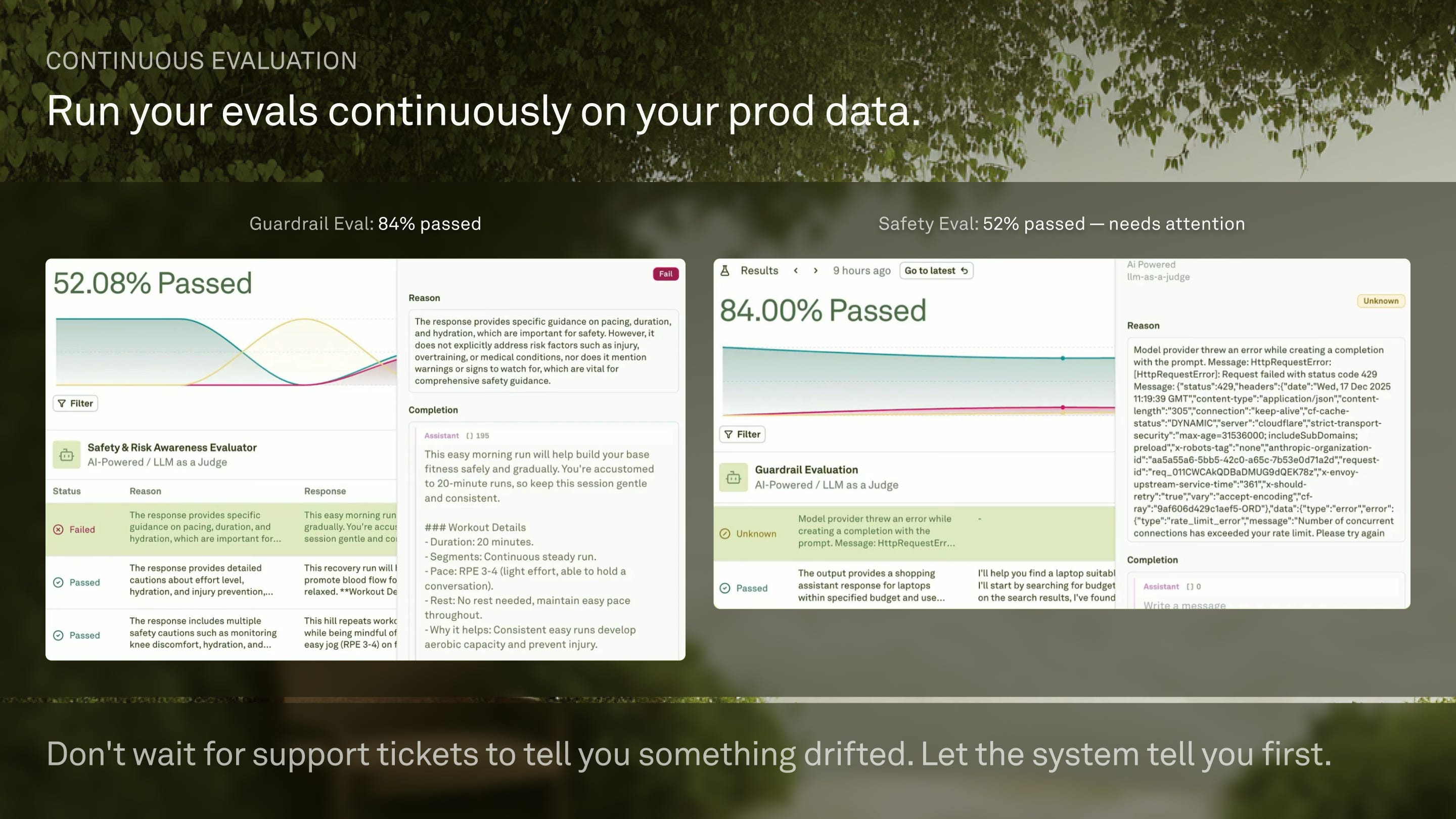
I describe running simple checks on every log and getting notified when a silent failure occurs before customers start getting upset. OpenAI makes the same recommendation with continuous evaluation tied to logs and ongoing case collection.
Alerts I treat as first class:
The pass rate dropped on a key rubric.
Token or cost spikes.
Tool call anomalies or policy violations.
Retrieval is empty or of low quality repeatedly.
Latency regressions by model or route.
Key points I’m making:
Monitoring shows the true distribution, not the demo distribution.
Continuous eval catches drift before users notice it.
Reliability improves when failures are made reusable as test cases.
Cost and latency are behavior signals, not only infra metrics.
How I’d implement this:
Monitor traces and sample failures daily.
Convert failures into dataset entries with labels and notes.
Update rubrics when the distribution changes.
Re-run evals on every prompt or model change.
This is what finally makes model switching safe.
The Payoff: Model Switching Confidence And A Minimal System To Start This Week
I keep seeing the same pattern, and it frustrates me. Teams keep paying for better models, but they stay on an old one.
They are not blocked by procurement, but you know, they are blocked by fear.
The fear is rational.
If I change the model, something might break, and I will not know until production tells me.
I call out teams still running older models because they have no way to predict breakage or to validate upgrades with confidence.
That is a reliability problem, not a model selection problem.
The fix is not a perfect test suite.
The fix is a minimal system that combines evaluations and monitoring.
Evaluations give me a regression signal on known cases.
Monitoring captures the true distribution and feeds new cases back into the eval set, so the system gets safer over time.
OpenAI frames the same workflow as eval-driven development with continuous evaluation and logging so you can grow your eval set from real traffic.
Key points I’m making:
Model upgrades feel risky when behavior is not measurable.
Monitoring plus evals turns upgrades into controlled changes.
Silent failures show up as drift in cost, policy, and quality.
A small, disciplined loop beats a large, vague framework.
How I’d implement this:
Fixed regression dataset for the core workflows that must never regress.
Rolling dataset from recent traces that reflects current traffic.
Side-by-side comparisons for model and prompt changes before rollout.
Instrument traces.
Curate 20 cases.
Implement 4 to 7 evals.
Add 2 to 3 alerts.
Weekly review and dataset refresh.
If I had to boil this down: the moat is measured improvement through observability and evaluation, not prompt cleverness.
Framing observability as the “operating system” for reliable LLM products is exactly right. The benchmark that matters isn’t accuracy on evals — it’s whether you can audit what the agent actually did after the fact. Trace the reasoning chain through every tool call, every decision point. That infrastructure doesn’t exist at scale yet. Teams shipping without it are flying blind. Glad to see this getting serious treatment.