
AI Product Manager 101 (2025): A Practical, Lesson-Based Guide to Building With LLMs
I explain the role, evaluation playbook, context engineering, vibe coding, and the tools that make AI PMs effective in 2025.


Who is an AI Product Manager?
An AI Product Manager aligns user problems, business goals, and model capabilities to ship reliable AI features end to end. They bring together product, data, and engineering values while managing risk throughout the lifecycle.
In a more simplistic manner, AI PM possesses the users’ mindset and aligns the product to fit their needs and product value or mission.
Why Prompts Matter?
Prompts are the interface to LLMs. They express role, task, constraints, evidence, and output format. Clear, contextual prompts reduce variance and make behavior testable; both OpenAI and Anthropic frame prompt quality as the primary control surface before model or finetune changes.
Prompt engineering, combined with domain or product expertise and users’ feedback, is the number one skill needed to align models with users.
AI PM vs. Traditional PM
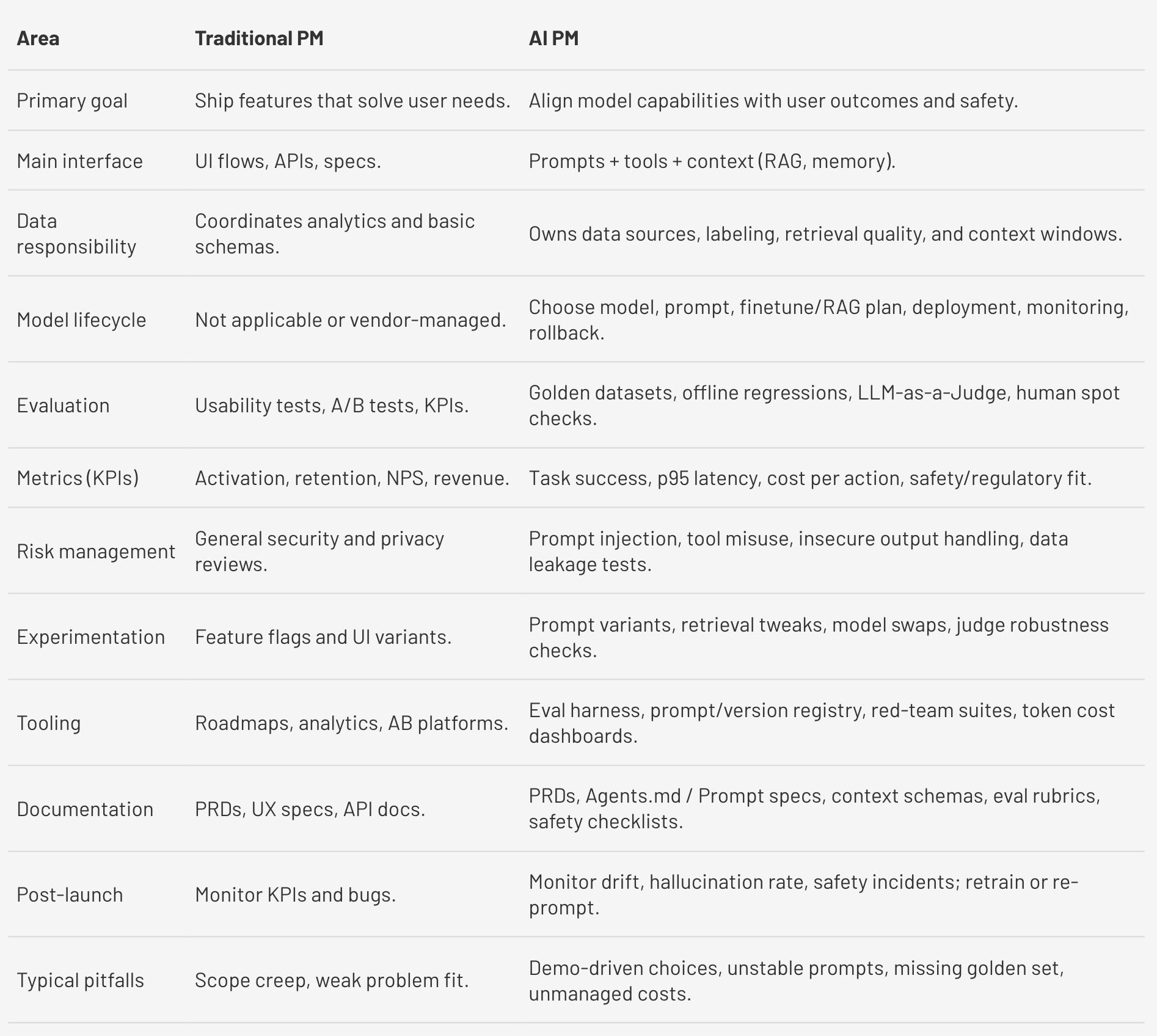
Now, let's go through three brief lessons that will help you understand how to become an effective AI PM.
Lesson 1: Prompt Engineering for AI PMs
You must learn to treat prompts like product or product specs and interface. This is important.
A good prompt sets role, task, constraints, tools, and success criteria. Strong prompts reduce variance, lower costs, and shorten time to value.
How you should write prompts that ship:
Cultivate the mindset of a user. Start by spending time reading through the users’ requests, needs, and desires.
Reiterate your understanding of the product. Understand where your product fails and passes.
Frame the job to be done. State the user, task, desired output shape, and failure modes you care about.
Constrained by evidence. Provide snippets, schemas, or tool hints so the model grounds its answer.
Make success testable. Add acceptance criteria, examples, and a rubric that the output must satisfy.
Plan for iteration. Log misses, compare variants, and keep a changelog tied to eval results.
Let models help you write prompts
AI models are becoming better and better. Models like GPT-5 “thinking” have a good understanding of human requirements and can frame your needs with clarity.
Try using a strong model like GPT-5 “thinking” to draft a first prompt. Ensure that you provide all the constraints and requirements.
This works because modern toolchains actively use multi-agent patterns and prompt-improvers, so models see plenty of high-quality examples and can propose structured drafts that I refine.
Anthropic’s Claude Code documents sub-agent usage explicitly, and Anthropic reports that multi-agent setups outperform single agents on internal evals by ~90% for research tasks. That makes “model-assisted prompt design” practical for PMs moving fast.
Evaluate prompts like a PM, not a hobbyist
Once your prompt is ready, validate it on a golden dataset that mirrors your product’s edge cases, domains, and formats. The golden set is like a regression suite. It allows to quantify task success, spot regressions, and compare prompt or model changes apples to apples. Multiple teams describe this methodology as the building block of stable LLM evaluation.
LLM-as-a-Judge, with safeguards
For open-ended tasks, use LLM-as-a-Judge to score outputs against the rubric. Then, blind, shuffle, and cross-check with a different judge or a human sample to reduce bias.
Recent surveys and studies highlight variance, position bias, and scoring bias, and they offer mitigation tactics that are easy to operationalize in a PM workflow. Try combining:
Randomized order, and majority voting across judges. Ensure a small, periodic human audit to recalibrate the rubric.
Correlation checks against public judge benchmarks when possible. This will keep evals fast while staying honest.
Security and robustness: prompt-injection tests
This is important; include prompt-injection and jailbreak tests in the eval loop. Read the OWASP Foundation PDF to get a better understanding of the prompt injection test.
So, a general and minimal prompt-evaluation checklist should look like this:
The Golden dataset covers happy paths, long-tail edge cases, and adversarial inputs.
LLM-as-a-Judge with blinding, shuffling, and periodic human audits.
Latency and token-cost budgets are defined per flow and enforced in CI.
Prompt-injection red team with pass/fail gates before production.
Lesson 2: Context Engineering and Vibe Coding
Prompting is necessary. Context engineering is what makes prompting reliable at scale. It involves designing how facts, memory, and tools flow into the model so that answers remain grounded, fast, and cost-effective.
What is context engineering?
A recent 2025 survey formalizes the field:
Retrieve or generate the right context
Process it for long sequences and structure
Manage memory and compression across the system.
In practice, this means investing in RAG quality, context processing (including chunking, schemas, and summarization), and memory hierarchies, so the model sees the right facts at the right time. The survey also lays out evaluation patterns for component-level and system-level testing, which I mirror in my roadmap.
When should you incorporate context engineering?
Knowledge depth matters. Answers must cite policy, docs, or code lines reliably.
Scale pressures. Long contexts, multi-file reasoning, and cross-tool workflows need structure.
Cost control. Good retrieval and compression cut token spend while improving precision.
Safety. Structured context and tool-calling reduce hallucinations and overreach.
How to build it?
Retrieval: Start by defining schemas, chunking rules, and ranking signals. Test recall and precision against golden set.
Processing: Normalize formats, resolve entities, and compress with task-aware summaries.
Management: Implement short-term vs long-term memory, eviction policies, and per-task context templates.
Evaluation: I measure answer faithfulness, citation coverage, and drift over time, as the survey recommends
Where does vibe coding fit?
Vibe coding is the rapid, natural-language way to build small tools by describing what you want, then iterating. It is good for prototypes and personal app building. Lenny Rachitsky’s piece compiles 50+ real examples, noting that tools like Cursor, Claude Code, Replit, Lovable, v0, and Windsurf dominate these fast loops.
How to vibe code?
Start with vibe coding when the goal is discovery, UX feel, or stakeholder demos.
Graduate to context engineering when you need reliability, compliance, citations, or hand-offs to engineering.
Combine both by using agentic coding tools with sub-agents and project context files (CLAUDE.md, AGENTS.md) to preserve fast iteration while adding structure. Check out Anthropic’s best practices that describe these patterns clearly.
With these two lessons, you can ship features faster without sacrificing reliability. Next, I’ll tie them into your Section 3 on tools and workflows, so the whole stack feels cohesive across prompting, context, and coding.
Lesson 3: The AI PM’s Coding Toolkit
Treat your workflow as a system of cooperating agents. Define roles, guardrails, and hand-offs up front, then let tools execute.
A lightweight Agents.md (plus CLAUDE.md if you use Claude Code) gives agents a single source of truth for setup commands, coding style, test strategy, and permissions. Store it in the repo root and keep it short; expand as the project matures.
Wire agents to real data and actions. Use the Model Context Protocol (MCP) to connect models to files, databases, and services without bespoke glue. MCP standardizes tool access, so you can swap models while keeping the integration layer stable.
OpenAI Codex / GPT-5
When you want a single agent that spans IDE, terminal, and front-end generation, lean on OpenAI’s latest coding models. GPT-5 shows clear gains in multi-file debugging and aesthetically coherent UI code, which shortens iteration from prompt to working screen. Use it for prototypes or complex refactorings where planning is crucial.
Anthropic’s Claude Code
Choose Claude Code for terminal-first, agentic development with durable project memory. Pair it with a repo-level CLAUDE.md to manage memory on the go, encode conventions, and recurring tasks.Claude reads and follows those guidelines as it edits, tests, and runs commands.
You can use it to create multiple branches and test different features at once.
Cursor
Use Cursor when you need Agent Mode to plan, edit multiple files, run commands, and repair errors while you stay in control. It’s strong for refactors, test-fix loops, and “make this change across services” requests directly.
Lovable
Reach for Lovable to turn plain-English specs into deployable full-stack apps fast. It’s ideal for MVPs and internal tools, with one-click deployments and GitHub sync..
Vercel v0
Use v0 to generate production-ready React interfaces using Tailwind and shadcn/ui, then paste code straight into your repo. shadcn even lets you “Open in v0” from any component for natural-language customization before export.
Your playbook
Create Agents.md / CLAUDE.md with setup, style, tests, and permissions.
Connect tools via MCP; scope permissions to least privilege.
Match the tool to the job: GPT-5 for broad coding and UI, Claude Code for terminal-first agents, Cursor for repo-wide edits, Lovable for MVPs, v0 for fast UI.
Closing
You now have a playbook. Emphasise on “possessing the users’ mindset to align the product to fit their needs and product value or mission.”And prompts can help you achieve that.
Treat prompts as a product, interface, and spec. The prompts should define role, task, constraints, evidence, and success criteria. Use models like GPT-5 to write prompts for you because they will not contradict instructions.
Validate the prompt with a golden dataset, LLM as a judge, human audits, latency, token budgets, and prompt injection tests.
Additionally, spend time understanding the reasons behind the product's failure. Why? It will help you come up with evaluation criteria.
Use context engineering for grounding and cost control; use vibe coding for discovery and prototyping. Operationalize with Agents.md or CLAUDE.md, connect capabilities through MCP, and keep permissions minimal.
Pick tools deliberately: GPT 5, Claude Code, Cursor, Windsurf, Lovable, v0. Track task success, failure patterns, and costs, then iterate prompts and context with discipline over time.