
Claude Code vs OpenAI Codex: Choosing Autonomous Agents for Production Velocity
A practical comparison of Claude Code and OpenAI Codex for real engineering workflows, long-horizon tasks, code review loops, and team adoption.

Updated: 21 April 2026
TLDR: Claude Code and OpenAI Codex are both pushing coding agents closer to real software work, but they are not interchangeable. The better choice depends on how your team works: planning-heavy implementation, iterative code review, long-horizon repository tasks, cost control, or developer experience.
This guide compares Claude Code and OpenAI Codex across the areas that actually matter in production: workflow fit, autonomy, code quality, iteration loops, efficiency, and team adoption. The goal is not to crown a universal winner, but to help engineering teams choose the tool that best fits how they build.

Claude Code vs OpenAI Codex at a Glance
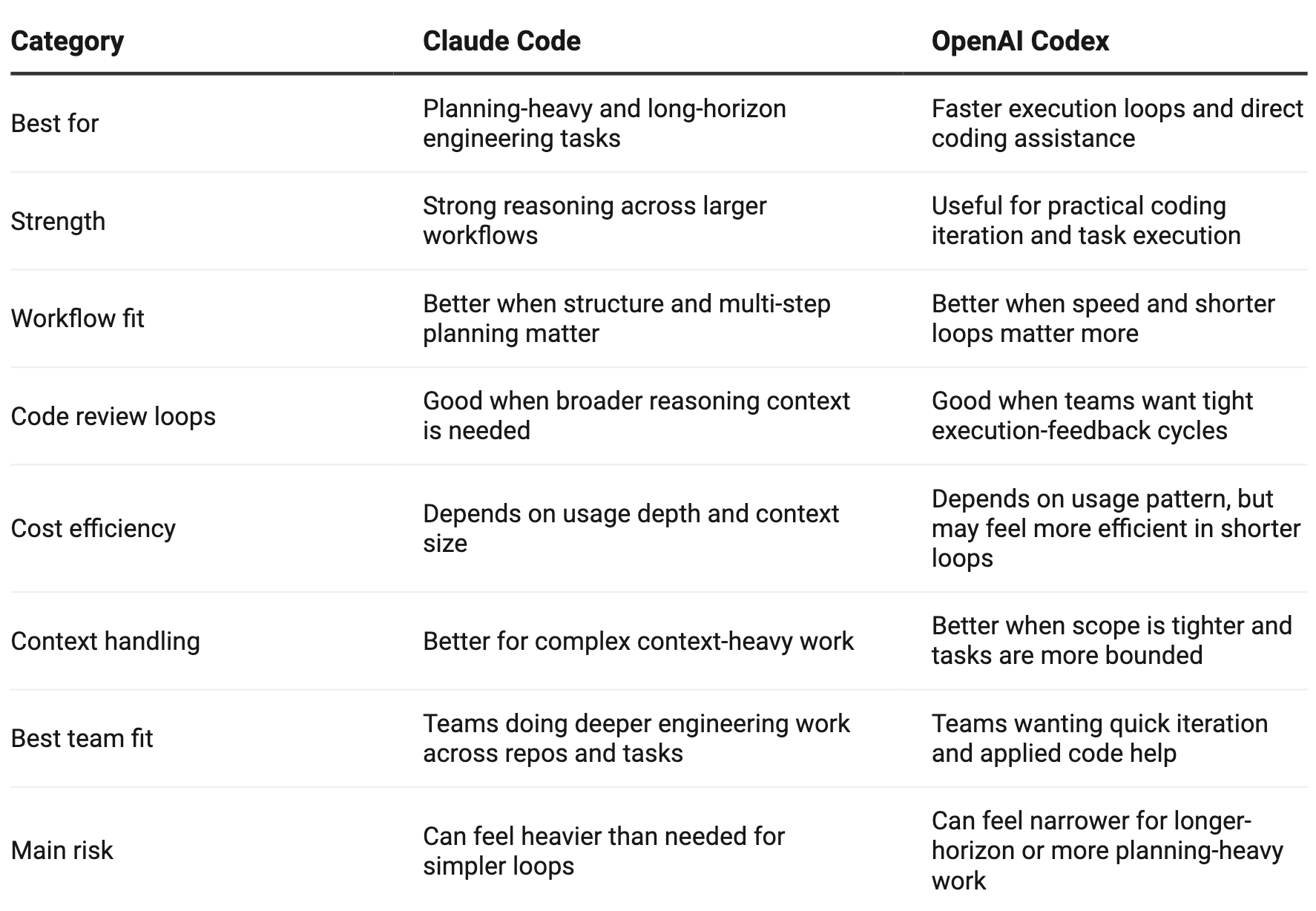
What’s the Difference Between Claude Code and OpenAI Codex?
The main difference is not that one is “good” and the other is “bad.” The difference is where each tool feels stronger in real engineering use.
Claude Code is more compelling when the work benefits from broader reasoning, longer context windows, and more structured planning across multi-step tasks. OpenAI Codex is more compelling when teams want fast iteration, tighter execution loops, and a coding assistant that fits directly into shorter feedback cycles.
In practice, most teams should not ask which tool is better in the abstract. They should ask which tool is better for their workflow, codebase complexity, review culture, and delivery constraints.
Which is Better for Real Engineering Workflows?
For real engineering workflows, the answer depends on the type of work your team does most often.
If your team spends a lot of time on multi-step implementation, broader repo reasoning, and tasks where planning quality affects downstream execution, Claude Code may be the better fit. If your team values faster execution, frequent iteration, and a tighter loop between instruction and code output, OpenAI Codex may be the better fit.
This distinction matters because coding agents are not only judged by whether they can generate code. They are judged by how well they fit the way engineers actually work: understanding context, adapting to constraints, handling review loops, and staying useful across more than one prompt.
From Code Completion to Autonomous Product Work
To begin with, let’s examine how coding agents evolved from autocomplete tools to autonomous systems. Systems capable of handling multi-week projects, and what this transformation means for product development velocity.
Coding tools evolved from 2021’s single-line suggestions to 2025’s project-scale autonomy. This scale in development and evolution represents a fundamental change in how software is built. GitHub Copilot launched in 2021 as an autocomplete assistant. It predicted the next line. Sometimes, the next function kept developers in control.
That era ended.
Claude Code and OpenAI Codex now run autonomous sessions spanning weeks. Cursor documented agents operating for “3+ weeks,” writing over 1 million lines of code on a single project. One agent migrated an entire codebase from Solid to React—266,000 additions, 193,000 deletions—without human intervention between checkpoints. That’s huge. This came at the beginning of 2026, while 2025 showed great promise of LLMs with agentic capabilities for long-horizon tasks.
Multi-agent coordination scales further. Cursor’s infrastructure supports “hundreds of concurrent agents” working in parallel on the same repository. The team built a browser from scratch. Another constructed a Windows 7 emulator containing 1.2 million lines of code. These aren’t prototypes—they’re production systems. Imagine you can essentially create an operating system.
The velocity gains show up in deployment metrics. Anthropic’s Security Engineering team reports that stack trace analysis, which “typically takes 10-15 minutes of manual scanning now resolves 3x as quickly.” Cursor shipped a 25x video rendering optimization to production after an agent identified and implemented the improvement.
This is a monumental product scaling that isn’t incremental. These systems handle “projects that typically take human teams months to complete.” Product teams no longer wait quarters for infrastructure refactors or migrations. Agents compress months into weeks, weeks into days.
What changed here is the scope. Agents graduated from line-level assistance to project-level execution.
Model Capabilities for Product Development
Now, let’s compare how Claude Opus 4.5 and GPT-5.2 Codex perform on real software engineering tasks. We will also be examining benchmarks, context windows, and behavioral differences that affect feature implementation and technical debt reduction.
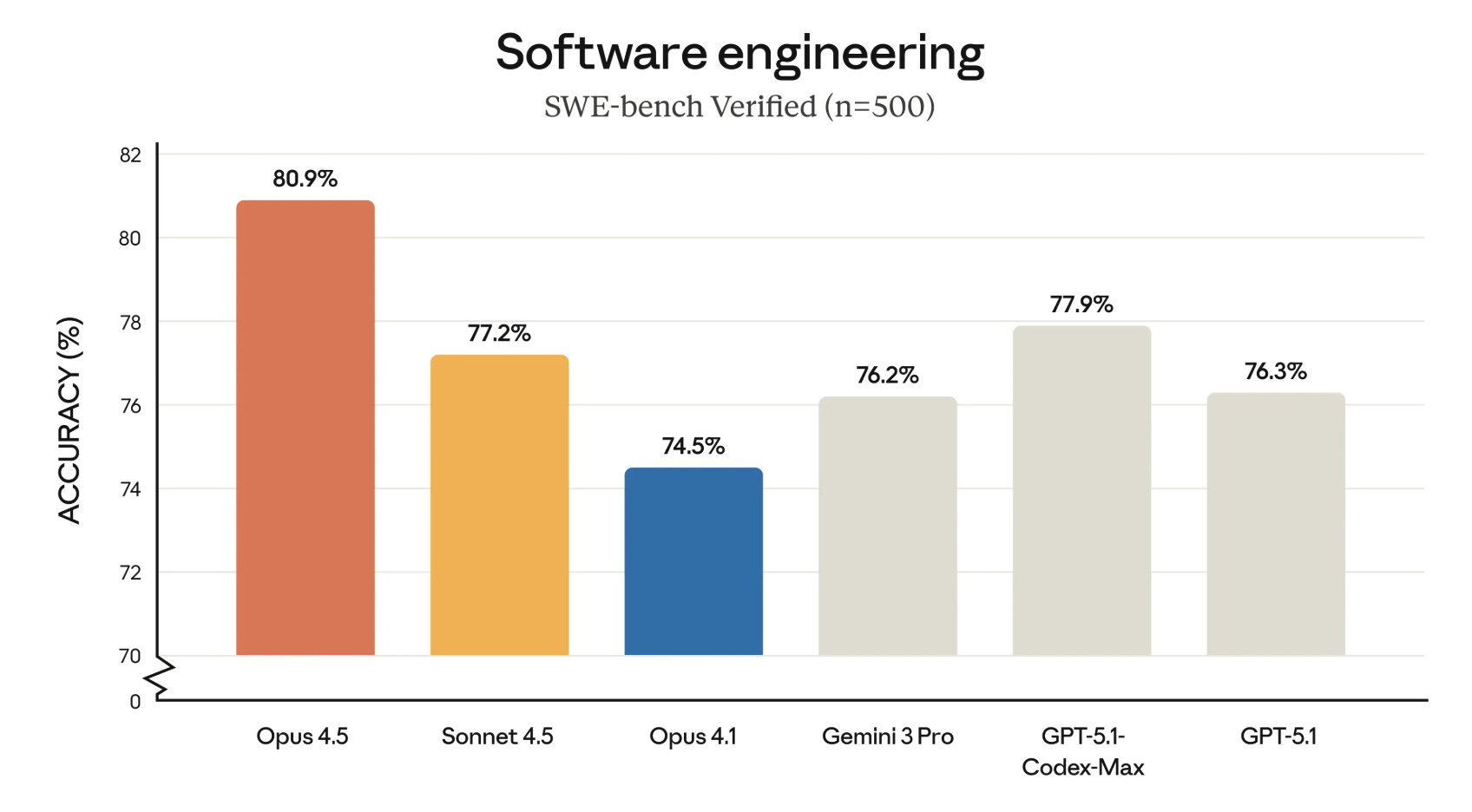
The performance gap is narrow at the top but diverges on specific workloads.
Both models exceed 80% on SWE-bench Verified, the closest proxy for real bug resolution. For a broader model comparison including architecture and reasoning differences, see Claude Opus 4.6 vs GPT-5.3 Codex.
Claude Opus 4.5 scores 80.9%; GPT-5.2 Codex reaches 80.0%. At this threshold, the difference rarely matters for feature work.
The differences widen in infrastructure tasks. Terminal-Bench measures command-line DevOps workflows—the territory of deployments, migrations, and system administration. Claude achieves 59.3%, while Codex achieves 47.6%. For teams heavy on infrastructure, that 11.7 percentage point advantage is decisive.
Context windows favor different use cases. Claude offers 200K to 1M tokens, enabling work across massive codebases without the need for summarization. Codex provides 400K tokens but compensates with “context compaction” that maintains coherence across longer sessions.
Behavioral patterns diverge under pressure. Cursor’s team observed that GPT-5.2 excels at “following instructions, keeping focus,” while Opus 4.5 “stops earlier and takes shortcuts when convenient.” This matters when agents run unsupervised for days—one persists, the other optimizes.
Token efficiency tilts toward Codex. Identical TypeScript tasks consume 72,579 tokens with Codex versus 234,772 with Claude—a 3x difference that compounds at scale.
Production deployments reflect these tradeoffs. Claude runs “831+ tests” in documented workflows. Codex coordinates “hundreds of workers” with “minimal conflicts” on parallel infrastructure.
Choose based on the bottleneck.
Infrastructure-heavy: Claude Code.
Cost-sensitive at scale: Codex.
Complex feature work: either exceeds human parity.
Product Engineering Workflows
This section examines how autonomous agents integrate into standard engineering workflows. Essentially, from sprint planning to PR automation to cross-functional collaboration. Also, what new coordination patterns do teams need to adopt? Integration isn’t seamless; it requires deliberate orchestration.
Sprint planning now includes non-human assignees. Teams assign GitHub issues directly to @claude for autonomous implementation. For a structured delivery protocol around this, see how to ship reliably with Claude Code.
Codex follows similar patterns through issue assignment workflows. The agent picks up the ticket, implements the feature, runs tests, and opens a PR; no standup required.
PR automation extends beyond code generation. Claude’s GitHub App handles code review, security analysis using OWASP alignment, and automated test generation. Codex provides comparable GitHub integration with organization-wide review configuration. The result is that PRs arrive pre-vetted.
Scale reveals coordination challenges. Cursor documented a Solid-to-React migration generating +266,000/-193,000 line changes that the team “believed possible to merge.” But flat agent structures produced “risk-averse” behavior—agents afraid to break things. The solution is to implement planner/worker separation, with specialized agents coordinating rather than competing.
Hundreds of concurrent workers now “push to the same branch with minimal conflicts” through explicit coordination protocols. This is an architectural discipline.
IDE and CLI workflows diverge by tool. Codex supports broader IDE coverage across Visual Studio, Xcode, and Eclipse. For a walkthrough of Claude Code as a day-to-day tool, see Claude Code for productivity workflows.
Claude focuses on VS Code and JetBrains with terminal-native operation. Cursor demonstrated multi-agent coordination at scale, while Codex offers dedicated CLI tooling.
Cross-functional adoption expands beyond engineering. Anthropic’s internal teams use Claude Code for legal memo drafting, marketing copy generation, and data visualization— “without knowing JavaScript.” Documentation generation happens automatically: README updates, changelog creation, API docs.
Production merges validate the approach. Cursor shipped a Rust video rendering optimization with “smooth spring transitions and motion blurs” directly to users. The agent identified the bottleneck, implemented the fix, and delivered 25x performance gains.
The workflow works. The coordination patterns are still forming.
Cost, Efficiency, and Practical Tradeoffs
Cost matters, but not only in the narrow sense of per-token usage. The real cost of a coding agent includes how much context it needs, how often it needs correction, and how efficiently it helps a team move through implementation and review.
A tool that looks cheaper at first can become more expensive if it creates more rework, weaker planning, or extra review overhead. A tool that seems heavier can still be the better choice if it reduces mistakes, improves continuity, or handles larger workflows more effectively.
Organizations also need more than subscription math. Claude Pro costs $20 per month, and Claude Max runs $100 to $200 per month for Opus 4.5 access. But once teams run larger autonomous workflows, the meaningful metric becomes cost per useful output: cost per commit, cost per PR, and cost per unit of engineering work completed without rework.
One analysis estimated $37.50 per incremental PR, with roughly 4:1 ROI when each PR saves two hours at $75 per developer hour. The point is not that every team will replicate that number. The point is that teams need measurement infrastructure. Without it, cost conversations stay anecdotal.
Engineering teams should evaluate Claude Code and OpenAI Codex not only on direct model cost, but on total workflow efficiency.
Code Review and Iteration Loops
Code generation is only one part of real engineering work. Most teams also need coding agents to participate in review loops, respond to feedback, revise output, and stay useful when the first answer is not enough.
OpenAI Codex may be a better fit for teams that want tighter iteration loops and fast response cycles during coding and revision. Claude Code may be a better fit when review requires more context, deeper reasoning, or stronger continuity across multiple steps.
This distinction matters because the best coding agent is not the one that looks best in a single pass. It is the one that stays useful when engineering work becomes iterative, collaborative, and messy.
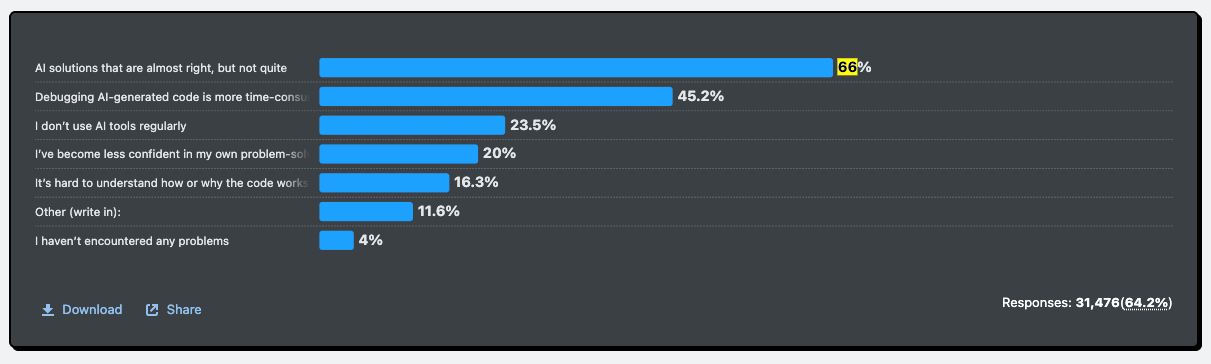
The 2025 Stack Overflow survey made the problem visible. Sixty-six percent of developers reported frustration with AI solutions that were almost right. Forty-five percent said debugging AI-generated code took longer than writing it themselves.
That is the real risk.
The model may write more code, but the team may still lose time if review quality, correction cycles, and debugging overhead all increase downstream.
Quality gaps do not close only through better models. They close through better orchestration, better checkpoints, and better quality controls around the agent.
Quality and Reliability Trade-offs
What are the quality challenges teams face when deploying autonomous agents? Here is the list: debugging AI-generated code, managing test coverage, and understanding new failure modes that emerge at scale. Velocity gains come with new reliability costs.
The 2025 Stack Overflow survey quantified the problem. 66% of developers report frustration with “AI solutions that are almost right”—code that compiles but requires significant rework. The debugging paradox compounds this: 45% say debugging AI-generated code takes longer than writing it themselves.
Multi-agent systems reveal coordination antipatterns. Cursor’s team removed the “integrator” role after finding it added complexity without improving outcomes. Better solution: “workers capable of handling conflicts themselves.” Centralized review created bottlenecks. Distributed autonomy scaled.
Model behavior differs under sustained load. GPT-5.2 excels at “following instructions, avoiding drift” during long sessions. Opus 4.5 “yields back control quickly,” which helps for iterative workflows but hurts for marathon tasks.
Context degradation is real. Claude exhibits quality issues in the final 20% of its context window—forgetting earlier files, repeating corrected mistakes. This is part of a broader pattern called context rot, where longer prompts produce increasingly unreliable outputs.
“Agents occasionally run for far too long. We still need periodic fresh starts to combat drift and tunnel vision.” — Cursor
Context isn’t infinite even when the window is.
Failure modes emerge at scale. Agents run “far too long” without progress checkpoints. Coordination bottlenecks appear when hundreds of workers contend for the same files. Lock contention crashes systems. These aren’t prompt engineering problems—they’re distributed systems problems.
Security improved through architecture. Claude Code’s sandboxing delivered an “84% reduction in permission prompts” by isolating filesystem and network access at the OS level. Approval fatigue kills security. Automation prevents it.
The quality gap isn’t closing through better models. It’s closing through better orchestration, checkpointing, and sandbox isolation. Treat agents like distributed systems, not magic.
Team Adoption and Productivity Impact
Let’s examine the productivity paradox facing teams:
Individual developers show dramatic output gains, but organizational metrics remain flat
The specific friction points and measurement challenges teams encounter.
The gap between personal velocity and team throughput reveals what actually constrains software delivery.
Developer adoption reached saturation. 84% of developers use or plan to use AI coding tools. Yet trust declined sharply: only 33% trust AI code accuracy, while 46% actively distrust it. The numbers are down from over 70% in 2023-2024.
The productivity paradox manifests in metrics. Individual developers complete 21% more tasks and merge 98% more PRs when using Claude Code. Organizational DORA metrics remain unchanged. Why? Bottlenecks shifted.
Code generation accelerated, but review times increased 91%. Agents write code faster than humans can review it. The constraint moved downstream.
Rate limiting creates operational friction. Claude’s 5-hour rolling windows allow 10-40 prompts on Pro, 200-800 on Max. Power users hit ceilings mid-sprint. Codex’s monthly premium quotas feel more predictable but cap heavy usage.
Cost transparency requires infrastructure. One analysis calculated $37.50 per incremental PR, yielding a 4:1 ROI when each PR saves 2 hours at a $75/hour developer cost. Organizations making six-figure agent investments lack observability into how token consumption connects to commits and PRs.
Prompt engineering emerged as the critical skill. Cursor found that “the harness and models matter, but the prompts matter more” for multi-agent coordination. Bad prompts waste thousands of tokens producing unusable code.
The measurement gap is the problem. Individual developers see gains. Organizations see flat metrics. The difference is that the bottlenecks moved to code review, testing, and deployment. Accelerating one stage without upgrading the pipeline doesn’t improve throughput.
Adoption without measurement yields an estimate, not velocity.
When Claude Code Is the Better Choice
Claude Code is the better choice when your team needs stronger performance on planning-heavy, context-rich, and long-horizon engineering tasks.
It is a better fit when:
Tasks require broader reasoning across multiple steps.
Repository context matters a lot.
Implementation depends on structured thinking before code generation.
Teams want stronger continuity across larger workflows.
If your engineering work is complex, layered, and context-heavy, Claude Code may be a more useful tool.
When OpenAI Codex Is the Better Choice
OpenAI Codex is the better choice when your team values faster execution, tighter iteration loops, and a more direct coding workflow.
It is a better fit when:
Tasks are more bounded.
Engineers want shorter instruction-to-output cycles.
The speed of iteration matters more than the depth of broader planning.
The workflow benefits from rapid feedback and direct code assistance.
If your team works in tight loops and wants practical coding help that fits directly into day-to-day execution, OpenAI Codex may be the better fit.
Selection Criteria for Product-Driven Organizations
This section provides a decision framework for choosing between Claude Code and OpenAI Codex based on project scale, token efficiency, organizational readiness, and other factors, not just model capabilities. The right choice depends on what constrains your team most.
Match Project Scale to Architecture
For complex multi-month projects requiring sustained autonomy, consider multi-agent architectures. Cursor’s research validates the feasibility of week-long autonomous runs without human intervention.
Persona-based Selection
AI engineers building ambitious projects: Use Claude Code.
Larger context windows (200K-1M tokens) enable work across massive codebases. Multi-agent experimentation benefits from Claude’s architectural flexibility.Product engineers shipping incremental features: Use OpenAI Codex.
Token efficiency matters at scale (3x more efficient: 72,579 vs 234,772 tokens on identical tasks). Sustained autonomous operation handles 24+ hour sessions without context degradation.
Cost Structures Differ
Claude Pro costs $20/month; Claude Max runs $100-200/month for Opus 4.5 access. Multi-agent projects consume billions of tokens. Model cost per commit matters more than subscription price.
Performance Splits by Workload
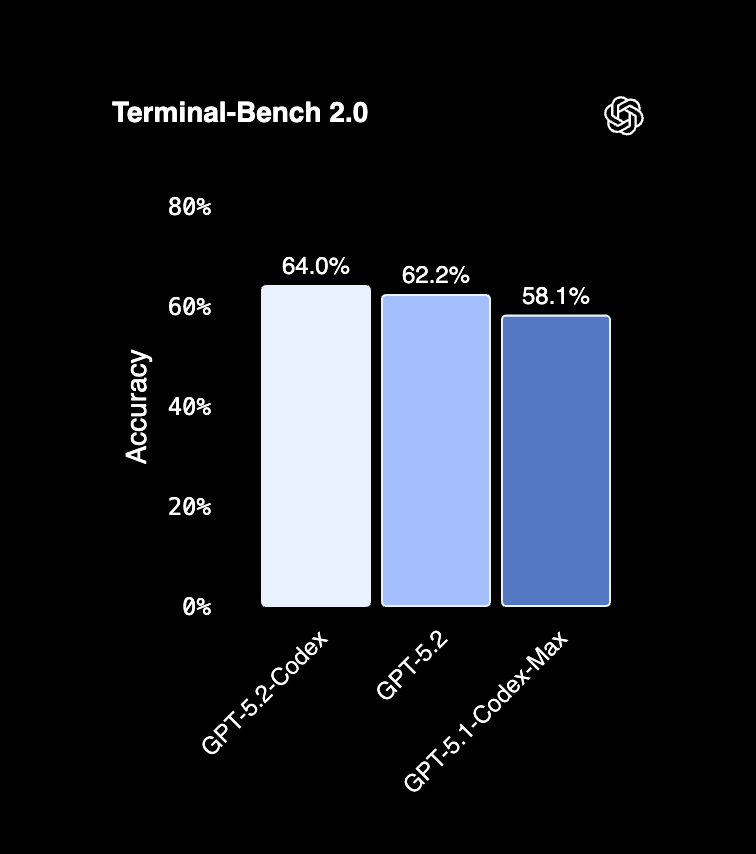
Claude Opus 4.5 leads SWE-bench (80.9%) while on Terminal-Bench, Codex leads with 64.0%. GPT-5.2 excels at extended autonomous work without drift.
Context Windows Favor Different Patterns
Claude’s 1M tokens versus Codex’s 400K with “context compaction.” Large monorepos need raw capacity. Long sessions need compaction.
Measure Before Scaling
Calculate cost per commit and cost per PR. Identify underused licenses. Run 30-day pilots with 5-10 developers. Conduct A/B tests with matched control groups (20-30 developers minimum) for one quarter.
Address Organizational Readiness
Upgrade code review processes, quality gates, and measurement infrastructure before deploying agents. Without these, bottlenecks shift downstream.
No single winner exists. Match your constraints to capabilities.
Quick Verdict
Choose Claude Code if your team needs stronger planning, broader context handling, and better support for long-horizon engineering work.
Choose OpenAI Codex if your team values speed, tighter coding loops, and more direct execution support.
Do not choose based only on benchmark excitement or general model reputation. Choose based on workflow fit, review patterns, and the kind of engineering work your team actually does.
Related: Model comparison gets you to a shortlist. Knowing how to evaluate that shortlist against your actual production requirements is the next step. The full evaluation framework lives here.

Conclusion
The transition from code completion to autonomous agents changed the constraints on software delivery.
Model capabilities converged. Claude Opus 4.5 scores 80.9% on SWE-bench; GPT-5.2 Codex reaches 80.0%. Both handle complex feature work. The differentiation emerges in specialization patterns: Claude’s 11.7 percentage point Terminal-Bench advantage matters for infrastructure teams. Codex’s 3x token efficiency matters at scale.
But velocity gains don’t translate to organizational throughput. Developers merge 98% more PRs. DORA metrics remain unchanged. The bottleneck shifted from code generation to code review, increasing the duration by 91%.
Success requires three pillars. Orchestration and checkpointing prevent agent drift during multi-day runs. Measurement frameworks track cost-per-PR and ROI, connecting token consumption to business value. Organizational readiness means upgraded review processes and quality gates that match agent output velocity.
The measurement gap reveals the constraint. Individual developers see gains. Organizations see flat metrics. The difference: infrastructure and workflow optimization, not model capabilities.
Adoption without measurement yields anecdotes. Measurement without infrastructure upgrades shifts bottlenecks downstream. Both problems are solvable through architecture, not prompt engineering.
Selection depends on what constrains your team. Regulatory requirements, project scale, token budgets, and organizational readiness determine fit. No single winner exists. Match constraints to capabilities, then build the supporting systems that turn agent velocity into organizational velocity.