
Coding with GPT-5 Codex
A practical guide to Agents.md, a small evaluation rubric, and why GPT-5-Codex Medium is ideal for fast development and prototyping.


OpenAI’s GPT-5 Codex landed on September 15, 2025, and it changes how we ship code.
So, what is GPT-5-Codex?
“GPT-5-Codex is a version of GPT-5 optimized for agentic coding in Codex.” — System Card.
For a side-by-side look at how it compares to Claude Code across benchmarks, cost, and workflow fit, see our Claude Code vs OpenAI Codex comparison.
It is not “chat that writes snippets.”
It is an agentic coder that reads your repo, runs tests, opens PRs, and stays in your toolchain. You get it in the VS Code extension, the Codex CLI, and Codex Cloud for longer asynchronous runs.
The table below shows the performance on the production benchmark.
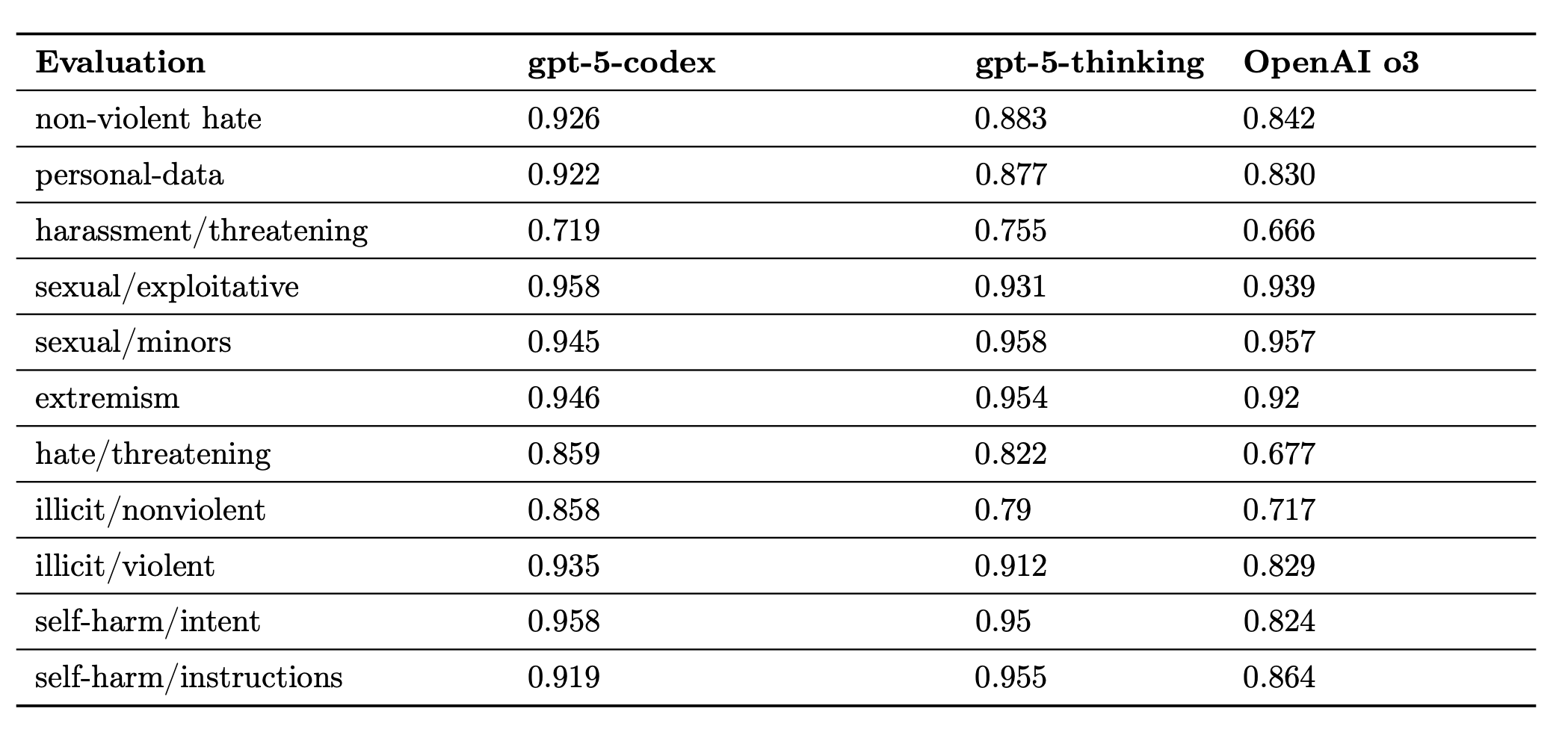
What is new is not only accuracy. It is the workflow.
The GPT-5 Codex now understands AGENTS.md, respects local instructions, and can run for long horizons to add features, refactor, and review. Latent Space’s breakdown captures the shift toward “agentic coding” and why developers are moving complex tasks from chat windows into the repo itself.
Put simply. The chat UI is great for ideation, even prototyping and brainstorming, but shipping means files, tests, and PRs. GPT-5 Codex operates natively in that world. So developers bring the model to the repo instead of dragging the repo to the chat.
Also, product managers can directly create a PR and make changes to align with the users’ feedback. They can also create multiple PRs and test which prompt or feature works best before they deploy it.
My rule as an engineer and product builder is simplily to “Optimize the loop.”
The chat UI is great for ideas, but copying code into an editor slows learning.
The GPT-5 Codex CLI keeps you in the project. If you prefer structured prompts and checklists, GPT-5 Codex reads them directly, so your intent travels with the codebase.
This guide teaches you the scaffold I use to make GPT-5 Codex reliable. We will put your rules in one file, and your expectations in one rubric. Then we will run the same tests every time and only promote changes when the data says they are ready.
Next up is the foundation you will reuse on every repo: AGENTs.md and a small evaluation rubric for GPT-5 Codex.
Setting Up AGENTS.md for GPT-5 Codex
AGENTS.md is a single markdown file that tells coding agents exactly how to build, test, and submit changes to your repo. Think of it as a machine-readable README that removes guesswork for GPT-5 Codex.
Most importantly, it aligns GPT-5 with your preferences, style, and ideologies. Essentially, you can transfer your coding soul to GPT-5 using the AGENTS.md file.
The official reference describes it as a “simple, open format for guiding coding agents,” and even includes a short starter file.

Some of the best practices that you will see in the real world are:
Set up commands that are short and copy-pasteable, e.g., install deps, start the dev server, run tests. The reference example uses patterns like pnpm install, pnpm dev, and pnpm test, plus quick tips for monorepos.
Testing and PR rules that make success measurable. These include how to run focused tests, what must be green before merge, and a tidy PR title format. These keep agents from shipping half-working code and allow you to ship with confidence.
Use proper heading tags to separate workflow instructions. Try to keep the h1 “#” for the main title and h2 “##” for different workflow – dependencies, coding best practices, lint, testing instructions, etc. Also, try to keep everything under h2 “##”; avoid any further hierarchy like h3 “###” because it may confuse the model.
Also, for more examples on how to set up the AGENTS.md file, check out this link here.
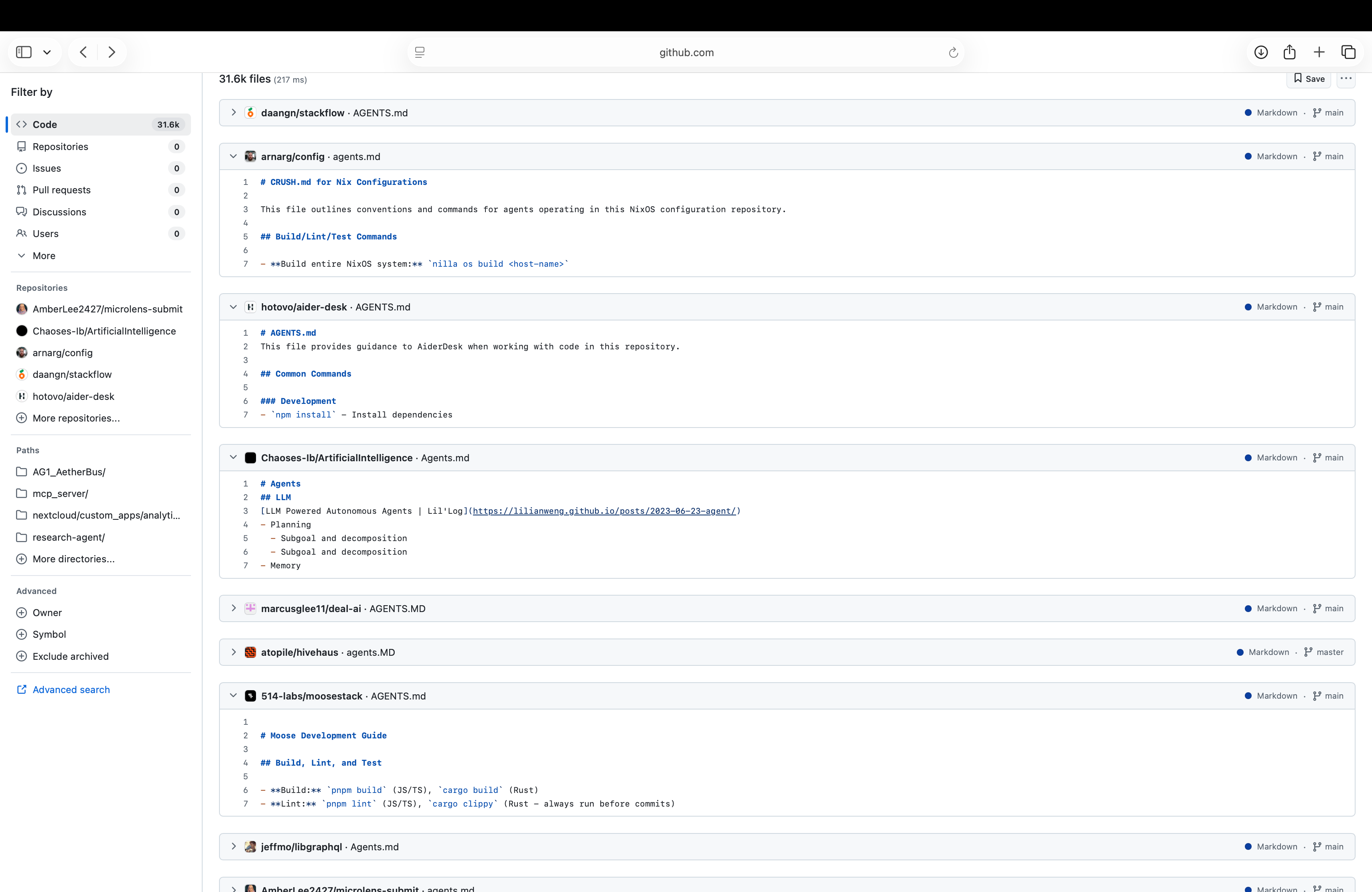
Benefits of using AGENTS.md:
You give Codex a single source of truth for build, test, lint, and PR workflow.
You reduce flaky behavior by replacing vibes with exact commands and pass criteria.
You can also plug in your rubric and eval dataset right into the file, so every run has the same gate.
For instance, this is how you can write an AGENTS.md file.
# GPT Finetuning Framework
## Dependencies
Ensure the following packages are installed before proceeding:
> PyTorch (>=2.0.0): Core deep learning framework for model training
> Huggingface Transformers (>=4.35.0): Pre-trained models and tokenizers
> Unsloth: Efficient finetuning library for memory optimization
> OpenAI SDK (>=1.0.0): API integration for evaluation metrics
> openai-harmony: Compatibility layer for seamless API interactions
`pip install torch transformers unsloth openai openai-harmony`
## Instructions
Setup Guidelines:
> Documentation First: Thoroughly review official documentation for each dependency to understand API changes and best practices
> Code Standards:
- Use tab spacing (not spaces) for indentation consistency
- Apply proper Python linting with pylint or flake8
- Follow PEP 8 style guidelines
> Implementation Requirements: Create comprehensive visualizations for:
- Model architecture diagrams
- Training/validation loss curves
- Learning rate schedules
- Attention weight heatmaps
- Implement robust training and validation loops with Gradient accumulation support, Mixed precision training, Checkpoint saving mechanisms, and Early stopping criteria.
> Security: Access API credentials from .env file only; never hardcode keys.Keep it brief, concrete, and next-action oriented. Your agent will do the rest.
Note: Once you keep using Codex, you will end up adding more instructions to the AGENTS.md file.
Build a Lightweight Evaluation Rubric with Golden Tests
You can also ask Codex to evaluate the LLM output to see if it matches certain criteria or a rubric.
Essentially, you will use evals to teach GPT-5 Codex what “good” looks like and to track if changes make it better or worse. Why is this important?
Now, if you are using Codex CLI, there is an option when you start of the session: “Allow Codex to work in this folder without asking for approval.”

This can be scary at times because GPT-5 Codex can literally sift through your code and make changes that may sometimes break the entire codebase.
But, if you really want to use option one and you also want the output to be good and effective, then you should use rubrics to evaluate the model’s outputs. Think of the rubric as a small checklist that the model must pass, and the golden tests as fixed examples you run every time.
You can start with something like this:
Write the prompt which has your own style of coding: “Create small functions for loading model weights, setting hyperparameters, and configuring tokenizer. Each function must be under 15 lines. Use tab spacing and ensure all functions are reusable.”
Show/write the type output that you like:
def load_model_weights(model_path): """Load pretrained weights from disk.""" if not Path(model_path).exists(): raise FileNotFoundError(f"Model not found: {model_path}") weights = torch.load(model_path, map_location='cpu') return weightsdef set_learning_rate(base_lr, warmup_steps, total_steps): """Calculate learning rate with warmup.""" if warmup_steps > total_steps: raise ValueError("Warmup steps exceed total steps") schedule = { 'base_lr': base_lr, 'warmup': warmup_steps, 'total': total_steps } return scheduleSave these examples to
evals/cases.jsonl
Ensure that you have 10-15 examples with proper prompts and outputs. You can then add the path of the eval file to AGENTS.md. It will make sure that the workflow goes through that funnel or gate.
Incorporate the rubric directly in AGENTS.md
You can also add the rubrics directly to the AGENTS.md file.
.
.
.
## Evaluation
Implement evaluation rubrics to the generated code:
evaluation_criteria = {
"code_quality": ["readability", "efficiency", "documentation"],
"model_performance": ["accuracy", "loss_convergence", "generalization"],
"best_practices": ["error_handling", "logging", "reproducibility"]
}Now, you can score the listed three buckets: code_quality, model_performance, best_practices – from 0 to 3 on each sub-point and compute a weighted total.
Add two hard stops: fail if safety or latency blows up.
Why GPT-5-codex Medium is best for quick builds and prototyping?
GPT-5-Codex Medium gives you the fastest learning loop. It’s the default reasoning level in Codex, tuned for short iteration cycles, while still being strong enough to follow schemas, respect Agents.md, call tools, and keep your repo green.

When you start using the new GPT-5 Codex, you can select the model of your choice.
To do that, just type /model and you can select the models you like.

By default, you will be given gpt-5-codex medium, which is the optimized variant of gpt-5 medium. Earlier you had only four models — gpt-5 minimal, gpt-5 low, gpt-5 medium, and gpt-5 high.
The current release showcases the three codex models — gpt-5-codex low, gpt-5-codex medium, and gpt-5-codex high.
Prior to the update, I was using GPT-5 medium, which was great, but I still needed to write rewrite prompts to get the desired output. But GPT-5 Codex medium is good at understanding my coding requirements, even if I am building a codebase from scratch, adding a new feature to the existing codebase, or if I am studying the codebase.
Codex Medium uses far fewer tokens on easy tasks, but spends more on hard ones, doubling output at the 90th percentile.
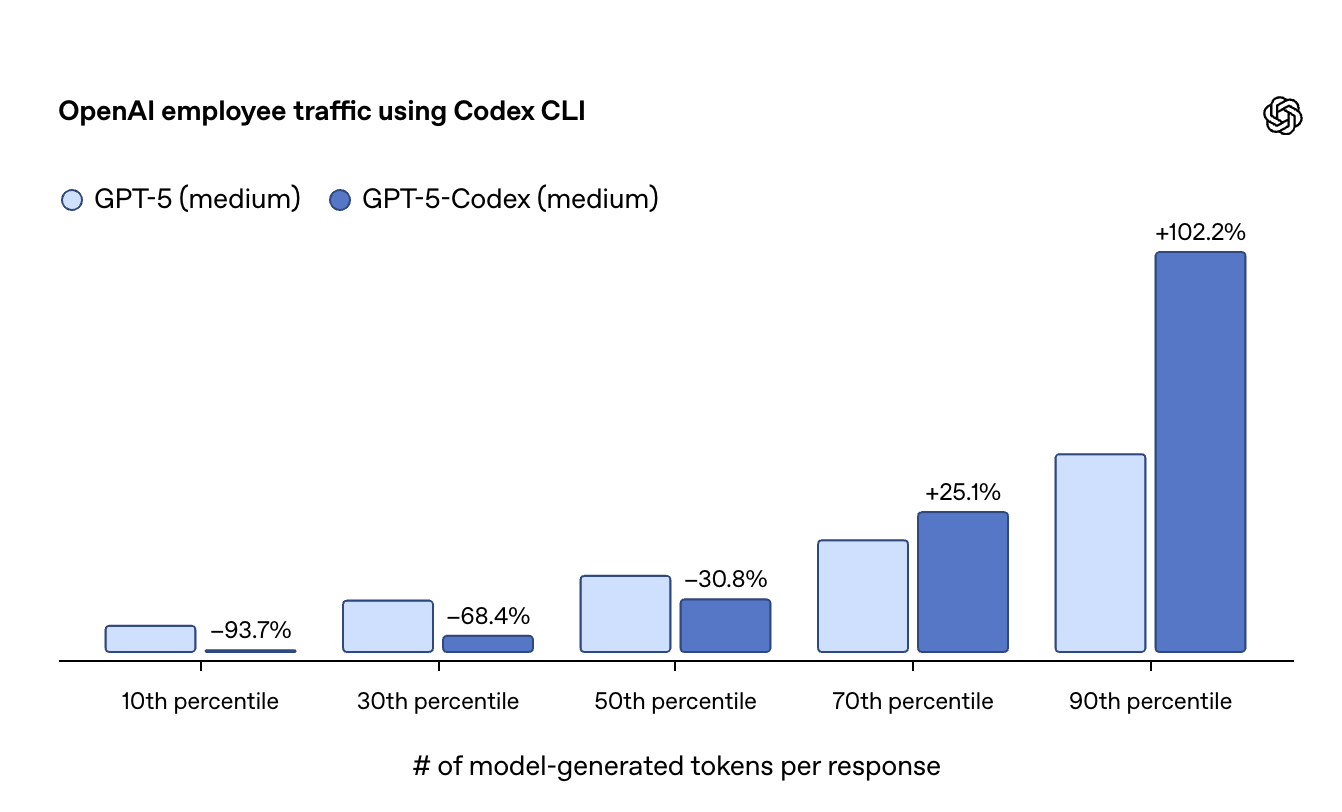
Because the GPT-5 Codex models are trained “specifically for conducting code reviews and finding critical flaws,” it is much more intuitive to you as a developer or product builder.
When it comes to usage, “Average users can send 30-150 messages every 5 hours with a weekly limit.” This Plus plan is great for product builders who generally spend an ample amount of time refreshing the feature or aligning it to the users’ needs. They don’t require extra usage.
But for developers who constantly spend time coding, they should use the Pro subscription to “send 300-1,500 messages every 5 hours with a weekly limit.”
The GPT-5-Codex Medium lets you run many more evaluations per hour at a cost that does not punish iteration. It all depends on your prompting skill. If you are clear and provide a narrow search path.
That matters because early work is mostly about shaping behavior. You will rewrite the prompt and refine the I/O schema several times. If each run is slow or expensive, you will simply run fewer experiments.
That’s why it is important to define the AGENTS.md as it will align the model to your specifications.
Related: Getting GPT-5 Codex working is step one. Building confidence that it works reliably at scale requires a structured evaluation. The full evaluation framework lives here: How To Evaluate Coding Agents In Production.

Closing
We will explore some practical examples in the next blog. But this is the starting point. The best practice is to start by properly defining AGENTS.md, defining rubrics for more aligned outputs from the model, and selecting best model for your use case.