
Comparing GPT-5, Claude Opus 4.1, Gemini 2.5, and Grok-4
A practical comparison of major LLMs for builders


Product building and prototyping have never been so efficient. With intelligent models at our fingertips, we can prompt features, design, ideas, and architecture, and get ourselves a working prototype in no time. These powerful models are helping us build reliably and ship faster.
Mid-2025 brought a wave of LLM launches. OpenAI dropped GPT-5 on August 7. xAI released Grok-4 in July. Google unveiled Gemini 2.5 Pro back in March. Anthropic followed with Claude 4.1 Opus on August 5. These models answer the call for faster coding in tight startup budgets.
They pack better reasoning and multimodal tools. Think about handling text, images, and code all at once. Costs dropped, too, making them fit for real workflows. Reddit buzzes with GPT-5's coding edge, users praising its speed in benchmarks and iterations, while a lot of them criticize it in a lot of fronts.
Some call GPT-5 a smart router, while some call it an over-hyped product with no real innovation. Some say it's the old models with a new label. And many agree that Claude 4.1 Opus leads for coding jobs.
These models are changing software and product creation. I see it as a key moment for efficient prototypes.
Read on. You’ll get clear picks for your needs. Plus strategies to blend them into builds.
Overcoming the LLM Selection Challenge
I often face this choice of picking the right LLM. For research, I will use deep research models, and for writing, I will use Claude Sonnet. But which one to use for coding and prototyping? It is a challenge.
Wrong choice, and your prototype drags, which eventually burns your pocket. You don’t want that. You want to use resources carefully but efficiently.
So start simple. Ask what you need most. I mean, take time to jot down your needs and just brainstorm ideas.
For coding, accuracy means producing the correct output the first time. Speed cuts wait times. Cost keeps budgets in check. Flexibility lets it fit your tools.
Take context windows. Gemini 2.5 handles 2 million tokens. That suits big codebases. But high token costs bite in prototypes. I balance that against inconsistent results.
Prototypes are like building small components without any complexity. They should convey your idea. Complexity comes in the later stages as you start growing by refining ideas and introducing new features. It also comes when you start onboarding new customers.
Product leaders chase ROI. Think shorter time to market. Engineers seek ease in vibe coding. Flow without fights.
Note: Don’t vibe code in a production environment. Use your coding skills as much as possible.
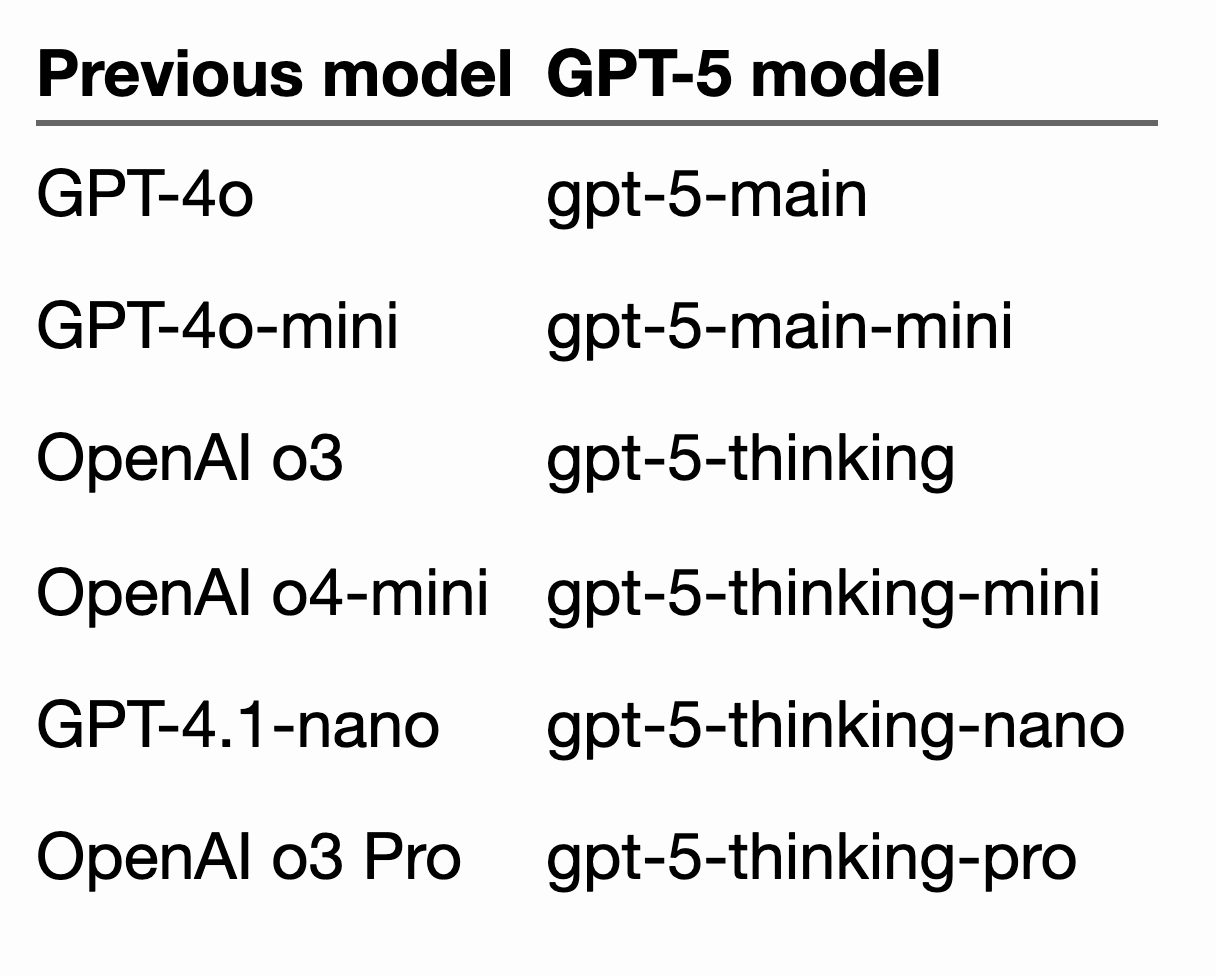
From Reddit, I have seen that users are preferring Claude Opus 4.1 for complex coding, where you want to understand the codebase, write new features, and find a way to optimize the codebase. GPT-5 is good for quick prototyping, day-to-day coding, and one-shot prompting. The former is expensive, while the latter is cheap.
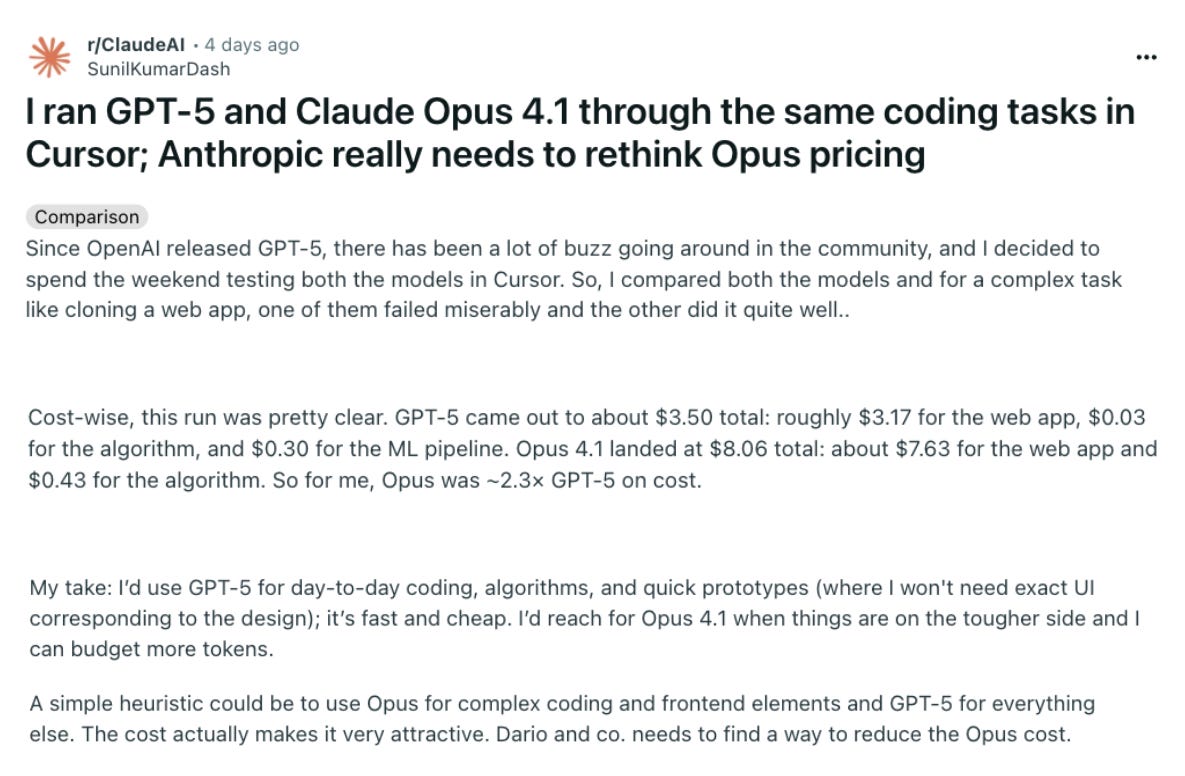
When it comes to Grok 4, it doesn’t shine much in coding. Not that it is bad, but it needs to find a way into the users’ coding arsenal. Look at the two posts; both are at the extreme end.

What about Gemini 2.5 Pro?
Well, it has a good context window (1M) compared to any other model. It is quick and cheap compared to Claude Opus 4.1 and better than GPT-5. It has an amazing tool for calling capability.
It’s not that the models are bad at coding; sometimes it is the prompt, token cost, your level of expectation, and your experience. At the most basic level, all the models have their own way of understanding prompts. The same prompts given to different models will produce different results.
I weigh these. Build a quick checklist. Match to your workflow. This frame helps you pick smart.
A Side-by-Side Analysis
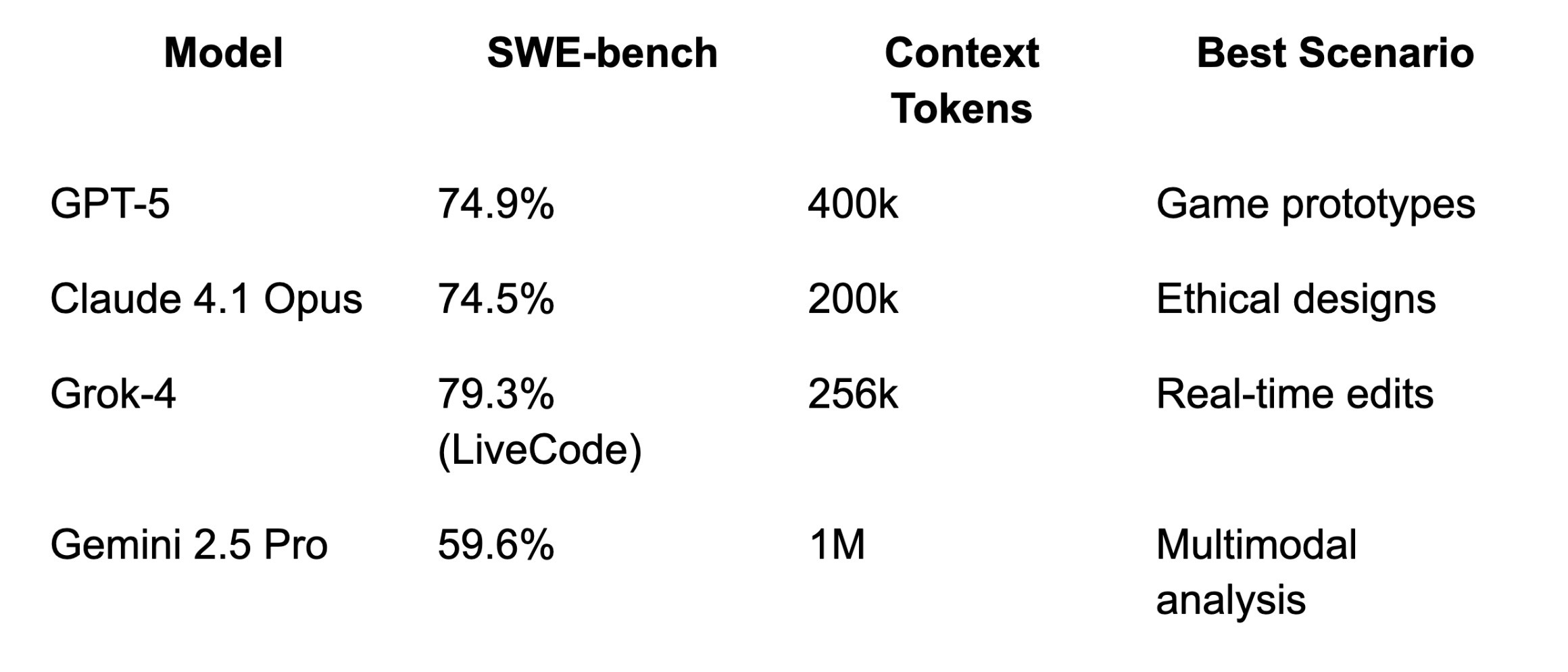
Look at SWE-bench scores first. GPT-5 hits 74.9 percent. Claude 4.1 Opus follows at 74.5 percent. Gemini 2.5 Pro scores 59.6 percent. Grok-4 lacks direct data here, but shines on other coding tests like LiveCodeBench at 79.3 percent.
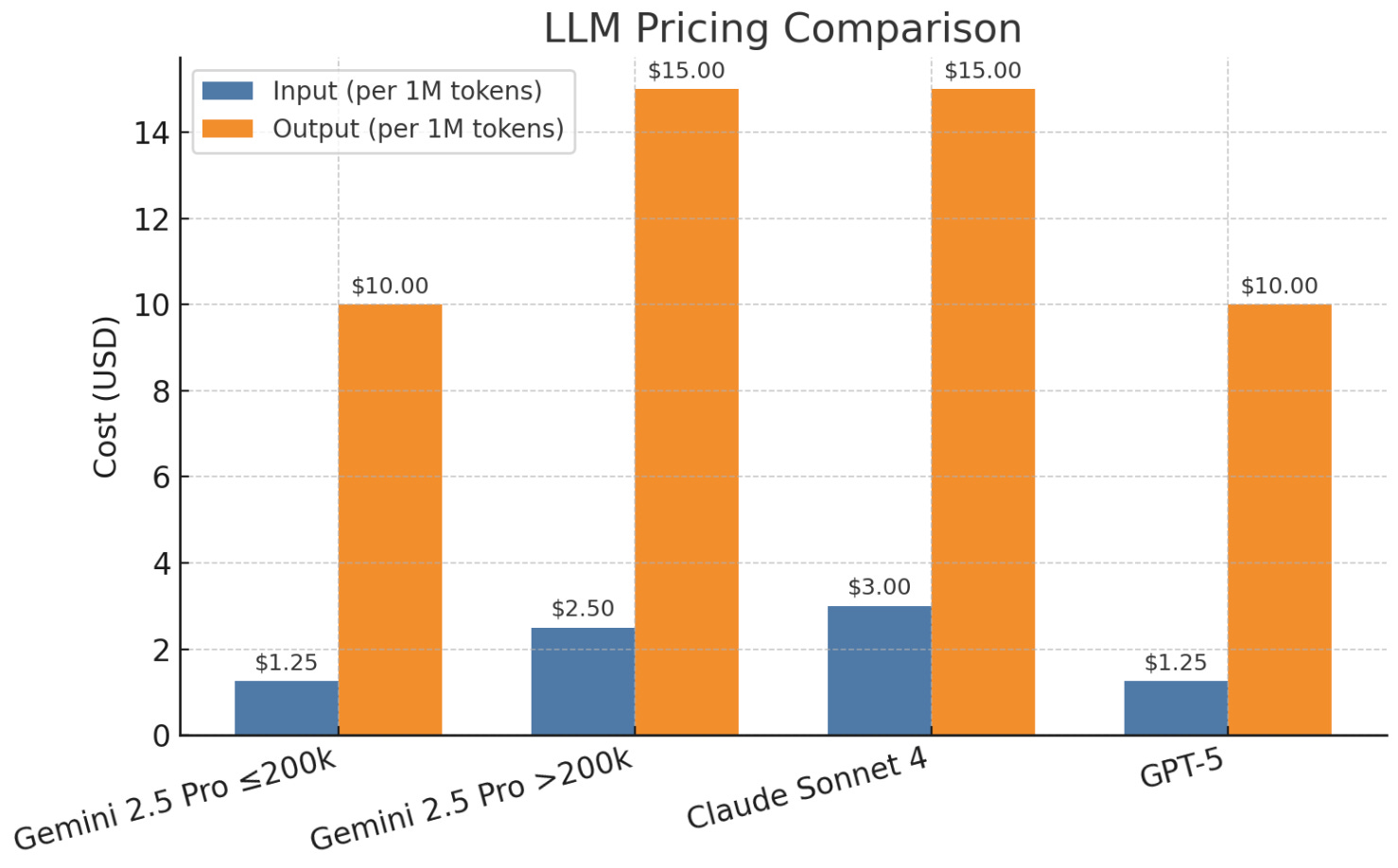
ROI boils down to cost versus output. Grok-4 runs cheap in free tiers, but scales to $300 monthly for heavy use. GPT-5 starts at $20 a month. Claude and Gemini hover around $20 to $250. Speed matters too. GPT-5 is faster than Claude Opus 4.1.
Context windows vary. Gemini's 1 million tokens handle huge codebases. GPT-5 offers 400k. Grok-4 sits at 256k, Claude at 200k.
In real scenarios, I see Gemini excel at multimodal prototypes. It analyzes images and code together for website redesigns. Claude handles ethical designs, catching biases in app layouts. GPT-5 builds games like a jumping ball app from one prompt. Grok-4 aids vibe coding with real-time tweaks.
Reddit users rank Gemini first for coding ROI, then Claude, GPT-5 last due to errors.
Use this chart:
I apply these daily. They guide my picks for fast, smart builds.
Strategies for Building with These Models
Build with purpose. Pick one model, or mix them.
When it comes to prototyping, I use Claude Opus 4.1. Because it has a good sense of UI and coding. For instance, I prompted these four models to create a guitar tuner for me.
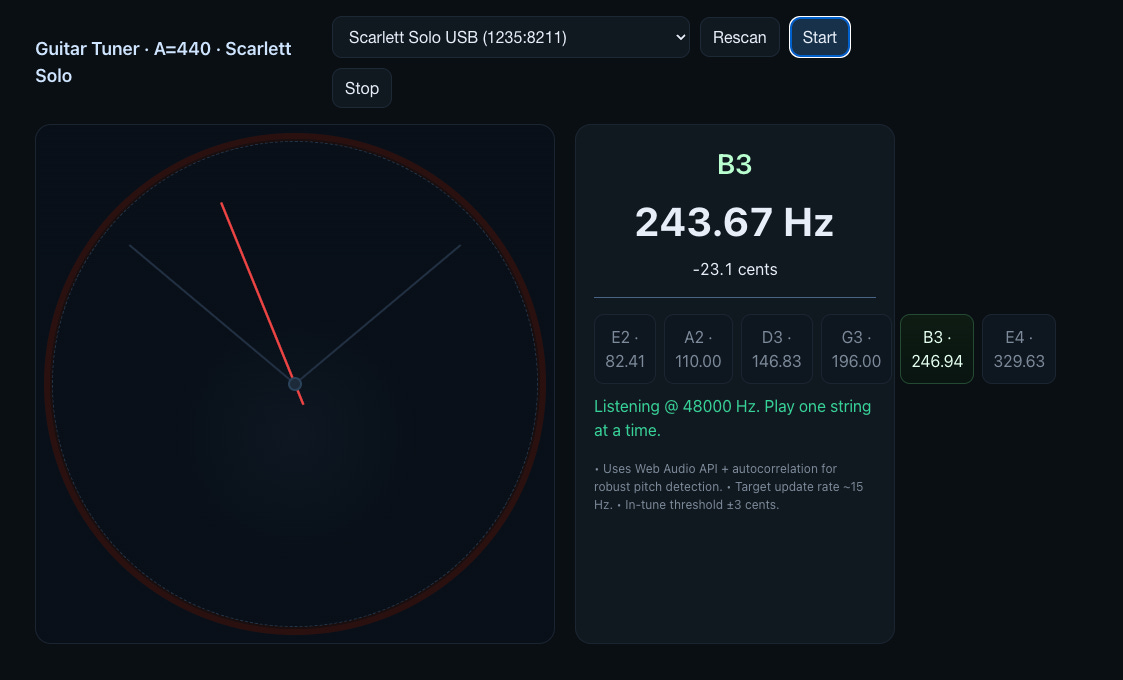
GPT-5 output:
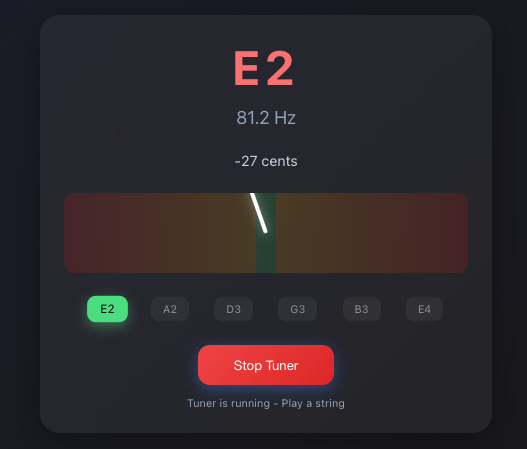
Claude Opus 4.1 output:
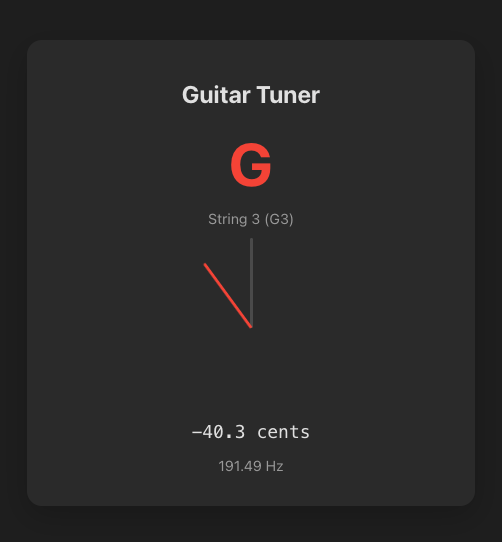
Gemini 2.5 Pro output:
Grok-4 output:
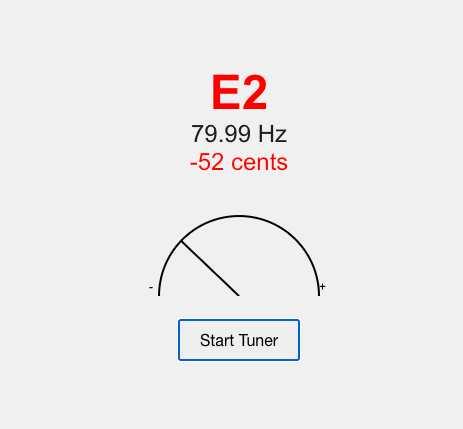
I personally like Gemini 2.5 Pro and Claude Opus 4.1. But when it came to accuracy, like signal sustainability from the guitar, Grok-4 was on the spot, then GPT-5. It could capture a signal for a longer period, enough for me to tune. Others were not that good. The signal would get lost within a couple of seconds.
I also found that GPT-5 is good at instruction following. Something you would prefer while prototyping. Just look at the screenshot, it covers a lot of details. This makes GPT-5 the slowest, though. Claude was faster than Grok-4 and then Gemini.
It really boils down to your preference.
For a workable solution, go for Grok as it will give you a base code to work with. Then, probably Claude or Gemini (for the UI element, as it is good with multimodal outputs) to refine and shape your ideas.
Use GPT-5 if you care about the detailed rendering of output in one shot.
For workflows, integrate into Cursor. Refactor code there. GPT-5 chains tools for agentic tasks like analysis. Gemini 2.5 Pro adds multimodal layers.
Deploy smart. Use APIs for scale. GPT-5 via the OpenAI platform. Claude on Bedrock or Vertex. Test hour-long runs. Models like Grok-4 and GPT-5 manage them without context loss.
Efficiency shows in evals. GPT-5 offers 60% better price per task over Claude in agents. So when it comes to price comparison, OpenAI has the lead.
The Human Factor
These LLMs handle code and prototypes very well. GPT-5 excels in reasoning. Claude 4.1 Opus adds ethical checks. Gemini 2.5 Pro manages multimodal tasks. Grok-4 brings real-time speed. Yet, oversight matters most.
It is crucial that you know what you are building. Your knowledge and domain expertise are valuable. Sure, when using LLMs, you just want to get started as quickly as possible without losing time. They are extremely interesting and fascinating to use. But if we could spend time thinking through our prompts, it would save us a lot of money and time, and reduce frustration.
Learn to use one model first and understand how it works. Hone it. Test it.
Building a product is all about starting small and then adding layers of features. It starts by defining your idea, choosing a model, and honing it.