
From Artifacts to Organisms: Supercharging Development with Claude Code's Agentic Context Engineering
Agentic tools like Claude Code allows to you enhance your product through constant interaction and feedbacks. These interactions are developed through context engineering.


Yesterday, I watched a new podcast from Lenny Rachitsky. The podcast interviewed Asha Sharma (CVP of AI Platform at Microsoft). One thing that fascinated me was that products are transitioning from artifacts to organisms because of AI agents. This idea made me research about this article.
So, I have been using Claude Code as my main productivity tool, and I am still learning to implement it across various workflows. And a couple of things that I am trying to master are Claude.md file that works as memory management and also context engineering.
In this blog, I wanted to share how Claude Code and Context Engineering can help us build products that are essentially organisms. Meaning, they [products] improve themselves each time we interact with the AI agents.
If you are working on context engineering or prompts for your agents or LLM, then you must try Adaline. Adaline is the single platform to iterate, evaluate, deploy, and monitor LLMs.
The Foundation: Context Engineering Meets Claude Code
A recent user study on AI coding assistants found that developers spend over 50% of their coding time verifying generated suggestions. This highlights severe inefficiencies caused by poor context retention and hallucinated outputs. These failures emerge especially in multi-file or multi-stage coding workflows, where traditional AI tools lack persistent context.
Context engineering, a discipline that surfaced around April 2022, allows you to provide context to LLMs and agents.
What is context engineering?
Instead of dumping all logic into one-off prompts, context is treated as a layered, structured resource that is versioned, queryable, and reusable.
Inspired by the “12-factor agents” manifesto, it emphasizes agent restartability, typed tool integration, and traceable state management, bringing software-grade reliability to AI workflows.
Claude Code embodies this methodology. It replaces single-agent guesswork with a coordinated multi-agent system. It is a Planner, Code Editor, Tester, and Reviewer, linked through an enduring Claude.md spec and enhanced by IDE integration.
In Claude Code, the context is constructed deliberately: code dependencies, structured specs, and test scaffolds are retrieved and passed between agents, avoiding memory collapse and guesswork. This is much effective than single-agent prompt systems.
This methodology enables a broader transformation, essentially, moving from static artifacts to adaptive, agentic systems. When context becomes a persistent substrate—not a one-off blob—development becomes a learning organism. This is where systems metabolize feedback, coordinate change, and compound productivity over time.
Architecture for Intelligence
Single-agent LLMs frequently produce hallucinated code, mismatched abstractions, and missed dependencies. This is true especially in large codebases. These failures stem from a lack of specialized coordination and persistent task memory.
Claude Code addresses this gap using a multi-agent architecture. Following a manager-orchestrator pattern, it delegates tasks to four specialized agents: Planner, Code Editor, Tester, and Reviewer.
Each agent operates in an isolated context window but shares access to persistent specs and retrieved artifacts. The orchestrator controls task flow, decision checkpoints, and backtracking logic for corrections or retries.
This system begins with three key layers of structured context:
Intent Translation (GPT-5): Vague or underspecified inputs are rewritten into structured task specs—goals, constraints, file targets, and evaluation rules..
Knowledge Synthesis (NotebookLM): Long-form PDFs and design documents are processed into compact Q&A and bullet points, enabling fast information access.
Repository Context Retrieval: Using a vector database like ChromaDB, Pinecone, and Claude, retrieves embeddings of related files, tests, and changelogs, optimizing for ~40% context token utilization, as cited in their repo case study.
Once context is assembled, Claude executes a research → plan → implement loop:
The Planner breaks down work into sequential subtasks.
The Editor writes changes aligned with those subtasks.
The Tester validates outputs with auto-generated tests.
The Reviewer compares results against the original spec.
Each step passes through a feedback loop, where failed test cases or planning mismatches are rerouted to earlier agents.
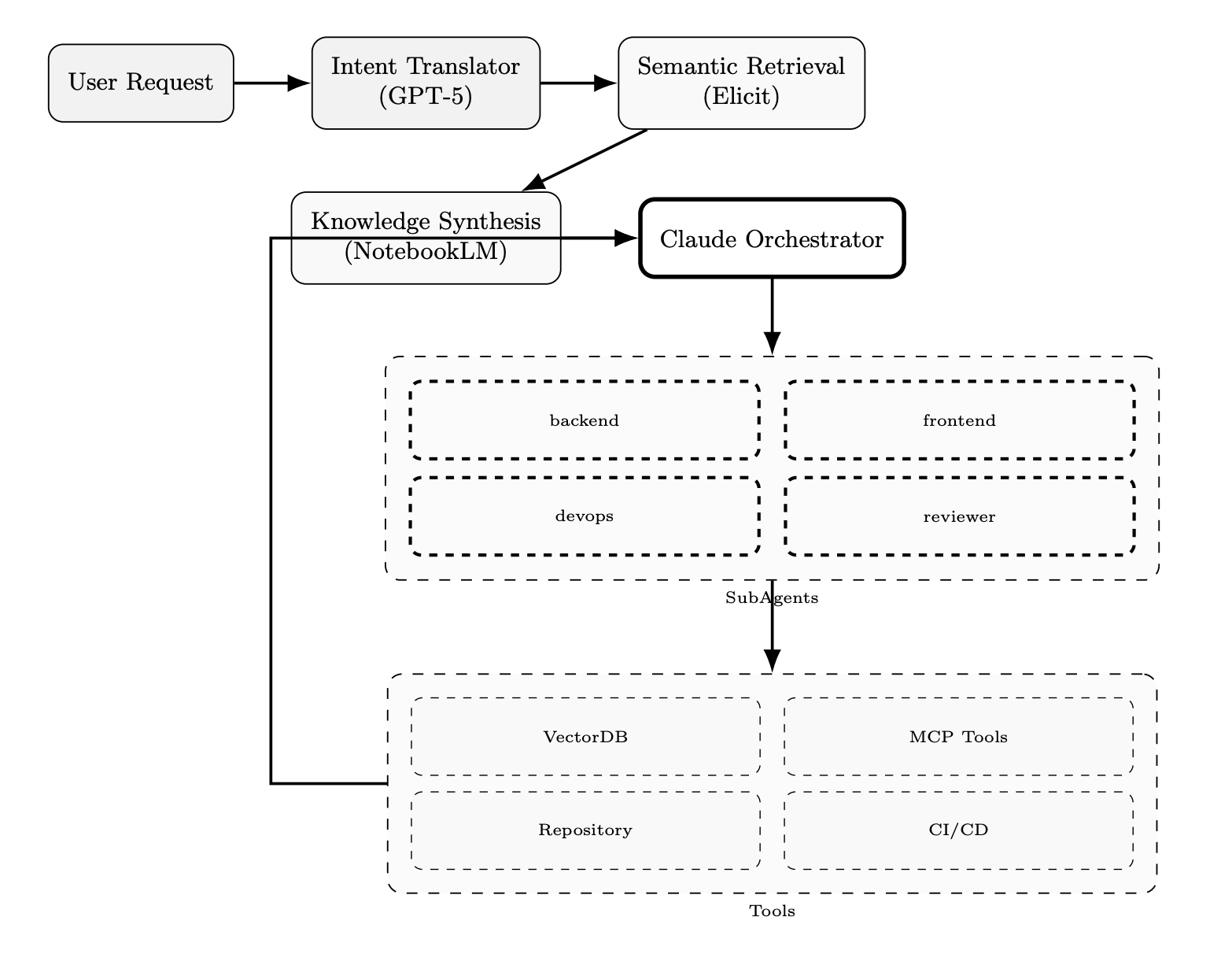
Together, this architecture marks a shift from prompt-chaining to orchestrated reasoning, turning Claude Code into a system that scales with complexity instead of collapsing under it.
How Products Evolve Through Interaction
Static AI products that don’t learn post-deployment fall behind. They miss critical signals from user feedback, like bug fixes, misuse patterns, and missing features. In today’s landscape, building a fixed model and shipping it once is a competitive disadvantage.
Once a model crosses the 30 billion parameter threshold, fine-tuning becomes economically favorable compared to pretraining from scratch, says Asha Sharma. This means that the models aren't frozen after training; they can be finetuned or evolved.
Product teams can now optimize performance through post-training loops, using real-world data to continuously refine agent behavior, retrieval quality, and planning accuracy.
This is a transformation in product thinking. Instead of shipping linear features, teams adopt a “loop, not lane” mindset, meaning treating products as systems with metabolic cycles. Just like biological organisms, high-performing AI systems metabolize data to adapt, improve, and stay competitive in production.
Beyond Static: The Organism Transformation
Teams that treat products as fixed artifacts fall behind. Artifact-thinking focuses on shipping outputs like features, models, releases, etc., while ignoring the systems that evolve them. In contrast, the organism paradigm views a product as a living system that learns, adapts, and improves post-deployment.
The difference is strategic: one decays, the other compounds.
This begins with context engineering. By layering structured specs, tool interfaces, and retrieval into the development process, teams enable adaptability at the system level. Outputs become tunable outcomes, not fixed deliverables that can be adjusted through data feedback and updates to agent behavior.
Two organizational shifts make this possible:
The org chart gives way to a work chart, where autonomous agents and humans are organized by flow, not hierarchy. Tasks move through planner–coder–tester loops, not static team silos. This re-mapping is described by Asha Sharma at Scale AI, supporting workflows across over 15,000 startups (Sharma, 2024).
A new class of full-stack polymath builders has emerged. Engineers fluent in prompt design, agent coordination, and rapid iteration across modalities. These builders operate at the intersection of product, code, and AI system tuning.
Strategic planning has evolved, too. Microsoft now uses a seasonal planning model, adjusting product priorities quarterly based on observed agent performance and team learning loops. In this paradigm, metabolism—the speed at which a team converts feedback into change—is the new KPI.
The faster the metabolism, the faster the product evolves.
Measuring the Business Impact
For many teams, the barrier to adopting multi-agent AI systems is ROI clarity. Without proof of business value, investments stall. But emerging data is clear: multi-agent setups like Claude Code consistently outperform single-agent baselines (80% task success vs 40%, especially in complex, multi-file environments.
Yes, multi-agent systems use 3–5× more tokens per task, but the cost is offset by the developer time saved. When each PR takes hours less, or is resolved in one shot, the ROI skews positive.
At typical cloud LLM pricing, the additional token spend (~$0.20–$ 1 per task) is negligible compared to the $50–$150/hr engineer time.
Learn more about Claude Code here.
Claude Code is also enterprise-ready. It supports project-scoped memory, tool access controls (via MCP), and repo-wide traceability—critical features for production deployment. As more teams adopt this architecture, the unit economics of engineering will shift from hours per task to loops per dollar.
Related: Agentic context engineering changes how you build. It also changes what you need to evaluate before shipping. The full evaluation framework lives here: How To Evaluate Coding Agents In Production.

Final Thoughts
We are in the advent of agents, and soon we will come to a place where we will accept that “Agent is all we need”. Agentic tools like Claude Code can help us accomplish a lot. Our products will be adaptive and much more robust than what we see today.
The future products will align with our moods and emotions because we will be able to quickly iterate on features, thanks to Agentic tools and Context engineering. If we know the right context and do not burden the agents with context overload, we can definitely produce a better and holistic product in a short development span.
But with all this, we still need to prioritize our domain expertise and knowledge. We can only hone these agentic systems if we are clear and hyperspecific.