
Context Rot: Why LLMs Are Getting Dumber?
A product-leader’s cheat-sheet to stop ballooning prompts, broken answers, and runaway costs.


TL;DR: Context rot happens when you give an LLM more information than it can reliably process. The longer the prompt, the worse the output. Even simple tasks—like recalling a name or counting—can fail once the input hits a few thousand tokens.
As Andrej Karapathy tells, think of the model’s context window like RAM. It doesn’t remember—it only holds what’s directly in view.
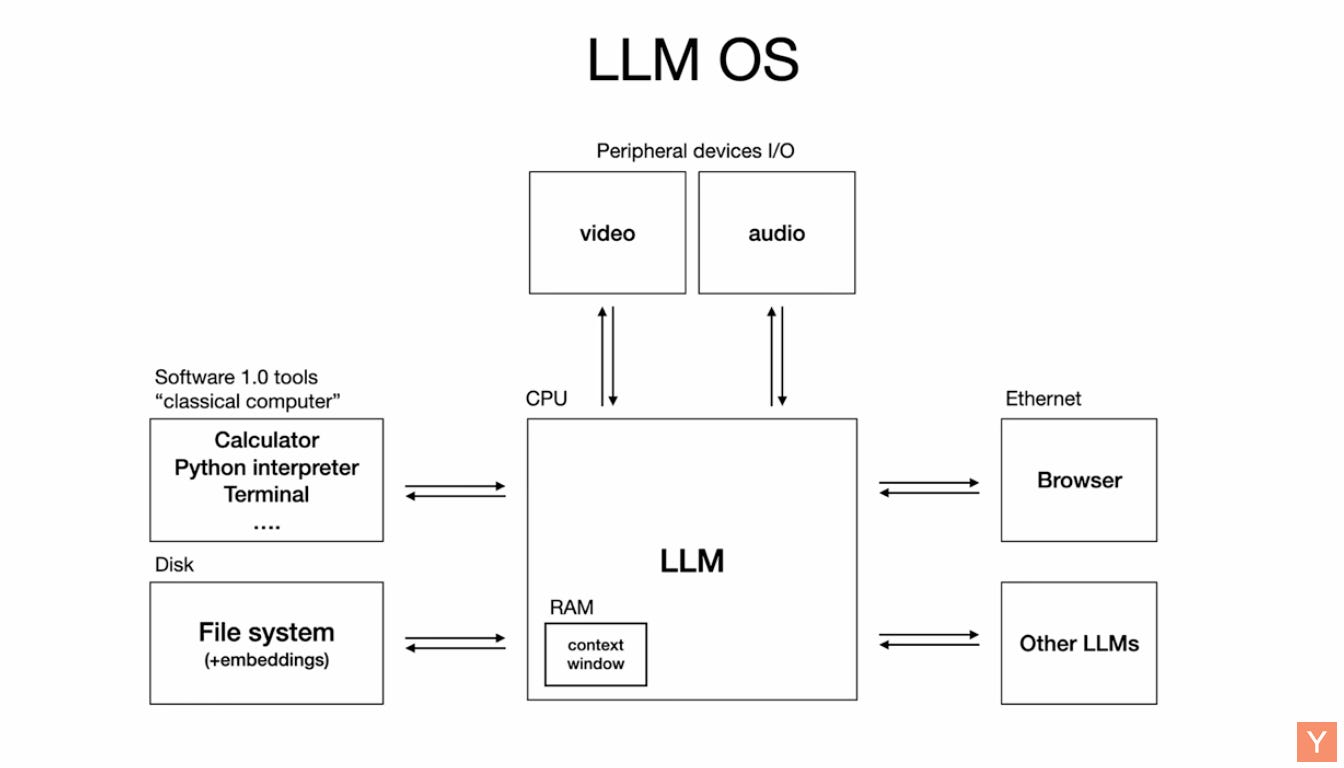
While models advertise 1M+ token windows, research shows they don’t treat all tokens equally. The 10,000th token is not as trustworthy as the 10th.

Take the case of a 64k-token customer support chat. If you dump the entire history into the prompt, hoping the model remembers the user’s city, odds are it won’t. Why? Because the model can’t find the right needle (information to retrieve) in a noisy haystack. It gets distracted, makes things up, hallucinates, and fails to reason.
For product managers and AI engineers, this leads to real pain:
Trust erodes when outputs contradict real facts.
Latency spikes as prompts bloat.
Costs explode with every extra, unnecessary token.
That’s where context engineering comes in: selecting what matters, summarizing what doesn’t, and keeping your AI focused, fast, and reliable.
How Context Rot Creeps into Real Products
Context rot doesn’t announce itself. It quietly slips into your product, hiding behind long prompts and high expectations. In coding agents, this manifests as degraded output during long autonomous sessions — a key difference between Claude Code and OpenAI Codex in how they handle extended runs.
And it gets worse the more tokens you throw at it.
To get an understanding of Context Rot, look at the image below.

Sometimes we stack too much information, which causes the LLM to fail to distinguish between real and irrelevant information. This leads to bad outputs.
Modern LLMs like the GPTs, Geminis, Claudes, and Llamas promise million-token context windows. On paper, that sounds like progress. In practice, the assumption that these models treat the 10,000th token like the 10th just doesn’t hold.
Benchmark scores like Needle-in-a-Haystack can be misleading.
When processing these inputs or prompts, LLMs tend to give slower responses. Hallucinated answers. Models are grabbing the wrong “fact” from early in the prompt. The longer the context, the more room for failure—especially when distractors creep in.
GPT-family models tend to hallucinate with confidence. Claude might abstain, but still fumble.
This degrades trust. And it costs money. You’re billed for every token—relevant or not. Longer contexts also mean longer compute time, even if the model ignores most of it.
Left unchecked, context rot turns into churn. Customers ask for support. Features regress. Infra bills rise. And the root cause? A bloated prompt history that the model can’t reliably process.
Why Bigger Windows ≠ Better Answers
The promise of larger context windows—1M, 2M, even 10M tokens—sounds like progress. But in practice, bigger doesn’t mean better. It often means slower, costlier, and less accurate.
Source: X
Many teams assume that LLMs treat every token equally. But research, including the Chroma study, shows that performance degrades as context grows—even on simple tasks. This degradation isn’t uniform. It comes with failure modes: hallucinations, position bias, and distractors.
Hallucinations increase as the model builds on flawed or irrelevant context.
Another thing is that the position of the information matters too—models often favor earlier tokens.
What about the distractors? Even one distractor can throw the model off. Add a few more, and performance drops sharply.
From a business point of view, the impact is real. Larger contexts mean more tokens, and more tokens mean more cost. You’re billed for everyone. They also slow down response time and inflate infrastructure bills. Worse, they introduce regressions.
Agents stop working reliably.
Users churn.
Support queues fill up.
Benchmarks like the Needle-in-a-Haystack test lexical recall—how well a model can retrieve an exact word or phrase from earlier in the prompt. But real-world tasks involve much more: ambiguity, noise, and contradictions. Your product needs models that reason, not just retrieve.
That’s where these benchmarks fall short.
Reasoning models—especially Large Language Models—are essential because they unlock a new way to build software. Andrej Karpathy calls this shift Software 3.0, where LLMs are programmable computers or OS you steer with natural language.
Prompts become programs.
And with the right context, they can write code, summarize data, or solve problems across complex workflows.
But reasoning alone isn’t enough. These systems are fallible. They hallucinate. They forget. So Karpathy emphasizes partial autonomy—building apps like Cursor or Perplexity, where LLMs do the heavy lifting but humans stay in control. GUIs help speed up verification. Autonomy sliders help tune trust. And proper context engineering ensures the model sees what it needs—no more, no less.
In this new paradigm, context is compute. Engineering it well is how PMs and AI engineers ship products that think, adapt, and stay grounded.
The Context-Engineering Playbook (5 Fast Fixes)
To reiterate, context rot happens when LLMs receive too much input and struggle to make sense of it. Even simple tasks get harder. Performance drops. Costs rise. That’s the problem.
Let’s see how context engineering can help us fix context rot.
In a nutshell, instead of stuffing the entire chat history, codebase, or document set into the prompt, context engineering designs dynamic systems that give the model just what it needs—no more, no less.
Here are five practical strategies:
1. Select and retrieve only what matters
Rather than making the model sift through 100k tokens, pre-select what’s relevant. Use retrieval (e.g., top-k vector search) to feed only the best snippets. The Chroma study showed: less is more, when it’s the right “less.”
2. Summarize & compress chat history
As conversations grow, compress context. Let the model summarize itself—distilling past interactions into short memory blocks.
3. Isolate workspaces
Use scratchpads for intermediate reasoning. It means think of a scratchpad like a rough notebook where the model can “think out loud” before giving a final answer. Just like you might jot down steps while solving a math problem, the model can use this space to break down its reasoning, explore options, or list facts. By keeping this scratchpad separate from the final answer, you reduce clutter and keep the output clean and focused.

4. Guardrail & verify with fast feedback loops
Avoid huge diffs. Use GUIs for inspection. Small, incremental outputs are easier to audit and safer to ship. Something like slider-based autonomy, not agents on autopilot. Slider-based autonomy means giving users control over how much the AI does on its own. Like adjusting a volume knob, you can choose whether the AI just suggests ideas, takes small actions, or completes full tasks automatically. This keeps humans in the loop, making it easier to supervise and correct the AI—especially when things go wrong. It’s safer and more flexible than letting the model run everything on autopilot.
5. Instrument and prune continuously
Track performance. Track token use. Prune what doesn’t help. Context isn’t free—it’s memory. Treat it like infrastructure.
Smart context isn’t more. It’s structured. Controlled. Measured. That’s how you beat context rot.
Key Takeaway
Context rot is real. It shows up when we give models more context than they can reliably handle. Performance degrades. Hallucinations increase. Costs rise. But here’s the good news: it’s normal—but optional.
Research, including the Chroma study across 18 models like GPT-4.1 and Claude 4, confirms that LLMs don’t process context uniformly. Even simple tasks fail when the context window gets too long. The 10,000th token? Often less useful than we think.
Left unchecked, this decay spreads—like a damp spot in a wooden house. One bad assumption early in a session can derail the entire output.
But it doesn’t have to be that way.
Context engineering flips the script. It’s not about stuffing everything into the model. It’s about giving the right info, in the right format, at the right time.
Select relevant snippets. Summarize what matters. Isolate scratchpads. Build GUIs for quick verification. Track everything and prune aggressively.
If done correctly, context engineering makes your product faster, cheaper, and smarter. Faster, because you skip the token bloat. Cheaper, because you don’t pay for irrelevant inputs. Smarter, because your model stays grounded in what actually matters.
LLMs won’t magically get better with bigger prompts. But they will improve with better structure.
But on a personal note: ensure that you spend time with the LLM before you start using it to build products.
👏👏