
Evaluating AI Agents in 2025
A Benchmarking Guide to AI Agents for Product Leaders


OpenAI's Deep Research represents a new wave of AI agents designed to navigate complex information landscapes. Deep Research is different from earlier systems. It doesn't just respond to prompts. Instead, it searches the web by itself. It finds relevant facts and puts them together into clear answers. This tool stands out because of its persistence. It scored 51.5% on the BrowseComp benchmark. It achieves this by carefully examining hundreds of websites. It excels at solving tough problems when simpler methods fall short.
But how do we effectively measure these advanced capabilities? As AI agents grow more autonomous and capable, selecting the right benchmarks becomes crucial for both developers and product teams implementing them.
This article explores the emerging science of agent benchmarking, offering a structured approach to evaluating today’s frontier AI agents. You’ll learn:
How agents differ from traditional language models.
Which benchmarks matter for specific use cases?
How to interpret performance differences between leading models.
Practical strategies for implementing evaluation loops in your development process.
Real-world deployment considerations beyond benchmark scores.
Knowing these benchmarks helps you make smart choices in this fast-changing field, whether you're building agents or picking ones for your product.
Learn more about LLM and agent evaluation here.
Foundations of AI Agents
What “agentic” means in 2025 — autonomy, goal-pursuit, tool use
AI Agents are autonomous software entities that perform goal-directed tasks within digital environments. Modern agents are different from traditional automation scripts. Instead of just following fixed workflows, they can see inputs, think about contexts, and act to meet specific goals.
Three core traits define AI agents in 2025:
Autonomy: The ability to function with minimal human intervention after deployment
Task-specificity: Optimization for narrowly-defined operations within fixed domains
Reactivity with adaptation: Capability to respond to dynamic inputs and refine behavior through feedback loops
AI agents typically serve as modular interfaces between pre-trained models and domain-specific utility pipelines. They excel in applications like customer service automation, internal knowledge retrieval, and scheduling assistance.
LLM agents vs. classic RL agents — training paradigms, strengths, limitations
LLM agents and RL agents are different in how they are trained and what they can do.
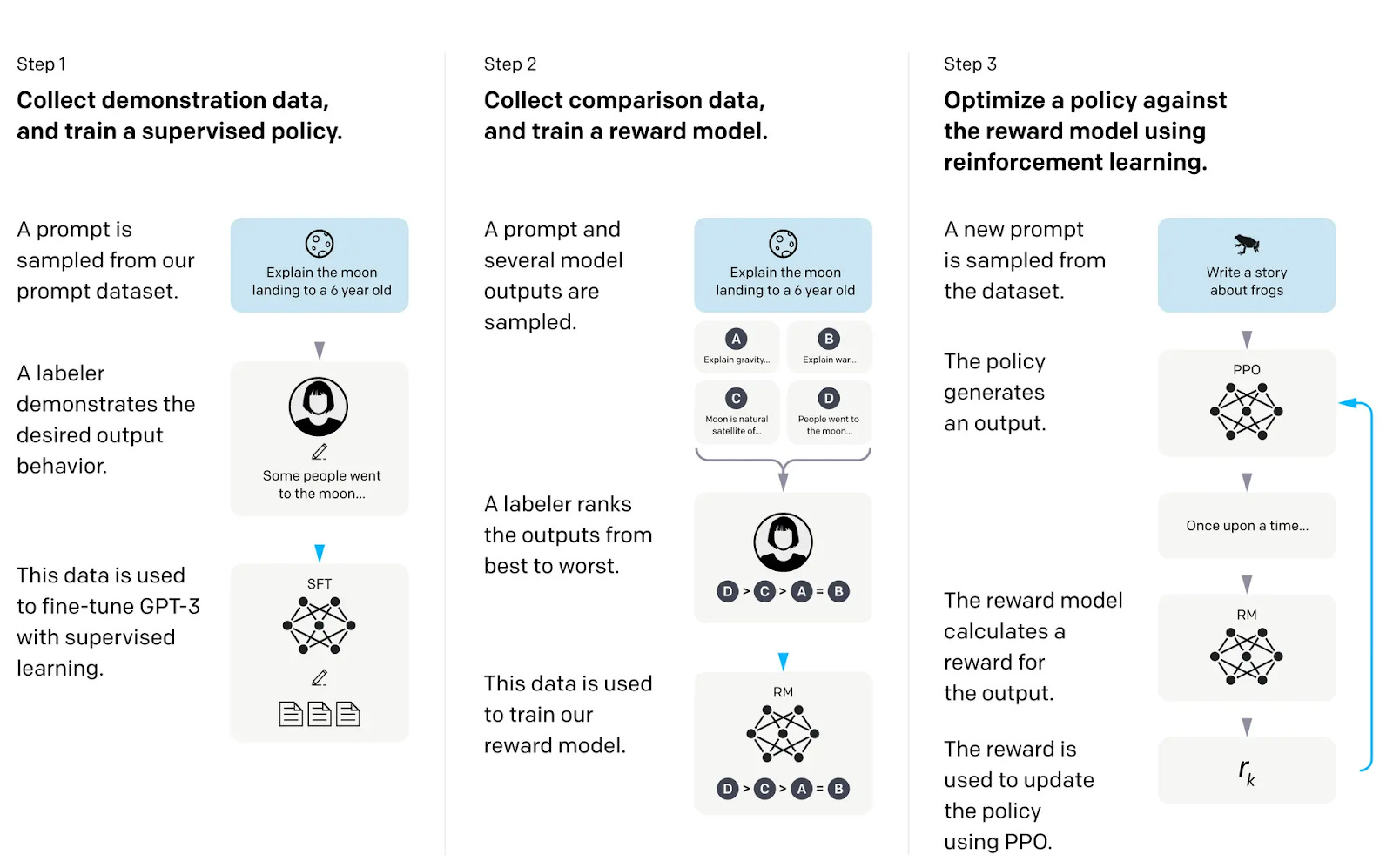
LLM agents utilize large language models as their central reasoning component. These models undergo:
Extensive pre-training on massive text corpora
Instruction fine-tuning to follow directions
Alignment through reinforcement learning with human feedback (RLHF)
They excel in understanding language, reasoning from patterns in data, and applying knowledge across various fields. They do this without needing training for specific tasks.

In contrast, RL agents learn through direct interaction with environments by selecting actions that maximize reward signals. They do well in tasks like recommendation systems and navigation. However, they need a lot of computing power and can be hard to deploy.
Standard architecture — Brain (LLM), Perception, Action, plus Memory & Planning add-ons

The standard architecture of AI agents comprises four primary components:
agent = {
"brain": LLM, # Core reasoning engine
"perception": InputProcessor, # Handles structured/unstructured inputs
"action": OutputGenerator, # Executes decisions via tools/APIs
"memory": ContextManager # Optional for state persistence
}
The perception module ingests signals from users or systems and preprocesses them for the reasoning layer. The brain module—typically an LLM—applies symbolic or statistical logic to these inputs. The action module translates decisions into external actions using function calls or API requests.

Advanced agents add features like persistent memory for keeping context and planning skills. They use frameworks like ReAct (Reasoning + Action). These improvements allow for careful, context-aware actions. They simulate internal discussions before choosing what to do next.
The shift from single-agent loops to team-based workflows is a major step in designing intelligent systems.
How Models Are Trained to Behave Like Agents
Pre-training on vast text corpora (language proficiency)
The first step in making AI agents is pre-training models. This uses huge datasets from books, web content, and dialogues. This process develops basic knowledge and language skills first. Then, agent-specific abilities are added later.
During pre-training, models learn:
Word meanings and relationships
Basic grammar and syntax
Factual information about the world
Simple reasoning patterns
Models like GPT-4, PaLM, and LLaMA undergo this stage using self-supervised learning objectives. The model predicts missing words or next tokens in sequences, gradually developing an internal representation of language.
Instruction-tuning & alignment (RLHF / RLAIF)

After pre-training, models undergo instruction-tuning to follow human directions. This includes supervised fine-tuning using prompt-response pairs. These pairs show helpful, accurate, and safe behaviors.
Alignment techniques further refine model outputs:
RLHF (Reinforcement Learning from Human Feedback) uses human preferences to guide model behavior
RLAIF (Reinforcement Learning from AI Feedback) leverages other AI systems to provide more scalable feedback signals
These processes teach models to avoid harmful content, acknowledge limitations, and respond in user-preferred ways.
Task-specific agent fine-tuning
Models become true agents through specialized fine-tuning for specific capabilities. OpenAI Deep Research shows this method well. It uses reinforcement learning to tackle tough web browsing tasks. These tasks need both persistence and creativity to find information.
agent_training = pretraining + instruction_tuning + task_specific_rl
This stage often incorporates closed-loop feedback, where the model learns from its successes and failures at completing real-world tasks.
Training with Tools
The newest training approaches focus on teaching models to work with tools and collaborate with other agents. These curricula involve several components, such as,
Training models to break complex goals into smaller steps
Invoke external APIs
Reason through task dependencies.
This creates agents capable of pursuing extended objectives through intelligent tool use and strategic planning.
Multiple specialized agents are now trained to communicate and coordinate toward shared goals, similar to human team environments. These systems learn coordination protocols, role specialization, and collaborative problem-solving. This allows them to do more than any single agent can.
Why Benchmarking Agents Is Different
From static NLP metrics to dynamic, multi-step evaluation
Traditional NLP evaluations rely on static metrics like accuracy, precision, and BLEU scores. These measure performance on isolated text-to-text transformations without capturing autonomous behaviors.
Agent benchmarks differ fundamentally by focusing on:
evaluation = performance + process + persistence
Instead of measuring a single output's quality, agent evaluations track behavior over time. They evaluate how systems solve problems, bounce back from failures, and adjust to changes.

The evaluation environment itself often contains dynamic elements. This can include web pages that change between sessions. It also covers interactive coding environments and simulated users with changing needs. OpenAI Operator is one of the many examples.
Core dimensions to measure
Effective agent benchmarks measure several key capabilities:
Planning & reasoning: Ability to break complex tasks into logical steps and adapt plans when faced with obstacles
Tool selection & execution: Skill at choosing appropriate tools from available options and using them correctly
Persistence / long-horizon tasks: The Capacity to maintain focus on goals despite setbacks, requiring many attempts or approaches
Collaboration & coordination: Working effectively with other agents or humans to achieve shared objectives.
These dimensions reflect real-world challenges agents face when deployed in production environments. Each requires sophisticated behavior beyond simple text generation.
Taxonomy of 2025 benchmarks (web, coding, abstract reasoning, general assistance)
Current agent benchmarks fall into distinct categories:

Web interaction benchmarks, like BrowseComp, test how well an agent navigates online content. They measure the agent's skill in finding specific information. This requires persistence in browsing numerous websites when answers aren't immediately available.
Coding benchmarks assess agents on program synthesis and debugging capabilities. ARC-AGI is crucial now. It tests agents on solving new problems by using reasoning instead of just pattern matching.
Abstract reasoning tests evaluates general intelligence. They measure how well agents tackle new tasks. These benchmarks resist traditional machine learning approaches as they require true adaptation at test time.
Flagship Benchmarks Explained
BrowseComp

BrowseComp evaluates an agent's ability to persistently navigate the web to find hard-to-discover information. It consists of 1,266 challenging questions created using an "inverted question" approach. Human trainers start with specific facts and construct questions that deliberately obscure them, requiring multi-hop reasoning across multiple sources.
How it works:
Human trainers verify questions aren't solvable within 10 minutes
Agents must search through numerous websites to locate answers
Performance is measured by accuracy and calibration error
Evaluation happens via semantic matching against reference answers
AgentBench

AgentBench provides a comprehensive evaluation of LLM agents across eight distinct interactive environments. This multi-dimensional benchmark measures planning, reasoning, tool use, and decision-making in realistic scenarios.
How it works:
Tests environments include operating systems, databases, knowledge graphs, digital card games, and web interfaces
Each environment presents unique challenges requiring different skill sets
Agents must parse instructions, plan actions, and execute them correctly
Performance is evaluated on task completion and efficiency metrics
ARC-AGI-2

ARC-AGI-2 contains visual abstract-reasoning puzzles deliberately designed to be "easy for humans but hard for AI." Each task involves understanding a pattern from demonstration examples and applying it to new inputs.
How it works:
Tasks consist of input/output grid pairs for demonstration
Agents must identify the underlying pattern transformation
Testing involves generating correct output grids for new inputs
Success requires genuine reasoning rather than pattern matching
Humanity's Last Exam

This benchmark tests expert-level knowledge across over 100 diverse subjects. It deliberately includes questions at the frontier of human knowledge, serving as a stress-test for models claiming broad expertise.
How it works:
Questions span mathematics, humanities, sciences, and professional fields
Difficulty exceeds typical standardized tests
Evaluation uses strict grading criteria for accuracy
Performance is compared against human expert baselines
SWE-bench & ML-Dev-Bench
These benchmarks evaluate coding capabilities by testing agents on real-world software engineering tasks and machine learning development workflows.
How it works:
SWE-bench uses actual GitHub repository issues
ML-Dev-Bench tests dataset handling, model training, and API integration
Agents must understand requirements, write code, and fix bugs
Evaluation based on functional correctness and efficiency
GAIA & related assistants tests
GAIA serves as a benchmark for General AI Assistants that requires a combination of reasoning, multimodality, web browsing, and tool-use proficiency.
How it works:
Tests include multi-turn dialogues requiring diverse capabilities
Tasks require coordination across multiple modalities
Agents must effectively orchestrate different tools to complete tasks
Evaluation covers helpfulness, accuracy, and safety dimensions

How Today’s Leading Models Stack Up
Comparison table
The current leaderboard reveals significant performance variations across different benchmarks, highlighting each model's unique strengths and limitations:
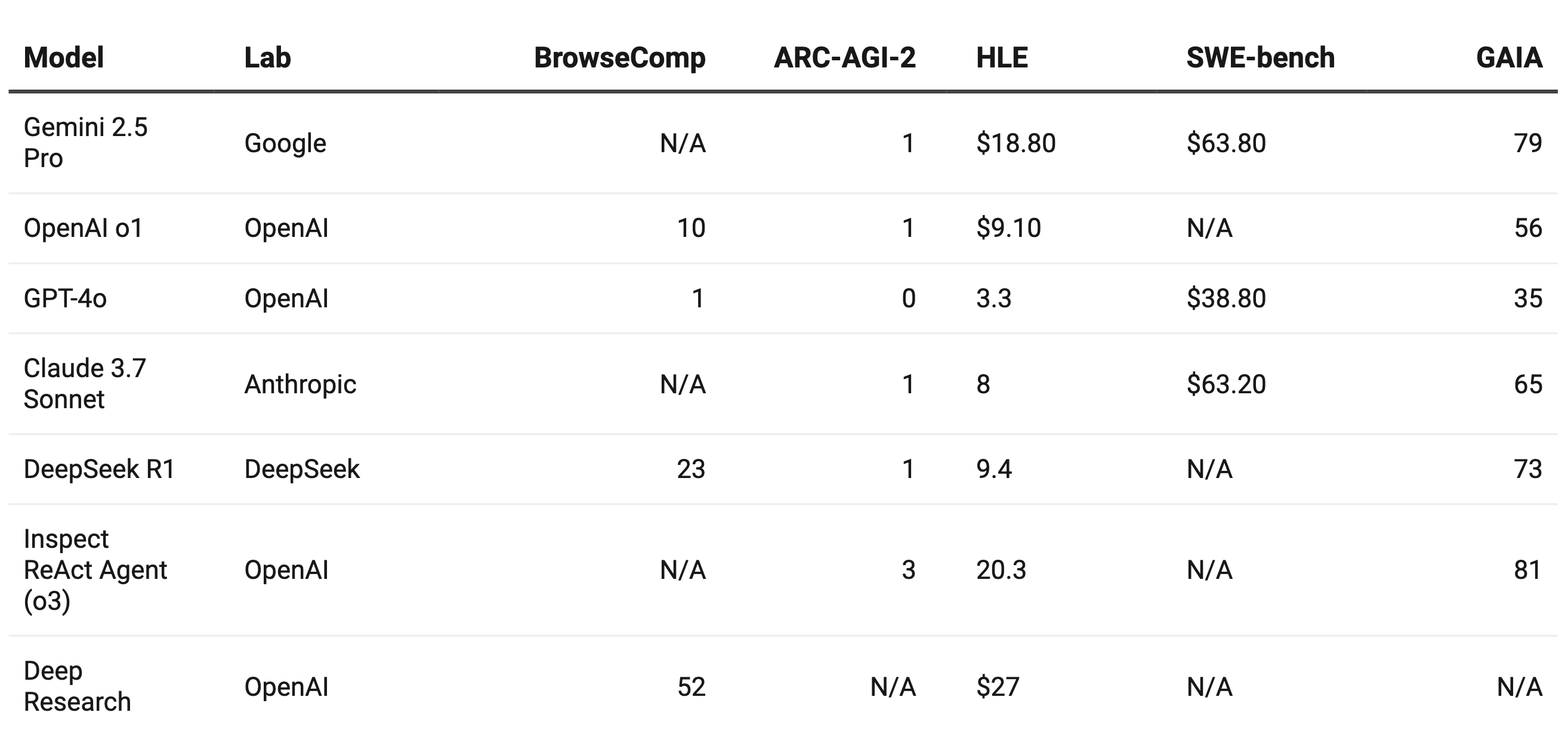
This data reveals how each model demonstrates specialized capabilities rather than universal strengths across all benchmark categories.
Strengths & weaknesses revealed
The benchmark results expose clear patterns of specialization among leading models:
Web Navigation Excellence: OpenAI Deep Research dominates in BrowseComp with 51.5% accuracy, demonstrating superior persistent browsing capabilities
Coding Proficiency: Gemini 2.5 Pro and Claude 3.7 Sonnet excel in software engineering tasks, both achieving over 63% on SWE-bench
Reasoning Limitations: All models struggle with abstract reasoning tasks, with even the best performer (Inspect ReAct) reaching only 3.0% on ARC-AGI-2
General Assistance Capability: Inspect ReAct Agent leads in GAIA with 80.7%, followed closely by Gemini 2.5 Pro at 79.0%
These patterns reflect each organization's focus areas and training approaches. Models showing strength in web tasks typically incorporate extensive training on browsing behaviors, while coding proficiency correlates with specialized fine-tuning on programming datasets.
How to interpret leaderboard gaps when choosing a model

When selecting a model based on these benchmarks, consider these factors:
Task alignment: Choose models that excel in benchmarks most similar to your specific use case
Performance gaps: A 5-10% difference may be negligible for general applications but critical for specialized tasks
Benchmark limitations: Most tests have constraints that may not reflect real-world conditions
Complementary strengths: Consider using multiple models for different aspects of complex workflows
Remember that benchmark results represent performance under specific controlled conditions. Actual production performance depends on:
real_world_value = benchmark_score × task_alignment × deployment_optimization
The ideal strategy often involves leveraging different models for their respective strengths rather than seeking a single solution for all agent applications.
Using Benchmarks in Product Development
Map your use-case to the right benchmark family
Selecting appropriate benchmarks is crucial for meaningful evaluation of AI agent performance. Different agent applications require distinct measurement criteria that align with their primary functions.
How to map effectively:
Web agents → BrowseComp or Mind2Web for measuring search and navigation capabilities
Coding assistants → SWE-bench or ML-Dev-Bench for software engineering and development tasks
General assistants → GAIA or MMAU for evaluating broad helpfulness across diverse requests
Reasoning systems → ARC-AGI for testing problem-solving on novel tasks
Make a requirements matrix that weighs various capabilities according to your application needs. This ensures your evaluation strategy focuses on the aspects most relevant to your users.
Establish a continuous "eval loop" (LLM-as-Judge, regression suites)
Implementing a continuous evaluation pipeline helps maintain quality as your agent evolves. This involves systematically testing changes against established benchmarks before deployment.
Key components of an effective eval loop:
Baseline benchmark suite: Core tests run on every code change
LLM-as-Judge automation: Using an LLM to evaluate responses based on predefined criteria
Regression detection: Automatic alerts when performance drops below thresholds
A/B comparison: Side-by-side evaluation of different agent versions

This method gives quick feedback during development. It also makes sure that new features don't hurt existing capabilities.
Cost–latency trade-offs & guard-rails for real-world deployment
When you move from benchmarks to production, you will face key trade-offs. These include performance, cost, and response time. Carefully balancing these factors is essential for sustainable deployment.
Considerations for production deployment:
Latency budgets: Define maximum acceptable response times for different request types
Cost optimization: Consider using smaller, specialized models for routine tasks
Safety guardrails: Implement content filtering, confidence thresholds, and human review triggers
Progressive rollout: Deploy to limited user groups before full release

Remember that benchmark performance represents theoretical capabilities under ideal conditions. Deploying in the real world needs more focus on reliability, scalability, and error handling. This helps provide a steady experience for users.
Conclusion: Why Benchmarks Matter for Product Leaders
Strong benchmarking frameworks help product leaders see agent strengths and weaknesses before launch. These standard measurements show where your agent shines and where it may have issues. This helps you match development goals with market needs.
Effective agent benchmarking delivers multiple strategic benefits:
Improved resource allocation - Direct engineering efforts toward high-impact improvements
Reduced deployment risk - Identify potential failure modes before they reach users
Competitive differentiation - Discover underserved capability areas where your solution can lead
Progress tracking - Measure improvement rates to forecast future capabilities
Enhanced communication - Share concrete performance metrics with stakeholders
As agent technologies change quickly, organizations that use structured evaluation processes benefit greatly. They see better product quality and faster time to market. Each new benchmark closes the gap between model skills and real-world applications. This opens doors for new ideas across many industries.
Start measuring your agents today. The insights you gain will change how you prioritize features. They will also help you allocate resources and deliver value to users in this new landscape.