
From Zero To 100,000: The Questions We Set Out To Answer
One year of Adaline Labs. Over 100,000 subscribers. Here's what we believed, what turned out to be true, and what completely surprised us.

TLDR: How do LLMs actually work? How do you build reliably with them? How do you know if they’re working in production? These were the questions nobody was answering clearly in 2025. So we built Adaline Labs for the people, asking them. Some of these were the AI PM, the early-stage founder, and the engineer who became their team’s de facto AI lead. One year. 100,000 readers. Here’s the story.

When we published the first post on Adaline Labs, we had a simple and maybe naive belief that the people building AI products were being underserved by the content around them.
There was plenty of research. Plenty of hype. Plenty of “AI will change everything” takes. What was harder to find was something practical, honest, and aimed at the person actually responsible for shipping an AI feature. Or building AI products. This included the product manager and leaders, the early-stage founder, and the engineer who just became their team’s de facto AI lead.
That was the gap we wanted to close. And one year later, with over 100,000 of you reading, we think we were onto something.
Here is what we set out to answer and what we learned along the way.
The First Question: “What Even Is This Thing?”
In early 2025, most product leaders we spoke to were in a strange position. They were being asked to build with LLMs without really understanding how they worked. Not at a research level, that was never the point, but at a product level. Enough to make good decisions.
So we started from the ground up.
What are embeddings, and why do they matter for search? How does attention work, and what does that mean for context limits? What is test-time scaling, and why is reasoning so expensive? What even is an agentic LLM?
These were not academic questions. They were the questions a PM would ask before a planning meeting, and couldn’t find a clean answer to. We wrote them for that person.
The audience was not looking for a shortcut. They wanted to actually understand; they just needed someone to explain it without the jargon.
Posts like "What PMs Need to Know About Transformers" and "Understanding Attention Mechanisms in LLMs" became some of our most widely shared pieces. What surprised us was the enormous appetite for this content.
The Second Question: “Okay, But How Do I Build With It?”
Once we established the fundamentals, the natural next question arrived: how do you actually go from model to product?
This is where things got interesting and where the content got more opinionated.
We wrote extensively:
About prompt engineering, not as a parlour trick, but as a genuine product discipline.
About tool calling, and how to write effective functions that your LLM can actually use.
About RAG systems, agentic workflows, and the moment when your product stops being “an app with AI” and starts being “an AI-native product.”
We also started writing about the mistakes, such as context rot, token burnout, and how an LLM product can quietly degrade in production without anyone noticing until users start churning.
Product leaders were not intimidated by the technical depth. They were hungry for it. The more specific and precise we got, including actual code, actual prompt structures, and actual failure modes, the more the audience grew.
The Third Question: “How Do I Know If It's Working?”
This one took us longer to articulate, but it became the thread that tied everything together.
You can build a beautiful agentic product. You can have great prompts, well-designed tool calls, and a thoughtful RAG setup. And then it goes to production, and you have no idea what’s actually happening.
Is the LLM hallucinating?
Is a tool call failing silently?
Is your prompt behaving differently at 10 pm than it does at 10 am?
Is latency spiking for a specific type of user query?
This is the evaluation and observability problem. And it turns out it’s the most important problem in AI product development that needs attention right now.
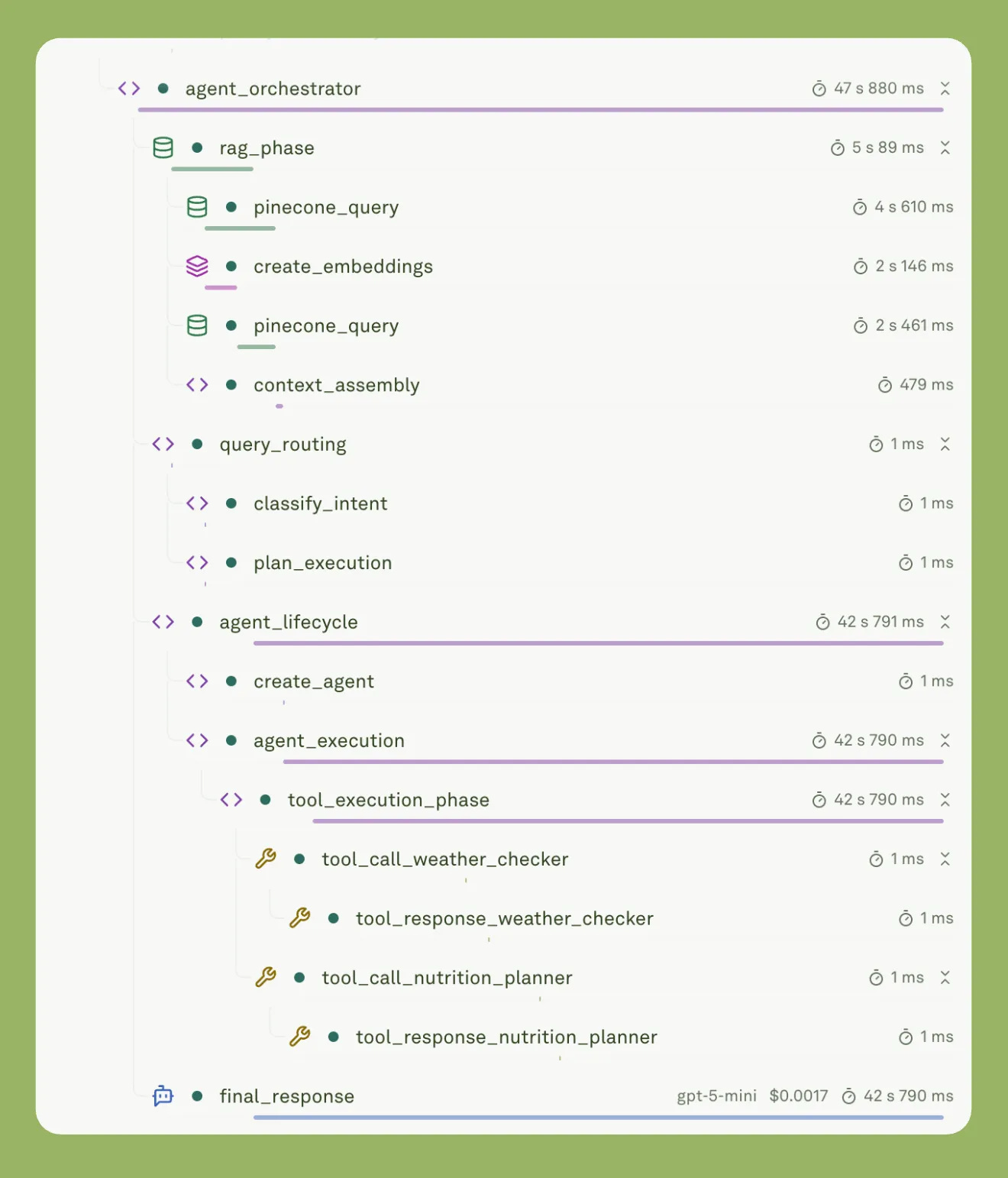
We published pieces on LLM observability, eval frameworks, LLM-as-a-judge, and continuous evaluation in production.
And then, in 2026, it became the central thesis: observability is the operating system for reliable LLMs.
AI Observability And Evaluations: The Operating System For Reliable LLM Products

TLDR: Most LLM products don’t crash. They quietly leak trust, safety, and budget. Silent failure is the default failure mode, and most teams never see it coming. This is a practical guide for engineers and PMs shipping LLM features in production. You will leave with a concrete framework for
Interestingly, this resonated not just with engineers, but with product leaders who finally had a language for why their AI products felt unpredictable. They were not imagining things. The systems were genuinely hard to see inside, and that was fixable.
Our Readers Shaped This Newsletter
Everything we know about our audience comes from listening closely and constantly. These were the consistent signals our readers kept sending us:
How do LLMs actually work?
How do I build reliably with them?
With new models dropping every month, how do I integrate them into existing workflows?
Which model suits which part of the workflow?
Which tool (Cursor, Claude Code, Codex, etc.) can product leaders and builders use to enhance their productivity?
How do I know if it is working in production?
We did not pick our topics. Our readers did. We researched, studied, executed, and wrote about them. Over time, those signals pointed to a clear set of content pillars and a clear center.
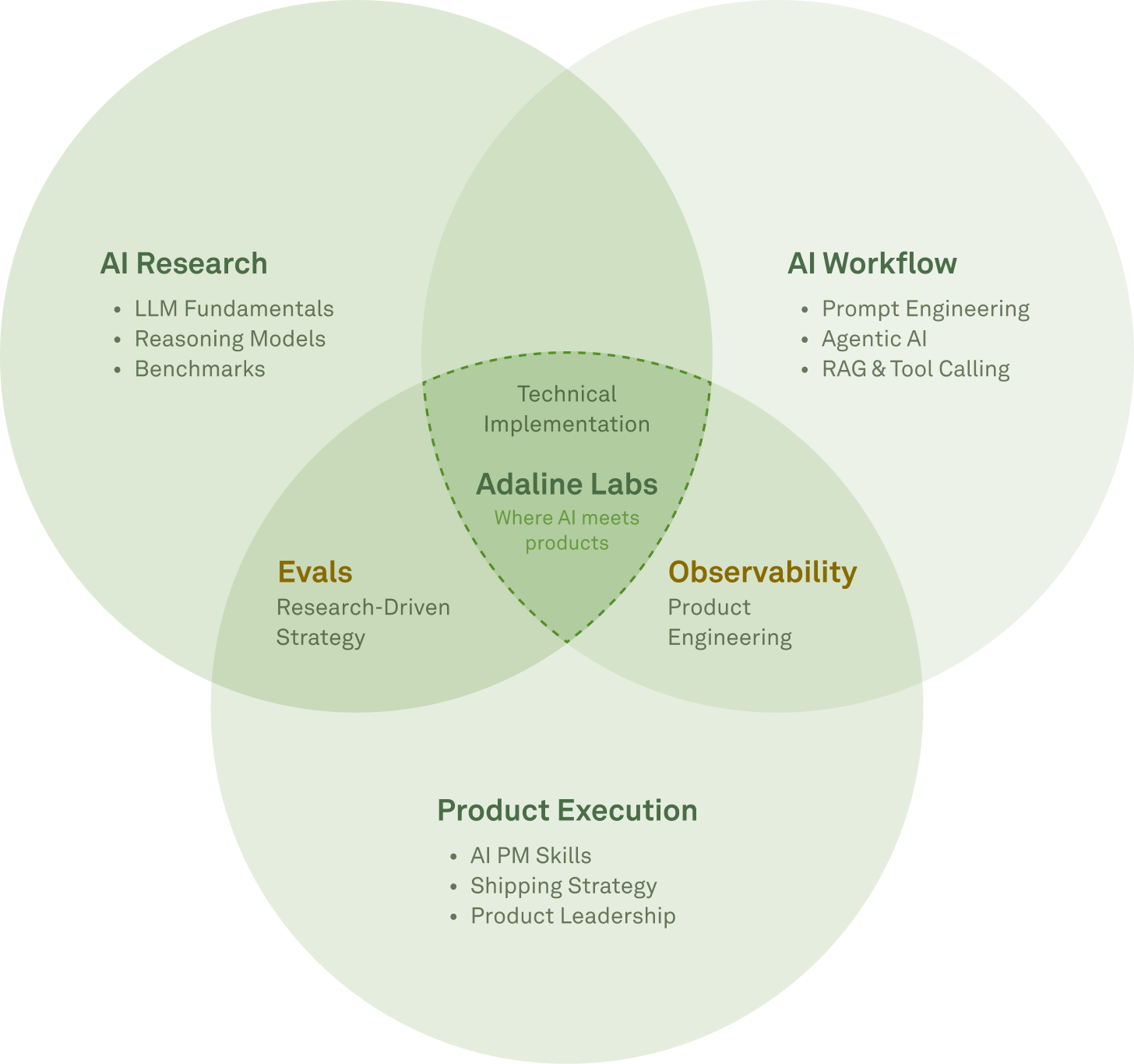
The diagram above captures something we did not plan but discovered over the year. Evals and Observability are not standalone topics. They live at the intersections. They are the connective tissue between understanding AI, building with it, and shipping it with confidence.
What We Believe Now That We Didn’t When We Started
A year in, here are the things we believe more firmly than when we started:
The PM is the most important person in an AI product team. Not because they write code, but because:
They hold the product vision.
They understand the user and serve as the connective tissue between what the model can do and what they should do.
Equipping that person matters more than we initially realized.
Fundamentals compound. The readers who understood embeddings and attention early are now the ones thinking clearly about context engineering and agentic architecture. There are no shortcuts in this field. But there are faster paths, and that’s what we tried to build.
The hardest problems are not technical. They are judgment problems. For instance:
When do you use a smaller, faster model vs. a frontier one?
When is a RAG system the right call vs. fine-tuning?
When do you add an eval layer vs. ship-and-learn?
These are the decisions our readers face every week, and they need frameworks, not just tutorials.
100,000+ people are both humbling and clarifying. Humbling because this community chose to spend its attention here, every week, amid everything competing for it. Clarifying because the scale of the response tells us something: there is a massive, underserved audience of people building at the frontier of AI who want to think rigorously, not just move fast.
What Comes Next
The questions are getting harder. And we believe this is what unfolds in 2026:
AI agents become real production infrastructure.
Evals and observability move from nice-to-have to non-negotiable.
AI coding agents change how teams ship.
Product work gets redefined when everyone can build.
We are going to keep following the questions. The ones our readers are wrestling with. The ones who do not yet have clean answers but deserve clear thinking.
Thank you for being here for year one.
The questions get harder. Our answers get clearer.