
How Do Embeddings Work in LLMs?
A Comprehensive Analysis of Vector Representations in Large Language Models


Embeddings are the foundation of how large language models understand and process text. These numerical vectors transform words and sentences into mathematical representations that machines can work with effectively. Recent advancements in embedding models have dramatically improved how LLMs interpret language nuances and relationships between concepts.
The field has evolved rapidly, with models like Gemini Embedding, Gecko, and OpenAI’s text-embedding-3-large pushing performance boundaries across multiple languages and specialized domains. These innovations enable:
More accurate semantic searching
Improved text clustering capabilities
Enhanced classification performance
Better cross-lingual understanding
This article explores how embeddings function within large language models (LLMs). We'll examine their fundamental structure and purpose, the architectural approaches used in their development, and how they're generated from larger LLMs through distillation processes.
You'll learn about the critical role of training data in embedding quality, including how synthetic data and filtering techniques enhance performance. We'll also cover evaluation frameworks like the Massive Text Embedding Benchmark (MTEB) that measure embedding effectiveness.
By understanding how embeddings work, you'll gain insights into the mathematical foundations that power modern language AI systems and their practical applications.
Fundamentals of Embeddings in LLMs
Let’s begin with the fundamentals and how and why LLMs need an embedding model.
Definition and Purpose of Embeddings
Embeddings are numerical vectors that capture the semantic meaning of data in LLMs. They serve as the core mechanism for how LLMs represent and manipulate text. These mathematical representations allow machines to process and understand language in a format they can work with efficiently.

The primary purpose of embeddings is to transform discrete text elements into continuous vector spaces. This conversion enables LLMs to perform essential operations like measuring similarity, executing searches, clustering related items, and making comparisons based on meaning rather than exact matches.
The Vector Representation Concept
When text is converted into vectors, each piece of information becomes a point in a high-dimensional space. Mathematically, if we denote a token by an index i, an embedding function f maps it to a d-dimensional vector,
This process creates a structured space where:
Similar words cluster together
Related concepts appear near each other
Semantic relationships are preserved through geometric distance
How Embeddings Capture Semantic Meaning
Embeddings capture meaning through the relative positions of vectors. In well-trained models, the distance between word vectors directly correlates with their semantic similarity. For example:
"King" - "Man" + "Woman" ≈ "Queen"
Words like "doctor" and "physician" have highly correlated vectors
This geometric organization emerges naturally during model training. As the model learns to predict words in context, it adjusts embedding vectors to reflect meaningful relationships.
The Dimensionality of Embedding Spaces
Modern embedding spaces typically range from 256 to 4096 dimensions. For example:
OpenAI’s text-embedding-3-small and text-embedding-3-large have dimensions of 1536 and 3072, respectively.
Gemini Embedding: 3072 dimensions
Gecko with 256 dimensions outperforms some models with 768 dimensions
Higher dimensions can capture more nuanced relationships but require more computational resources. Some models now support “elastic embeddings” that can be truncated to smaller sizes when needed.
Evolution from Word2vec to Contextual Embeddings
The journey from static to contextual embeddings represents significant progress in NLP. Early models like word2vec assigned a single vector to each word regardless of context. Modern LLMs generate contextual embeddings where the same word receives different vectors depending on its usage.
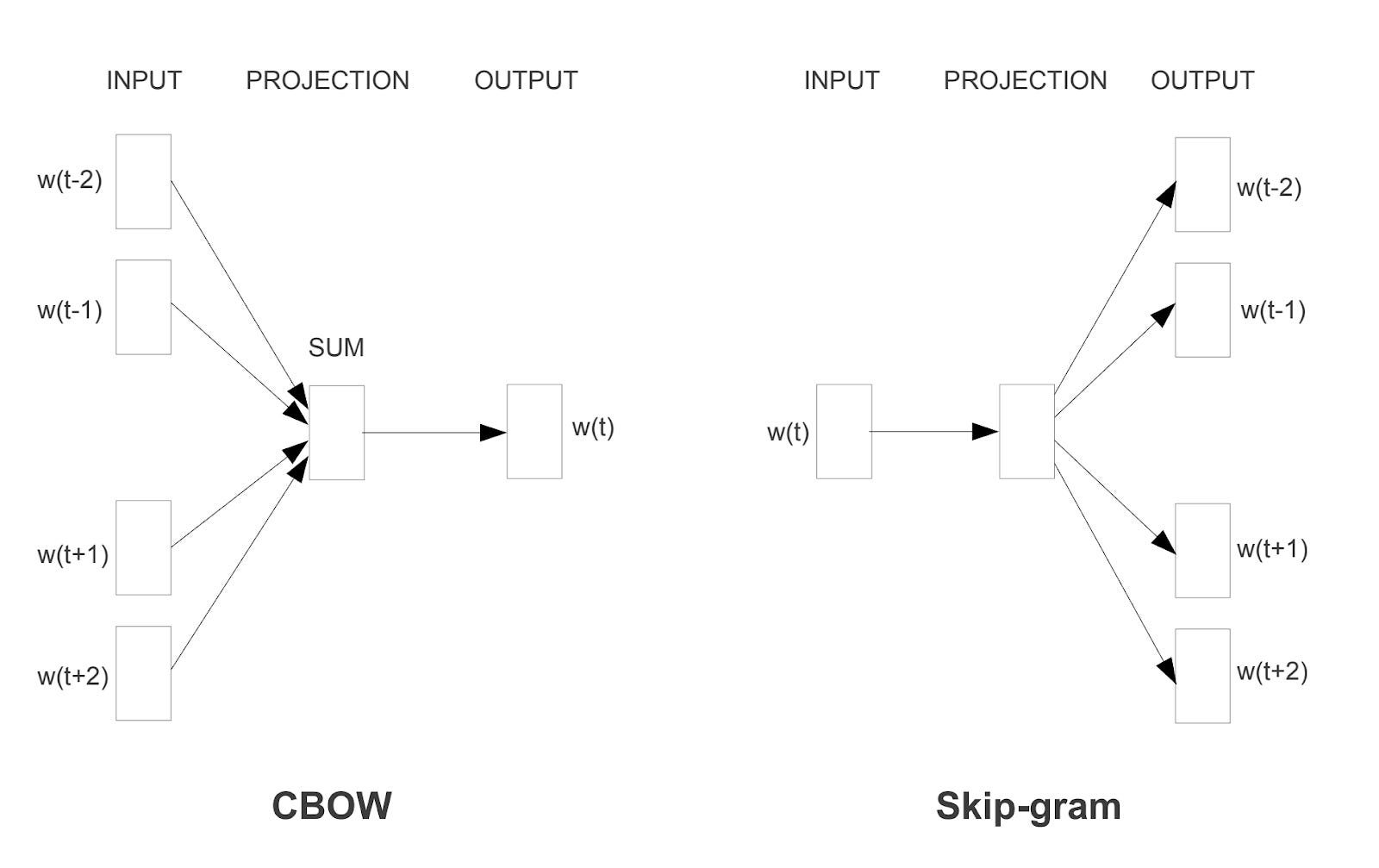
Contextual embedding models produce richer representations that capture nuance and polysemy. This advancement enables more sophisticated language understanding and generation capabilities.
Architecture and Training Objectives
Common Architectural Approaches for Embedding Models
Most modern text embedding models use a bi-encoder transformer architecture. This design processes each text input independently through a transformer encoder like BERT or RoBERTa. After encoding, a pooling operation (typically mean-pooling or using the [CLS] token) converts variable-length sequences into fixed-size vectors.

Unlike cross-encoders that process text pairs together, bi-encoders enable efficient scaling for tasks requiring comparisons across large datasets. This architecture is particularly valuable for retrieval tasks where pre-computing embeddings significantly reduces computation time.
Training Objectives
The primary training objective for embedding models is contrastive learning. This approach works by:
Bringing similar text pairs closer in vector space
Pushing dissimilar texts farther apart
Using a temperature parameter to control the separation strength
Mathematically, the loss function (InfoNCE) looks like:
Where q is a query, d^+ is a positive match, and d^- are negative examples.
Pre-training Methodologies
Pre-training typically involves exposing models to vast amounts of text data. Effective approaches include:
Training on billions of text pairs (e.g., English E5 used 1 billion pairs)
Using translation pairs for multilingual models
Employing continued language model training with special formatting
Leveraging naturally occurring text pairs (title-body, anchor-clicked page)
This stage establishes broad semantic understanding before task-specific fine-tuning begins.
Post-training Optimization Strategies
After primary training, several optimization techniques improve embedding quality:
Matryoshka Representation Learning (MRL): Trains models to produce embeddings that remain useful when truncated to smaller dimensions
Multimodal extensions: Additional training to embed images alongside text
Calibration: Normalizing embedding magnitudes for consistent similarity scores
Fine-tuning on proprietary data: Adding domain-specific knowledge
The Relationship Between Model Size and Embedding Quality
Performance strongly correlates with model size, with larger models generally producing better embeddings. Key insights include:
Multi-billion parameter models dominate most embedding tasks
Smaller, well-tuned models can sometimes match larger ones on specific tasks
Increasing model size offers diminishing returns against computational costs
Size-efficient architectures can deliver competitive performance at lower resource requirements

From LLMs to Embedding Models
How LLMs Serve as Embedding Generators
Large language models can generate embeddings in two main ways. First, by extracting hidden-layer representations directly from the LLM. Second, by prompting the LLM to output some form of embedding. Though LLMs contain rich semantic knowledge, running a multi-billion parameter model for every piece of text is impractical and costly.
Instead, the dominant approach uses derivative models of LLMs for embedding. OpenAI's text-embedding-ada-002 exemplifies this strategy. Rather than calling GPT-4 directly, this specialized model is trained on similar data but fine-tuned to output vectors instead of text tokens.
The Process of Distillation from Larger LLMs
Knowledge distillation transfers capabilities from a powerful teacher model (an LLM) to a smaller student model (the embedding model). This typically involves:
Using the LLM to generate diverse query-passage pairs
Having the LLM relabel and filter the data
Training the smaller model on this curated dataset
The Gecko model demonstrates this effectively with a two-step distillation pipeline:
Step 1: Generate synthetic training data with the LLM
Step 2: Use the LLM to identify positive and negative examples for each query

Fine-tuning Strategies for Embedding-specific Tasks
Fine-tuning embedding models requires specialized approaches:
Task-specific prompting: Including task descriptions like "Represent the meaning of this sentence for retrieval:”
Contrastive objectives: Training the model to differentiate between relevant and irrelevant matches
Multi-task learning: Combining diverse datasets (question answering, paraphrasing, classification)
In-batch negatives: Using other positive examples in a batch as negatives for efficient training
Architectural Modifications for Embedding Efficiency
Several modifications improve the embedding model's efficiency:
Pooling strategies: Using mean-pooling or specialized pooling layers
Sparse embeddings: Incorporating keyword features alongside dense vectors
Context length extensions: Enhancing models to handle longer texts (up to 8K tokens)
Dimensional optimization: Implementing variable-dimension embeddings through MRL
Tradeoffs Between Model Size and Embedding Quality
The relationship between model size and quality presents important tradeoffs. Larger models generally produce better embeddings but require more resources. The latency-performance graph reveals three viable approaches:
Maximum speed: Word embedding models like Glove offer the fastest processing
Maximum performance: Large models like GTR-XXL, ST5-XXL, or SGPT-5.8B deliver the highest quality
Balanced approach: Mid-size models like MPNet and MiniLM provide good quality with reasonable speed
Data Considerations and Synthetic Training
The Role of Training Data in Embedding Quality
The quality and diversity of training data directly impacts embedding performance. High-quality embedding models require extensive exposure to varied language patterns. This includes different domains, tasks, and linguistic structures.
Traditional approaches relied on large, manually labeled datasets. However, creating these datasets is time-consuming, expensive, and often introduces unintended biases. Modern embedding models now utilize a mix of human-labeled and synthetically generated data to achieve optimal results.
Synthetic Data Generation Using Other LLMs
LLM-generated synthetic data has become a game-changer for training embedding models. This process typically involves:
Prompting an LLM to generate diverse queries for a given passage
Creating tasks that span different applications (question answering, fact verification)
Producing pairs of related text that maintain semantic connections
For example, the Gecko model uses a two-step approach:
First generating queries from passages
Then using these to create a dataset called FRet containing 6.6M examples

Data Filtering Techniques and Importance
Not all generated data is equally valuable. Several filtering techniques improve dataset quality:
Removing duplicates to ensure variety
Ensuring minimum diversity across queries
Discarding trivial or nonsensical examples
Using LLMs themselves as quality judges
The Gemini Embedding model demonstrates this by using "Gemini auto-rater" to filter lower-quality examples like unrealistic search queries. This filtering process showed consistent improvements across different languages.
Hard-Negative Mining Strategies
Hard negatives are examples that appear relevant but aren't actual matches. They're crucial for training robust models. Effective mining strategies include:
Using an initial embedding model to find nearest neighbors for queries
Having an LLM score these candidates based on relevance
Selecting passages that appear similar but don't answer the query
This challenging training signal forces the model to make finer-grained distinctions between truly relevant and superficially similar content.
Balancing Diversity and Quality in Training Data
Creating effective training datasets requires careful balance. The most successful approaches combine:
Task diversity: Including classification, retrieval, similarity tasks
Domain variety: Covering academic, conversational, news, and technical content
Language representation: Balancing high and low-resource languages
Data quality: Prioritizing well-formed, accurate examples
Experiments show uniformly sampling across diverse tasks outperforms dataset-proportional sampling, highlighting the importance of exposure to varied linguistic patterns.
Evaluation and Benchmarking
The MTEB (Massive Text Embedding Benchmark) Explained
The Massive Text Embedding Benchmark (MTEB) provides a comprehensive framework for evaluating embedding model performance. It spans 8 embedding tasks covering 58 datasets and 112 languages. Before MTEB, models were often evaluated on limited task sets, making it unclear whether models excelling at similarity tasks would perform well in clustering or retrieval.

MTEB tasks include:
Bitext mining
Classification
Clustering
Pair classification
Reranking
Retrieval
Semantic Textual Similarity (STS)
Summarization
This diverse evaluation framework helps identify truly versatile embedding models versus those specialized for narrow applications.
Key Metrics for Embedding Quality Assessment
Different tasks require specific evaluation metrics to assess performance properly:

MTEB reports a single mean score summarizing performance across tasks while also providing task-specific metrics for detailed analysis.
Task-Specific Evaluation Considerations
Each task presents unique evaluation challenges:
STS tasks: Measure how well embedding similarity correlates with human judgments using Spearman correlation.
Retrieval tasks: Evaluate if a query can find relevant documents using metrics like Precision@k and nDCG@10.
Clustering tasks: Assess how well embeddings group similar items using adjusted Rand Index.
Multilingual tasks: Test if embeddings maintain quality across languages and can connect concepts across language barriers.
Challenges in Fair Comparison Across Models
Fair comparison faces several obstacles:
Data contamination: Some models may have seen evaluation data during training
Implementation details: Pre-processing or hyperparameters can significantly impact results
Task weighting: Different benchmarks may emphasize tasks differently
Resource requirements: Comparing models with vastly different computational needs
Interpreting Benchmark Results Meaningfully
When examining benchmark results, consider:
No single model dominates all tasks, suggesting the field hasn't converged on a universal solution
Task performance varies significantly – a model excellent at STS may be mediocre at retrieval
Balance raw performance against practical considerations like speed and memory usage
Consider language coverage when selecting models for multilingual applications
Look beyond average scores to task-specific performance matching your use case
A thorough evaluation looks beyond headline numbers to understand whether a model aligns with specific application requirements.
Comparative Analysis of Embedding Models
Detailed Comparison of Major Embedding Models
Theembedding model landscape features several leading contenders with distinct characteristics. Recent benchmarks reveal significant performance variations:

Gemini Embedding establishes a new benchmark with substantial leads across all categories, particularly in cross-lingual capabilities.
Strengths and Weaknesses of Each Approach
Each model demonstrates distinct advantages:
Gemini Embedding:
Strengths: Superior performance across tasks, excellent multilingual capability
Weaknesses: Larger dimensional size requires more storage
Gecko:
Strengths: Compact yet powerful, efficient at 256 dimensions
Weaknesses: Performs less consistently across languages
GTE-Qwen2:
Strengths: Strong bilingual performance (Chinese-English), open source
Weaknesses: Less effective for code tasks
E5 Models:
Strengths: Well-documented, established performance
Weaknesses: Lower performance on code, limited by backbone architecture
Performance Across Languages and Domains
Multilingual performance varies significantly between models. LaBSE excels in bitext mining across many languages, while models like SGPT-BLOOM perform well only on languages they've extensively seen during pre-training.
For domain-specific performance:
Scientific domains: SPECTER showed strong performance
Code-related tasks: Gemini Embedding and Gecko lead
General English tasks: Most models perform comparably well
Low-resource languages: Performance drops significantly for most models
Efficiency Considerations
Speed-performance tradeoffs reveal three distinct categories:
Speed optimized: Word embedding models (Glove, Komninos) process thousands of examples per second
Performance optimized: Large models (Gemini, GTR-XXL) provide highest quality at higher latency
Balanced: Mid-sized models (MPNet, MiniLM) offer good performance with reasonable speed
Storage requirements scale with embedding dimensions – Gemini's 3,072 dimensions require significantly more storage than Gecko's 256 dimensions.
Selection Criteria for Specific Use Cases
When selecting an embedding model, consider:
Task alignment: Choose models that excel at your primary task (retrieval, clustering, etc.)
Language requirements: For multilingual applications, prioritize models with strong cross-lingual capabilities
Computational constraints: Balance quality against available resources
Openness: Consider whether you need a fully accessible model or can use API-based services
Specialization needs: Domain-specific applications may benefit from specialized models
The best choice depends heavily on your specific application constraints and performance requirements.
Conclusion
Embeddings serve as the mathematical foundation that enables large language models to understand and process human language. Through our exploration, we've uncovered several critical insights:
Embeddings transform text into vector representations, creating a mathematical space where semantic relationships can be measured and manipulated
Modern embedding models use bi-encoder transformer architectures and contrastive learning objectives to optimize performance
The distillation process transfers knowledge from larger LLMs to create more efficient, specialized embedding models
Training data quality significantly impacts embedding performance, with synthetic data generation and filtering techniques providing substantial improvements
Evaluation frameworks like MTEB provide comprehensive assessment across diverse tasks and languages
The embedding model landscape continues to evolve rapidly, with Gemini Embedding currently setting new performance standards across multilingual, English, and code domains. When selecting an embedding model, consider your specific task requirements, language needs, computational constraints, and whether you need an open-source solution or can use API-based services.
As embedding technology advances, we can expect even more effective representations that capture nuanced semantic relationships while requiring fewer computational resources. Understanding these foundational technologies helps inform better implementation decisions in your AI systems.