
LLM-as-a-Judge
A brief research note on LLM-as-a-judge including best practices.


Evaluating LLM outputs can save you a lot of time from shipping broken prompts and features.
A lot of talk and discussion is going on when it comes to the degrading performance or output of LLMs. You go to Reddit and you will find that users are not satisfied with LLMs such as Claude (these days) and GPT-5.
So, what's going on with LLMs?
You provide an input or prompt addressing your requirements, and the LLM doesn’t provide you with a desirable answer. This might be happening because of one of two reasons, or both:
Bad prompt
Bad LLM
Now, I understand that in a certain workflow that includes creativity, such as writing and brainstorming, you can hone the LLMs by using more structured prompting. For the most part, they will be satisfactory.
But when it comes to more logical and complex workflows, like adding features to the product, modifying the existing codebase, iterating a complex architecture, etc., you need a lot of prior context as well as a sequential structure of the instructions. These instructions should contradict each other.
Now, writing such prompts on the go is extremely tedious every time. And for such a situation where you cannot write detailed instructions every time, you need to find a way to evaluate every output from the LLM.
To make it more efficient and scalable, you must use another LLM to evaluate on those outputs.
Why LLM Evaluation Matters for Product Success
Human judges often disagree on outputs, with rates as low as 80% agreement in preference scoring tasks. This arises from subjective interpretations and annotator fatigue.
In production, AI teams grapple with scalability as models grow more complex. Many teams struggle with scaling quality assurance for LLM outputs, resulting in inconsistent user experiences and unsustainable manual review processes that bottleneck product development.
Weak evaluations create deployment hurdles, where data complexities delay rollouts. Microsoft's LLM-Rubric deployment reduces inconsistencies in human-AI conversations, yet initial setups reveal gaps in domain-specific scoring.
It turns out that teams often miss early failure modes, resulting in costly rework. Some key insights include:
Cost escalation patterns in manual review processes, with expenses surging as data volumes reach millions.
Time-to-market delays from evaluation bottlenecks often extend cycles due to data fragmentation.
User satisfaction correlated with evaluation quality, where robust metrics boost retention by linking outputs to real-world impact.
Microsoft's studies validate rubric/criteria methods with strong alignment to experts in benchmarks. Peer-reviewed work stresses robustness tests, showing LLM judges hit 80-90% human agreement on preferences. These methodologies, like G-Eval, deliver reliable validation through chain-of-thought scoring.
Yet, limitations persist. Manual evals provide depth but falter on scale, while automated ones introduce biases like favoring verbose responses. Hybrid approaches alleviate issues, although ideal solutions require continuous calibration within rubric frameworks.
Understanding LLM-as-a-Judge Fundamentals
LLM-as-a-Judge is a framework where LLMs evaluate outputs from other LLMs using structured prompts to score qualities like coherence or accuracy. Research highlights three key methodologies:
Pointwise scoring for single outputs
Pairwise comparison to rank alternatives
Pass/fail checks for binary decisions.
Teams need scalable evaluation methods that can assess LLM outputs with human-like judgment but without the resource constraints and inconsistencies of manual review. This taxonomy positions LLM-as-a-Judge within broader evaluation hierarchies, bringing automated metrics and human oversight for complex tasks together.
Research deployments show LLM judges accelerating assessments in production environments. Applications span dialogue systems for conversation quality checks, content moderation to detect toxicity in social platforms, and code evaluation for logic verification in development tools.
We also find prompt engineering advances through rigorous testing. Chain-of-thought prompts enhance alignment with human judgments. They achieve up to 7.5% gains in Spearman correlation across key benchmarks.
Position bias emerges as a frequent failure mode in pairwise setups. Teams mitigate it effectively with randomized response orders. Calibration techniques further reduce inconsistencies in judgments.
Model ensembling stands out in optimization strategies. It lifts the correlation with human evaluations notably. Improvements range from 5.9% to 183.8% over standard metrics in software engineering tasks.
Best Practices for LLM-as-a-Judge Implementation
Successful LLM-as-a-Judge deployment requires systematic prompt engineering, careful bias mitigation, and robust validation frameworks to ensure reliable evaluation that aligns with human judgment while maintaining production-scale efficiency.
LLM-Rubric research outlines technical requirements like rubric-based prompts for multidimensional scoring.
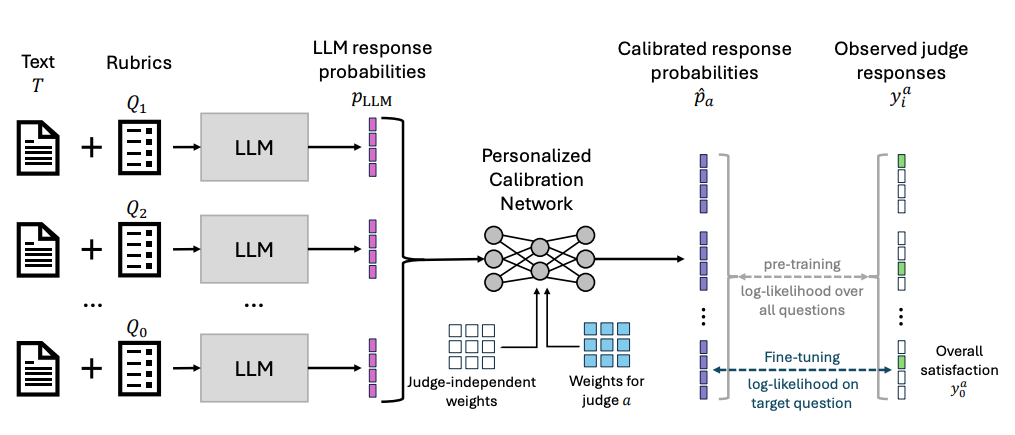
Microsoft’s LLM-Rubric production deployment provides practical lessons in scaling evaluations. Teams craft prompts with explicit criteria to guide judgments effectively. Validation involves benchmarking against human annotations early on. Bias checks span diverse inputs to catch inconsistencies.
Prompt Engineering Best Practices:
Use structured evaluation criteria with clear scoring rubrics for consistency. The criteria shouldn’t contradict each other.
Implement chain-of-thought reasoning before final judgments to enhance alignment.
Define explicit quality dimensions like naturalness, relevance, and accuracy.
Test prompt variations against human baseline evaluations for refinement.
Try Adaline to evaluate prompts on datasets with more than 1000 rows using LLM-as-a-judge. Give your prompts a superpower and avoid failure at production.
Establish human evaluation benchmarks for initial calibration to set standards.
Monitor judge consistency across different input types via ongoing metrics.
Track correlation metrics with human annotator agreement, aiming for 85% or higher.
Implement A/B testing for prompt optimization to boost performance.
Test across diverse demographic and linguistic groups to reduce disparities.
Use multiple judge models for cross-validation and balanced scoring.
Document and monitor systematic evaluation patterns like verbosity bias.
Implement fairness constraints in scoring algorithms to minimize prejudices.
LLM-as-a-judge is an extremely important methodology to evaluate your prompt and LLMs ’ output. I will cover this topic more in the coming days, as it is a vast topic to cover. Likewise, I will cover another trending topic called agent-as-a-judge as well.
Through these blogs, I want to emphasise the importance of LLM evaluation. Most of us can write prompts, but we often fail or put aside the thought of evaluating them. I know it takes an extra bit of time but it is worth.
Your prompts can set your product apart. And rights prompts will let you build products with less debugging and more iterating to perfection.