
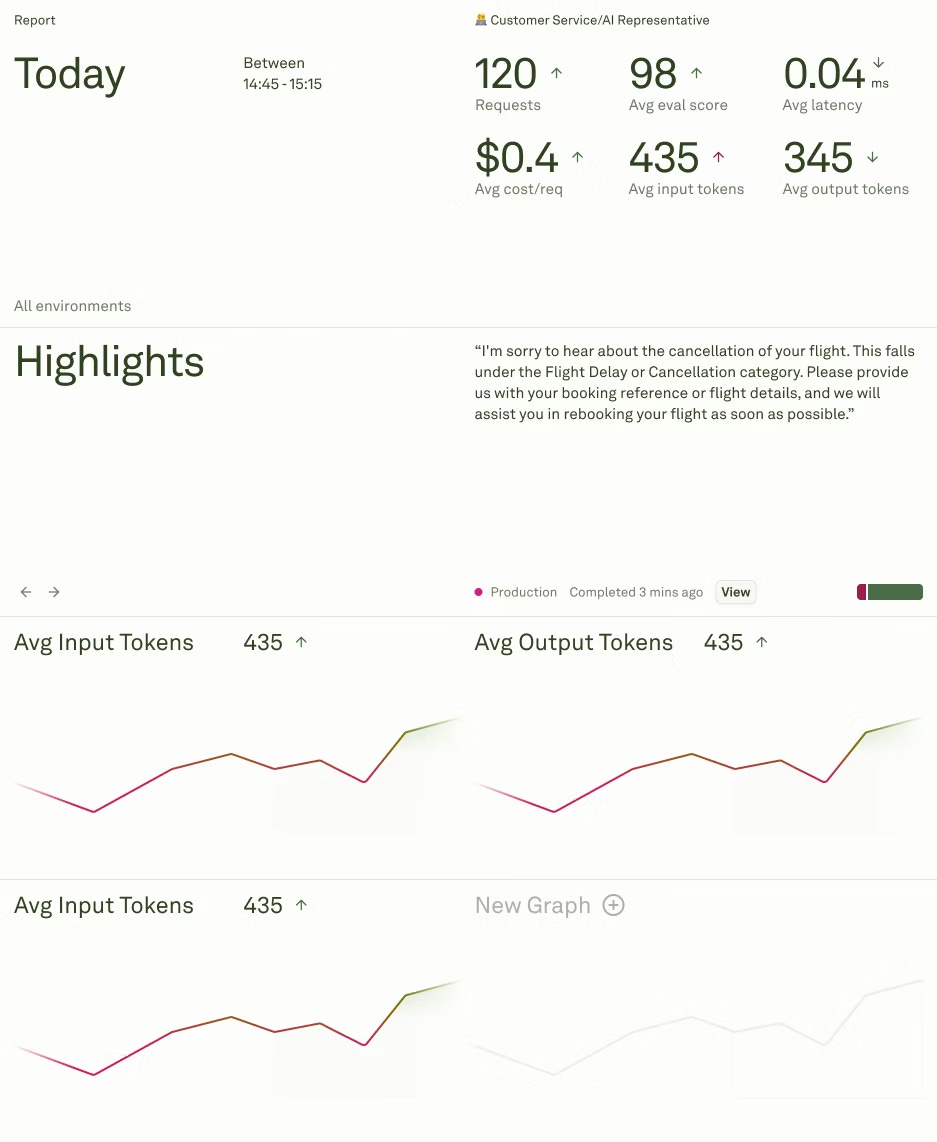
LLM Observability For Product Leaders
Turn hidden system failures into actionable insights that drive user experience and revenue growth.


We are in a period where LLMs have become the core of many software. They are brains that gather information, provide insight, and help us make decisions. In one way, they do all the cognitive and tedious work of collecting and processing information.
LLMs can now route a user request or prompt to different components—such as a tool, function, API, server, or database — to gather and provide a more meaningful, user-aligned response. This is called the application layer.
An application layer is where the raw LLM is made into a usable product. Now, an LLM itself is a product, but it is less usable if it doesn’t have a proper UI with chat capabilities.
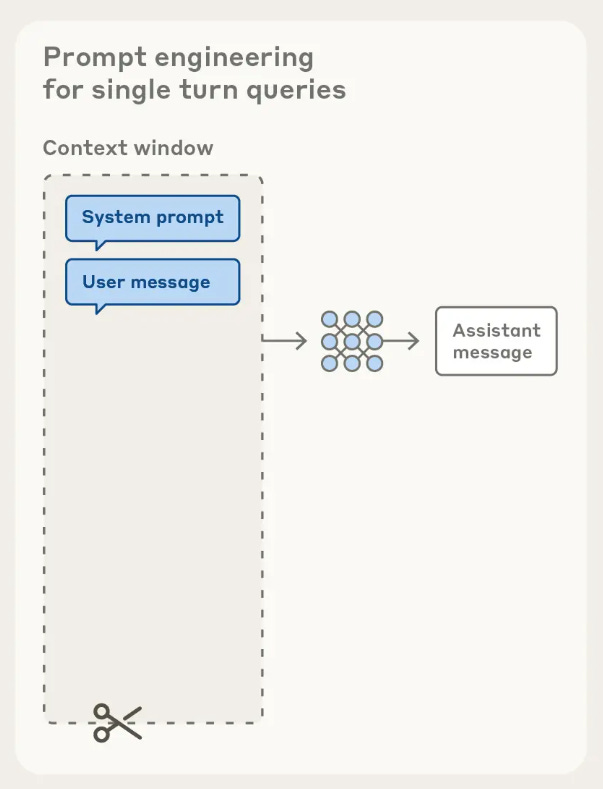
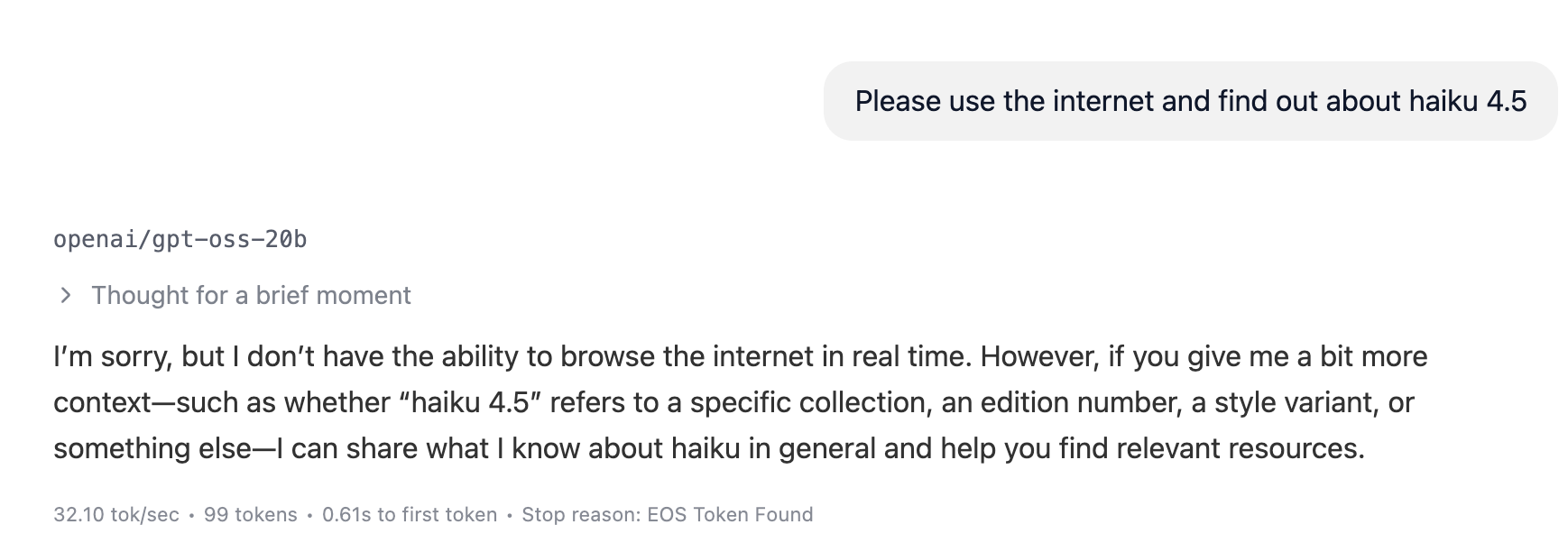
Along with that, LLM must be able to route user requests or prompts to different components. The LLMs we are aware of today, both open-source and private, are trained to possess these capabilities. However, in a product sense, these models can only harness those capabilities if application layers are attached to them.
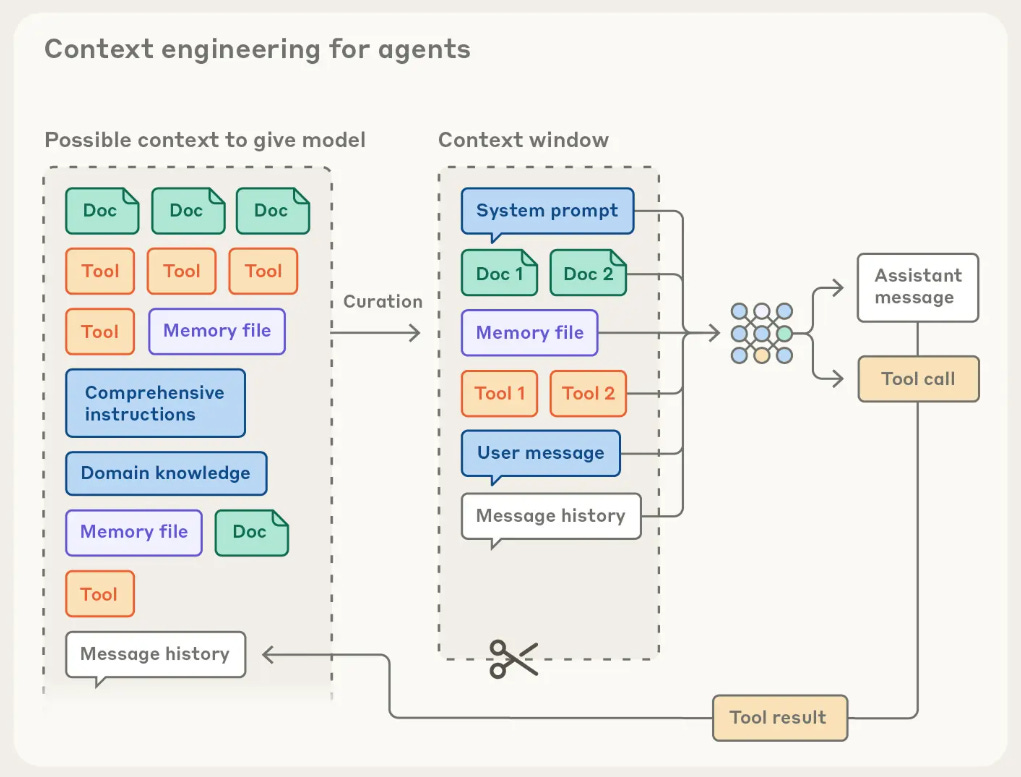
Now, depending on the vision and user feedback, the complexity of the application layer can significantly vary. For example, let’s assume that you are making a “running coach app.” The components that you might include are the following:
Weather data API: To inform the runner about the weather and the suitable time to run.
Nutritional API: To assist the runner in having a proper [light] meal with carbohydrates and water to stay hydrated.
Calendar API: To manage the runner’s schedule and running duration.
Runner’s Database: A database or RAG that stores all the running information will include running plans, exercises, etc.
Web Search Capabilities: To find the latest information about the marathon, season trends, etc.
Security: To protect the runners’ data or personal information.
The idea is to connect all these different components such that the LLM will be able to call these components when it needs external information. Information that was not used to train the LLM. This can get complex and tricky at times.
Also, understand that LLM gets more aligned to the vision and user needs when you attach domain-specific components or the application layer. Out of the box, these models are general, but the products are targeted to ICPs. To narrow down the LLM, add these application layers.
However, the more layers you have, the more the product is prone to failure. Meaning, the response from the LLM changes drastically in one component fails. This can lead to misformation, hallucinations, loss of trust, and sometimes sycophancy.
To address failure, you need to monitor or observe each component.
What is LLM Observability?
Observability, as the name suggests, is to observe LLM-based applications. More specifically, the application layer.
Let’s add some more nuances to this definition.
Observability is the practice of monitoring every layer of the application, right from the LLM, multiple APIs, databases, prompts, context, tools, etc. This helps us to see their behaviour in production, allowing us to identify which layer is causing the problem or is on the verge of failing.
Again, going back to the “running coach app,” it has various layers: weather data, notifications and calendar APIs, runner’s database, Web Search Capabilities, Security, upload functionality, etc.
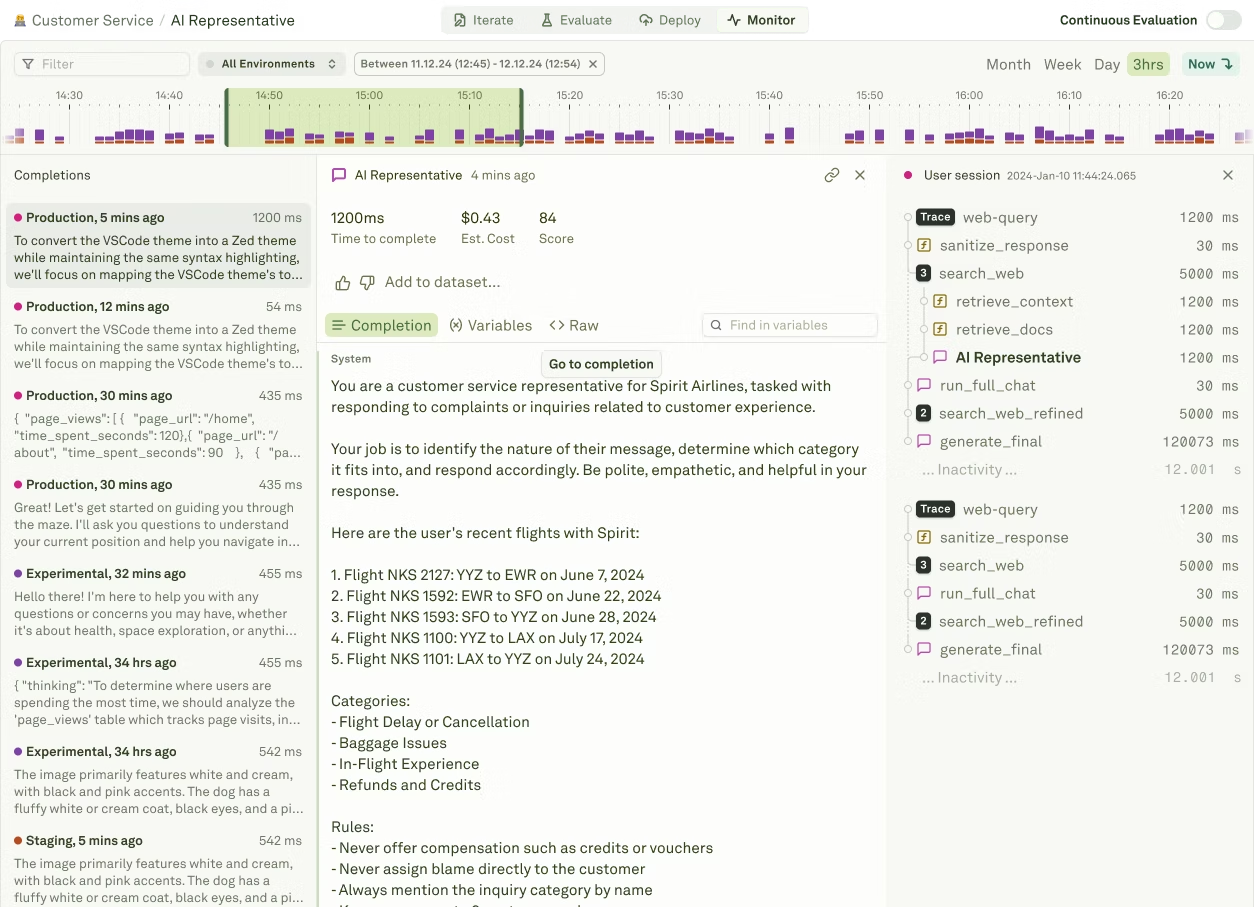
For an LLM-based application, all these components are somewhat attached via a prompt. Here is an example (system prompt):
<system>
You are RunningCoach, a performance-focused, safety-aware assistant for runners training. Optimize for clarity, personalization, and safety. Always:
> Ground plans in the runner’s zones and constraints.
> Check weather + schedule before prescribing runs.
> Recommend light, carb-forward pre-run meals and hydration.
> Protect user data; use least-privilege tool calls.
> Summarize next actions and set a notification if appropriate.
Tool Calling (deterministic rules):
> Weather (mandatory before any plan) → get_weather(location={{CityOrLatLng}}, start_iso={{PreferredStartLocal}}-15m, end_iso={{PreferredStartLocal}}+{{duration_min}}+15m).
> Session template (plans & drills) → rag_query(query=”{{WorkoutType}} {{MilesToday}} mi template”, filters={”workout_type”:”{{WorkoutType}}”,”miles”:{{MilesToday}},”phase”:”{{phase}}”}). If empty, use conservative WU/Main/CD.
If any required data is missing, infer from history; otherwise ask one concise question while still providing a useful default.
</system>Here you will find that prompt itself has reference to the tool calls. You will also notice that the through prompts tools are accessed. So, in case of failure, the first place to resolve any issue can and might be the prompt then the tool call description.
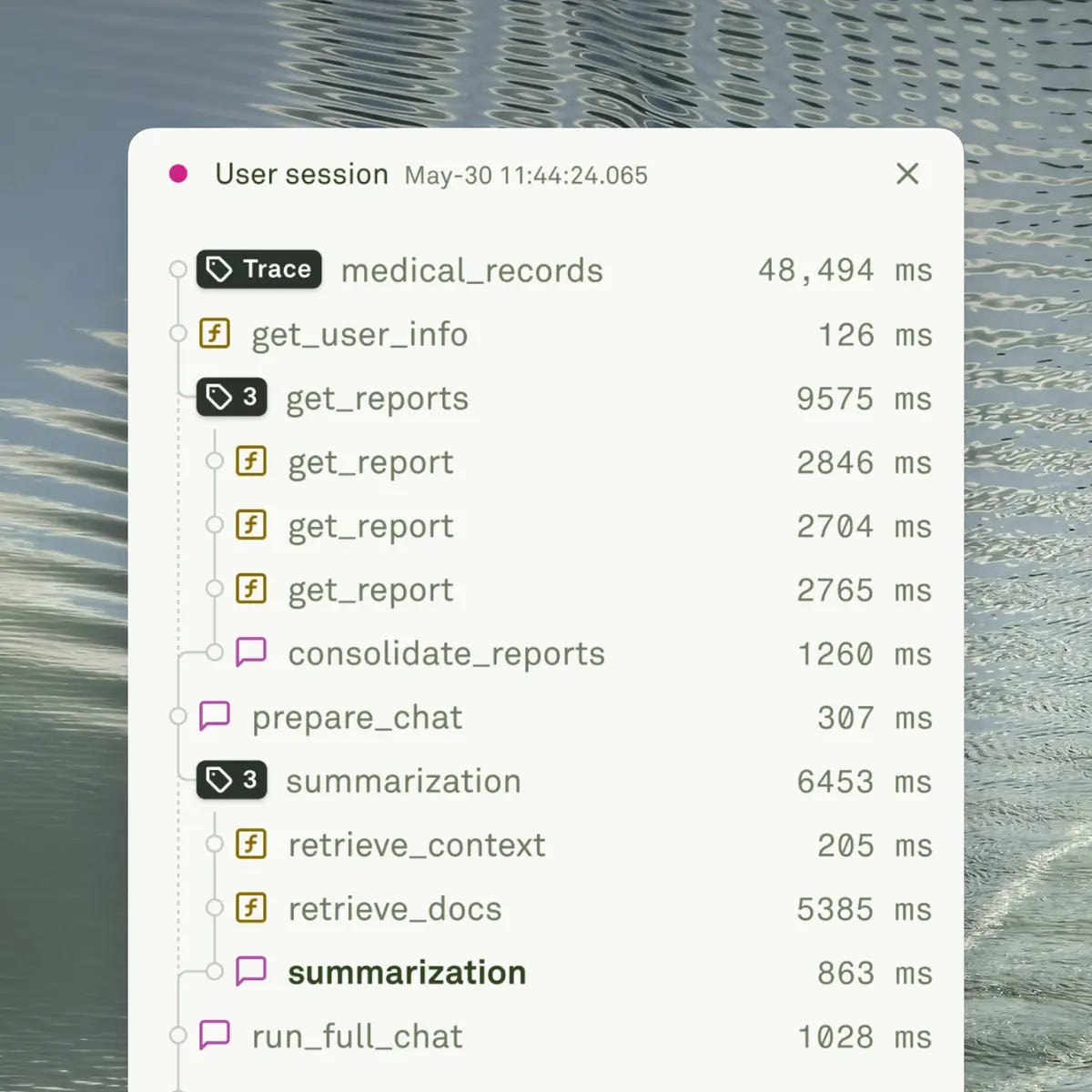
Essentially, through observability, you pinpoint the problem in each and every component.
Why You Need LLM Observability
Now, let’s discuss the importance of LLM observability and how helpful it can be.
Root Cause Analysis
When an LLM application produces unexpected results or fails entirely, visibility becomes critical. You’re left wondering about the source of the problem. Did your software contain an implementation error? Did your knowledge base or tool fail to return relevant information? Does the LLM struggle to understand your prompt?
Observability collects detailed data about everything happening inside your application. This data enables you to trace individual requests as they move through different components. You can follow the complete path of a user’s input through your system. Each step becomes visible and measurable.
This visibility transforms debugging from guesswork into systematic investigation.
Identifying Performance Bottlenecks
Users expect LLM applications to respond quickly. Chat assistants and code-completion tools must meet strict latency requirements. However, LLM systems contain numerous resource-intensive components that make speed challenging to achieve.
Monitoring individual components tells part of the story. You can track request rates, latency, and resource utilization separately. Yet this fragmented view doesn’t reveal where to focus your optimization efforts. Observability shows you where requests slow down across your entire system. You can identify specific bottlenecks and investigate unusual cases that deviate from normal patterns.
Assessing LLM Output Quality
Testing with sample requests can be deceptive. Responses may look satisfactory during initial testing phases. Real users inevitably encounter scenarios that produce unsatisfactory answers. Experience demonstrates that maintaining consistent quality requires multiple refinement cycles.
Observability helps you notice when outputs fall short of expectations. Automated evaluations can flag problematic responses automatically. You can correlate user feedback and actual user behavior with specific LLM outputs. This connection reveals patterns you might otherwise miss.
Continuous assessment drives ongoing quality improvements.
Detecting Response Patterns
Identifying individual failures is valuable.
Identifying patterns in those failures is transformative.
Observability reveals commonalities across multiple inadequate responses. These patterns expose systematic issues in your application.
With pattern recognition, you can optimize more strategically. You improve prompts based on actual failure modes. You refine processing steps where they consistently underperform. You enhance retrieval mechanisms that repeatedly miss relevant data.
Developing Effective Guardrails
Software engineering, prompt optimization, and fine-tuning solve many LLM problems. Some scenarios require additional safeguards. Observability identifies exactly where guardrails are needed most. You measure how well guardrails perform once implemented.
Observability also reveals the impact of guardrails on overall system performance. You understand tradeoffs between safety and functionality. This enables informed decisions about guardrail deployment.
Strategic guardrails strengthen application reliability.
Why Product Leaders Need LLM Observability
Product leaders stand at the confluence of engineering and usability. They are essentially the ones that can inherit the user-centric mind space. This mind allows them to align the model with prompts and domain-specific knowledge, which can be acquired by APIs, tool calls, RAGs, databases, context engineering, etc.
These application layers need monitoring. Engineers can come so close to making the layers workable seamlessly, but product leaders are the one that has a working knowledge [from the user’s perspective] of the product. As such, user experience plays a vital role in the usability of the app as well as the revenue generated from the user.
Now, consider that the product is causing a certain problem for the user. With an observability tool, you can trace the problem and fix it instantly. Let’s consider the “running coach” app. Let’s assume there is a latency issue that the user is facing when they are asking the app for a meal plan and post/pre-workout stretches for a 10:00 pm or 4:00 am winter run.
With observability, you can see what prompts the users are using. Sometimes they add a lot of details to the prompt [which is totally unnecessary]. This is creating a context overload, leading to unnecessary processing time.
As a product leader, you can add new features that ask for the time of the run, instead of the user explaining the whole scenario. You can also add a prompt that tells the LLM to provide 2 2-hour post-run plan for the runner. Then, you can also add a layer that notifies the user about:
The upcoming run.
Hydration regime.
Stretches to perform.
Breathing patterns.
This is what observability is useful for. It lets product leaders investigate and deeply understand the problem. Eventually, coming up with a new feature.
Insightful. How do you see the complexity of these aplication layers evolving with multi-modal LLMs? Great breakdown, really helps clarify the product perspective.