
The Missing Product Layer for Multi-Agent Systems
Why permissions, handoffs, and human control matter more than better prompts.

TLDR: Only 1 in 10 agentic AI use cases reached production last year, and the issue is not a model-capability problem. Nor a better model. It is the governance layer above the models: who can do what, when to delegate, what humans can see, and how to recover. This article introduces the Four Control-Plane Primitives (permissions, handoffs, visibility, and recovery) and walks through what each one means for AI PMs and engineers before a multi-agent workflow ships. If your PRD does not define delegation boundaries and escalation conditions, it is not ready for a multi-agent workflow.

When one agent becomes five, the problem changes. You are no longer just designing outputs. You are designing permissions, handoffs, visibility, and trust. And most teams discover this only after they've shipped.
Multi-agent systems are AI architectures in which multiple specialized agents collaborate toward a shared goal. Each agent handles a distinct subtask, calls its own tools, and operates within its own context window, while a coordinating layer routes work between them.
Gartner named multi-agent systems a top 10 strategic technology trend for 2026. They predicted that 40% of enterprise applications will include task-specific agents by year’s end, up from less than 5% in 2025. Yet only one in ten agentic AI use cases reached production in the past year. The problem between prototype and production is not a model-capability issue, but a governability issue.
The models are not the hard part. The hard part is building what sits above them:
The layer that governs who can do what, when an agent can delegate.
How work transfers between agents, what humans can see
How the system recovers when something goes wrong.
This article calls that layer the product control plane. It proposes a practical framework built around four primitives every multi-agent product must get right, and walks through what that means for AI PMs writing requirements and engineers deciding what to instrument.
Why Single-Agent Product Thinking Breaks In Multi-Agent Systems
A single AI agent operates with a knowable mental model. It has one context window, one permission surface, one responsibility boundary, and one output for the user to evaluate.
When that agent behaves unexpectedly, the failure is usually traceable:
You can examine the prompt,
Inspect the tool calls, and
Identify where the reasoning went wrong.
The product surface area is bounded.
Multi-agent systems architecture is categorically different.
A January 2026 survey on orchestration and enterprise adoption described the orchestration layer as “the control plane of a multi-agent system, transforming autonomous components into a coherent, goal-directed collective.”
It warned that without it, “even highly capable agents risk duplication of effort, logical inconsistency, or unbounded autonomy that diverges from the system’s objectives”.
The unbounded autonomy problem is not theoretical. Anthropic’s analysis of agent behavior on their public API, published in early 2026, found that the 99.9th percentile session length grew from 10 to 40 minutes between October 2025 and January 2026. In the same period, the average number of human interventions per session dropped from 5.4 to 3.3. Both trends point in the same direction: agents are operating more autonomously for longer periods with less human contact. That is valuable. It is also the precise condition under which single-agent mental models break down entirely.
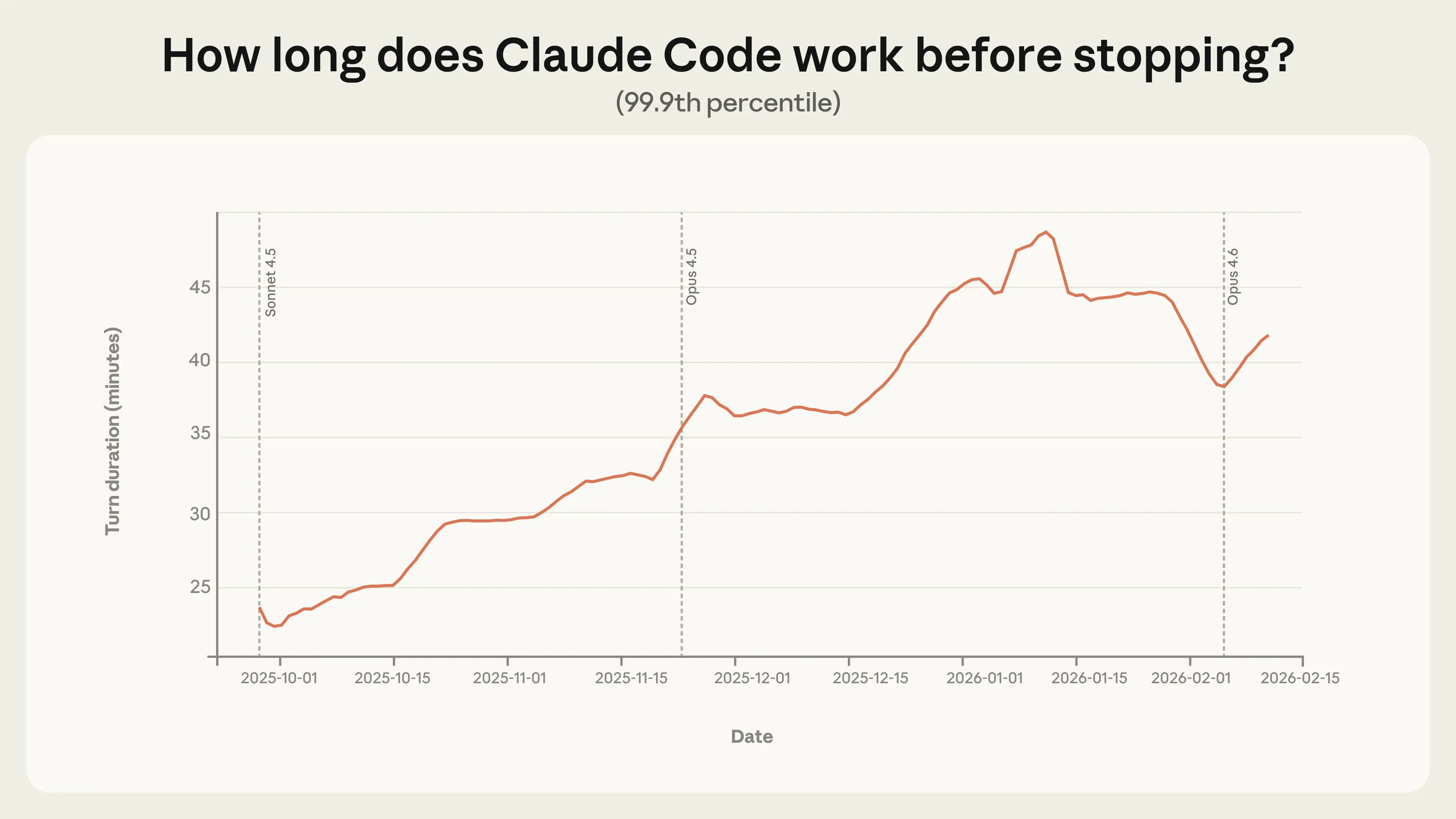
When a product team thinks of their system as “an assistant that uses tools,” they are designing for a world where one entity has full context and one person is watching. When that same system starts delegating to subagents, the complexity multiplies.
Think this: each subagent has partial context, different tool access, and its own failure modes.
Every assumption embedded in the original design becomes a liability. Users cannot see the delegation chain. The PMs have no requirement for what happens when a subagent fails. The engineers have no instrumentation for handoff-level errors.
The product seems to work until it stops working for no apparent reason.
Delegation Changes The Product Surface Area More Than Most Teams Expect
Delegation sounds like a routing problem.
It is not.
Delegation is a transfer of authority, context, and responsibility across a trust boundary. And every one of those transfers expands the product surface area in ways that have to be explicitly designed for.
A February 2026 research paper on AI delegation mechanics put this clearly: once a multi-agent AI system delegates work to a subagent, the system must account for “the delegator’s degree of belief in the delegatee’s” reliability. That trust cannot simply be assumed. In practice, it has to be constructed through three decisions that teams routinely skip:
Task packaging: When a lead agent hands work to a subagent, it must decide what context to transfer. A subagent that receives too little context will misinterpret its scope. One that receives the wrong context will act on incorrect assumptions. Neither failure surfaces as an obvious error; both surface as outputs that are subtly but consequentially wrong.
Authority boundaries. The subagent needs to know what it is allowed to do independently and when it must escalate. Without explicit boundaries, subagents either become overly cautious, interrupting frequently and defeating the purpose of delegation, or overreach, taking actions the user never authorized.
Coordination overhead. Anthropic’s engineering team, in describing their multi-agent research system, noted that early versions made errors like “spawning 50 subagents for simple queries” and “scouring the web endlessly”. The orchestrator had no clear rules about when delegation was appropriate and when it was wasteful. The system behaved rationally within its local context and irrationally at the product level.
These three problems are not solvable with better prompts. They are solvable with better product design. That means specifying them before the first subagent is built.
The Four Control-Plane Primitives: Permissions, Handoffs, Visibility, Recovery
A production-ready multi-agent product needs four things to work together. Each is both a product decision and an engineering problem.
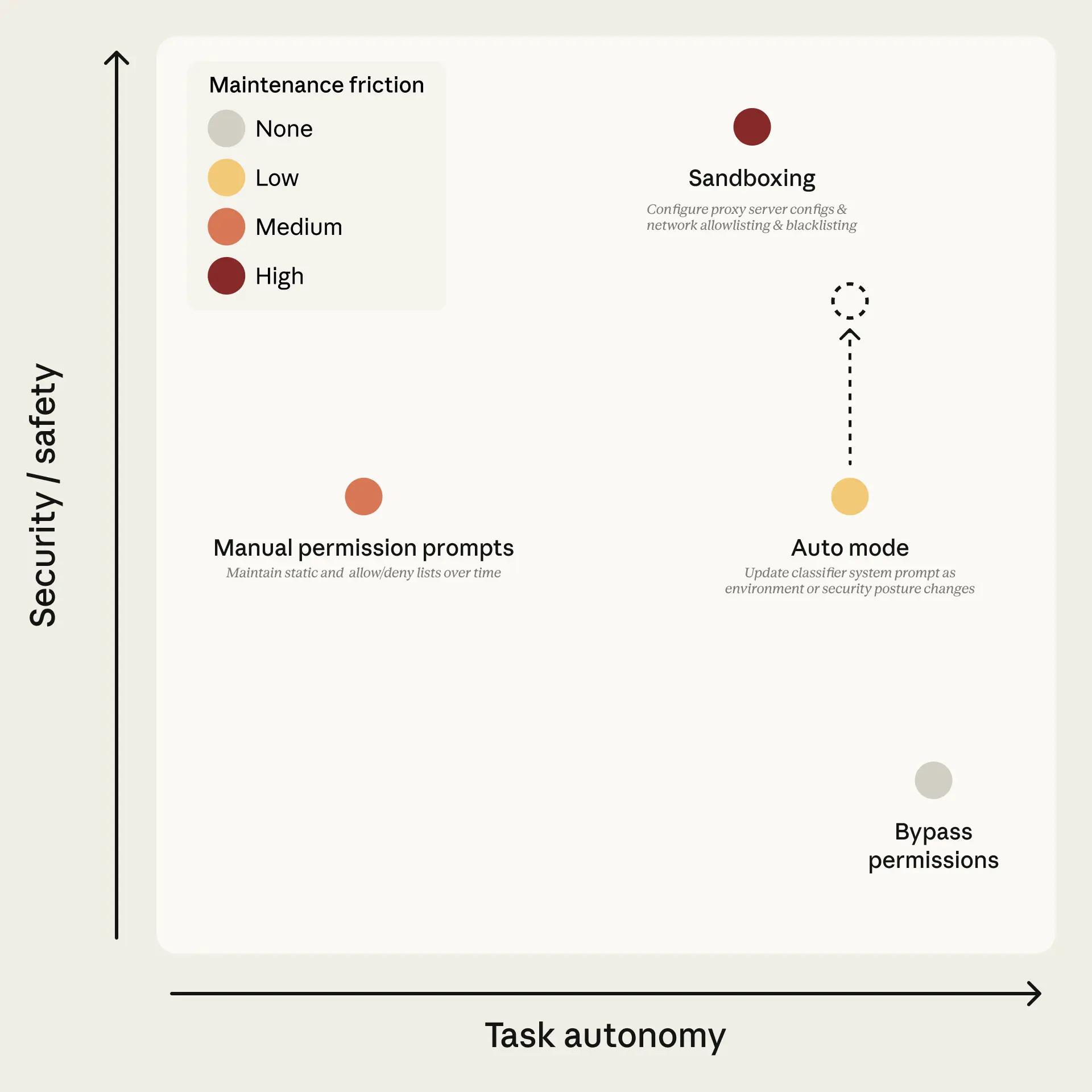
Permissions
Permissions define what each agent is allowed to do:
Which tools can it call?
Which data can it read or write?
Which actions can it initiate without asking for approval?
The failure mode when permissions are weak is not dramatic. It is quiet. An agent with excessive permissions takes actions that fall within its technical authority but outside the user’s intent.
An agent with insufficient permissions interrupts constantly and erodes the value of autonomy. And when permissions are not designed per-agent, the risk compounds.
When all agents in a chain inherit the same flat permission set, a single compromised or misconfigured subagent can propagate unauthorized actions through the entire chain.
The research on this is direct. A February 2026 paper on delegation mechanics argued that permission design must extend beyond binary access to semantic constraints. Meaning, “access defined not just by the tool or dataset, but by the specific allowable operations. For example, read-only access to specific rows, or execute-only access to a specific function”.
The same paper noted that permissions must be dynamic rather than static: “access rights are not static endowments but dynamic states that persist only as long as the agent maintains the requisite trust metrics.”
For PMs: permissions are a product and compliance decision, not a backend default. The permission surface of a multi-agent system determines what the product can do to a user’s data, systems, and environment without the user's consent. That is a business risk decision.
For engineers: implement least-privilege defaults at the subagent level. Each agent should receive only the tools and data access it needs for its specific task, not the full tool set of its orchestrator.
Handoffs
A handoff is the transfer of execution from one agent to another: from the orchestrator to a subagent, from one specialist to another, or from an agent back to a human.
Handoffs are the highest-risk moments in any multi-agent workflow because they combine three failure conditions at once:
Context may be incomplete,
Authority may be ambiguous, and
Neither agent may recognize that the transfer has gone wrong.
A March 2026 trace-based assurance framework for agentic AI orchestration identified five failure classes in multi-agent systems. Three of them manifest specifically at handoff boundaries: coordination failures such as loops and deadlocks, role drift in long-horizon workflows, and error propagation across agents.
The paper described handoffs as moments where “planner, verifier, and action roles may drift, loop, or deadlock across turn boundaries.”
The quality of context transferred at a handoff is ultimately a context engineering problem: what information the receiving agent needs, in what format, and at what level of compression. Get it wrong, and the subagent acts on incorrect premises with full confidence.
Anthropic’s auto mode for Claude Code addresses handoff risk directly, running safety classifiers at both ends of every subagent handoff: when work is delegated out and when results come back. The outbound check catches compromised or unauthorized delegation. The return check catches subagents that were benign at delegation but compromised mid-run by the content they retrieved. When the classifier flags repeatedly, the system escalates to human review.
For PMs: handoffs are product moments, not just engineering events. They involve responsibility transfer, potential user confusion, and invisible decisions. Specify what the system must communicate to the user when a handoff occurs, and under what conditions a handoff should require explicit approval.
For engineers: log every handoff with source agent, destination agent, task specification passed, and context transferred. Treat a handoff with incomplete context transfer as a failure event, not a warning.
Visibility
Visibility is the ability for users, PMs, engineers, and operators to understand what the system is doing and why. In a single-agent product, visibility is a nice-to-have. In a multi-agent system, it is the mechanism by which humans maintain meaningful oversight.
Anthropic’s framework for trustworthy agents identifies transparency as a structural requirement: “Humans need visibility into agents’ problem-solving processes. Without transparency, a human asking an agent to ‘reduce customer churn’ might be baffled when the agent starts contacting the facilities team”. That example is not abstract. Without step-level visibility, users cannot assess whether the agent is pursuing the right strategy, and they cannot intervene before an undesirable action completes.
AWS describes the production consequence in their analysis of agent evaluation at Amazon: “Quality issues in production often surface in ways that traditional monitoring misses”. Status codes, response times, and token counts can all show green while the product fails at the reasoning and coordination level.
Visibility requires traces that capture individual agent steps, tool calls, and handoff events, not just the final output. It also requires activity summaries that translate those traces into language that users can understand. State awareness tells users where they are in a multi-step workflow.
For PMs: define what the user sees at each stage of a multi-agent task. A task that runs for ten minutes across four subagents with no user-facing updates is not invisible infrastructure. It is a broken product experience.
For engineers: instrument at the agent step level, not just the request level. Agent observability should capture what each agent received, what it called, and what it returned, with enough granularity to reconstruct the full execution trace after the fact.
Recovery
Recovery is what the system does when something goes wrong:
When a subagent fails, when a handoff delivers bad context,
When an action hits a permission boundary, or
When the workflow reaches a state it was not designed to handle.
Most teams design recovery as a single fallback: “show an error message.” That is not recovery. It is abandonment.
A production-grade multi-agent system needs at least three explicit recovery paths: retry with modified parameters, fallback to a simpler workflow, and escalation to human review.
The escalation condition matters as much as the escalation mechanism. Anthropic’s data on agent autonomy found that experienced users shift over time “from approving individual actions to monitoring what the agent does and intervening when needed”. That is a healthy trust pattern. But it only works if the system surfaces enough signal for humans to know when intervention is warranted.
For PMs: define the escalation trigger conditions before launch. What agent state, output score, or action type should route to human review? What does the product communicate to the user when escalation happens?
For engineers: implement circuit breakers for runaway delegation chains. Log every permission denial and fallback logic event as first-class telemetry, not as debug noise. Recovery paths that are not monitored cannot be improved.
What AI PMs Should Put In The PRD For A Multi-Agent Workflow
Most PRD templates were built for single-feature, single-agent products. They do not account for the coordination, authority, and visibility questions that multi-agent systems introduce. Before a multi-agent workflow goes to engineering, the PRD should answer each of the following:
Agent role definitions: What is each agent responsible for, what tools does it have access to, and what is it explicitly prohibited from doing?
Permission boundaries: Which actions require implicit approval, which require explicit user confirmation, and which are always blocked regardless of context?
Delegation conditions: Under what circumstances does the orchestrator delegate to a subagent versus handling the task directly, and what criteria govern that decision?
Handoff specifications: What context must be packaged when work transfers between agents, what does the receiving agent need to know to act correctly, and who is responsible for the outcome once a handoff occurs?
User-visible states: What does the user see at each stage of the workflow, which intermediate states are communicated, and what happens to the UI during a multi-minute agent run?
Fallback and escalation flows: At what point does the system route to human review, who owns the escalation, and what does the product communicate when a fallback triggers?
Success definition: What does “done” mean in a multi-step, multi-agent task? What is the acceptance criterion, and at what point is the task complete enough to return control to the user?
That is the product specification layer. The engineering layer that makes it observable and recoverable before launch is equally specific, and equally often skipped.
What AI Engineers Should Instrument, Evaluate, And Audit Before Launch
Instrumentation decisions for multi-agent systems differ from single-agent products in scope and consequence. Before a multi-agent workflow goes to production, the following should be in place:
Agent-step tracing: Capture every subagent action as a trace event with parent agent ID, timestamp, and input/output payloads. Traces should reconstruct into a full execution graph.
Handoff logging: Log every handoff with source agent, destination agent, task specification, and context payload. Flag incomplete context transfers as failure events, not warnings.
Permission denial telemetry: Capture every blocked action with agent identity, attempted action, and the policy rule that blocked it. Permission denials are diagnostic signals about where the system design is breaking down, not noise.
Trajectory-level evaluation: Output scoring at the final response level misses failures that happen inside the workflow. Evaluation of AI agents should run across the full sequence of agent decisions, not just at the endpoint. Amazon’s agent evaluation framework covers both individual agent performance and collective system dynamics.
Fallback event monitoring: Log and trend every retry, workflow fallback, and escalation. A spike in fallback events is often the first signal of a model update, a prompt regression, or a new user behavior pattern that the system was not designed for.
Auditability before GA: Any engineer should be able to reconstruct what happened in any session from traces alone, without asking the user. If that reconstruction is not possible, the instrumentation is not sufficient for production.
Launch gate: Define minimum passing thresholds on trajectory evaluation scores, fallback rate, and permission denial rate. Treat them as a hard gate. A multi-agent system that passes output-level quality checks but fails at the trajectory or handoff level is not production-ready.
Final Thought
The industry has spent the past two years optimizing models. The next constraint is not model capability.
Research from Amazon’s internal deployments shows that organizations that invest in governance and evaluation are an order of magnitude more successful in reaching production than those that do not. The Linux Foundation’s Agent-to-Agent Protocol has already crossed 150 supporting organizations in its first year, a signal that the industry has recognized coordination governance as an infrastructure problem, not a product differentiator.
The teams that ship reliable multi-agent products will not be the ones with the most capable agents. They will be the ones who designed for governable autonomy:
Specifying permissions before deploying,
Instrumenting handoffs before trusting them,
Defining recovery before needing it, and
Giving users enough visibility to trust what the system was doing on their behalf.
That is the product layer most teams skip. It is also the one that determines whether a multi-agent system becomes a product or remains a prototype.