
Reasoning Prompt Engineering Techniques in 2025
The 9 Techniques Every Product Manager Needs to Ship Smarter AI Features


Introduction
Reasoning prompts are specialized instructions or contexts provided to the LLMs. These guide language models through step-by-step logical thinking. They transform LLMs from pattern-matching systems into deliberate problem solvers.
Product teams face a critical challenge today. Standard prompts often produce hallucinated outputs or logical errors when tackling complex tasks. Most of the time, reasoning failures occur in the first attempt when models make premature conclusions.
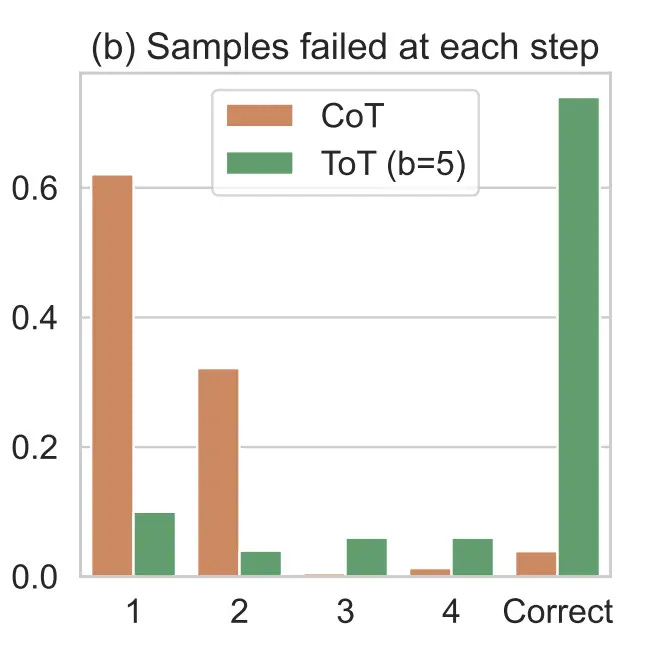
Failed reasoning leads to customer support escalations. It creates compliance risks in regulated industries. Teams spend weeks debugging AI features that seemed promising in demos but break in production.
Reasoning prompt engineering techniques offer a systematic solution. This field has evolved rapidly since 2022. What started with simple Chain-of-Thought prompting now includes nine distinct approaches.
Each technique addresses specific reasoning challenges:
Zero-shot prompting eliminates example bias.
Few-shot prompting provides learning through examples.
Chain-of-thought creates transparent logic traces.
Self-consistency reduces errors through majority voting.
Tree-of-thought explores multiple solution paths.
ReAct combines reasoning with external tool calls.
Least-to-most breaks complex problems into simpler parts.
Decomposed prompting creates modular reasoning workflows.
Automatic reasoning and tool-use enable autonomous problem solving.
This guide provides a decision framework for selecting the right technique. The goal is shipping AI features that reason reliably rather than just sounding convincing.
Modern LLM reasoning accuracy depends on choosing the right prompting strategy for your specific use case.
Why Reasoning Prompts Matter in 2025
The 2025 AI landscape reveals dramatic performance leaps when teams implement structured reasoning techniques. OpenAI’s o3 model achieved an unprecedented 87.5% accuracy on the ARC-AGI benchmark, surpassing previous scores of below 30%. DeepSeek R1 scored 97.3% on MATH-500 mathematical reasoning tasks. These gains translate directly to enterprise value.
Product teams now ship features faster using reasoning-enabled workflows. The secret lies in fewer debugging cycles.
Traditional prompts produce hallucinated outputs that create support escalations. Teams spend weeks fixing AI features that seemed promising in demos but broke in production.
Reasoning prompts eliminate this waste. Self-consistency techniques reduced major reasoning mistakes across production deployments. Chain-of-thought prompting tripled accuracy on complex math problems. These improvements compound rapidly.
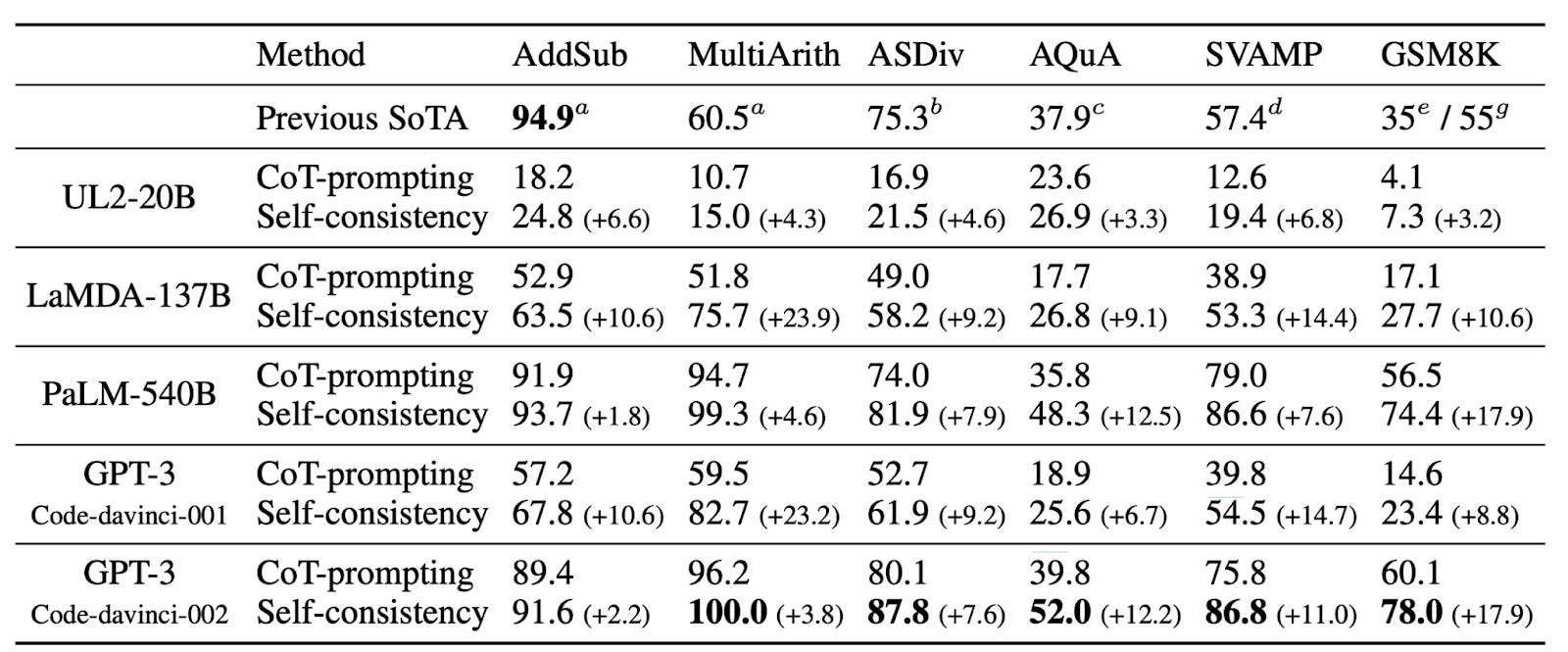
Consider the business impact metrics:
Support ticket reduction: Fewer escalations when LLM explains its reasoning process.
Development velocity: Features launch faster when debugging becomes systematic.
Compliance readiness: Audit trails satisfy regulatory requirements in finance and healthcare.
User trust: Transparent reasoning builds confidence in AI-powered decisions.
The ARC-AGI-2 benchmark poses an even greater challenge. Current reasoning models score only under 10%. This represents a massive opportunity for teams mastering advanced prompting techniques.
Human-level reasoning accuracy now depends on selecting the right prompting strategy rather than relying on model improvements. The competitive advantage goes to teams who systematically apply these techniques across their AI features.
Side-by-Side Scorecard
Selecting the right prompt engineering comparison requires understanding each technique's trade-offs. This scorecard helps teams choose optimal approaches based on project constraints and accuracy requirements.
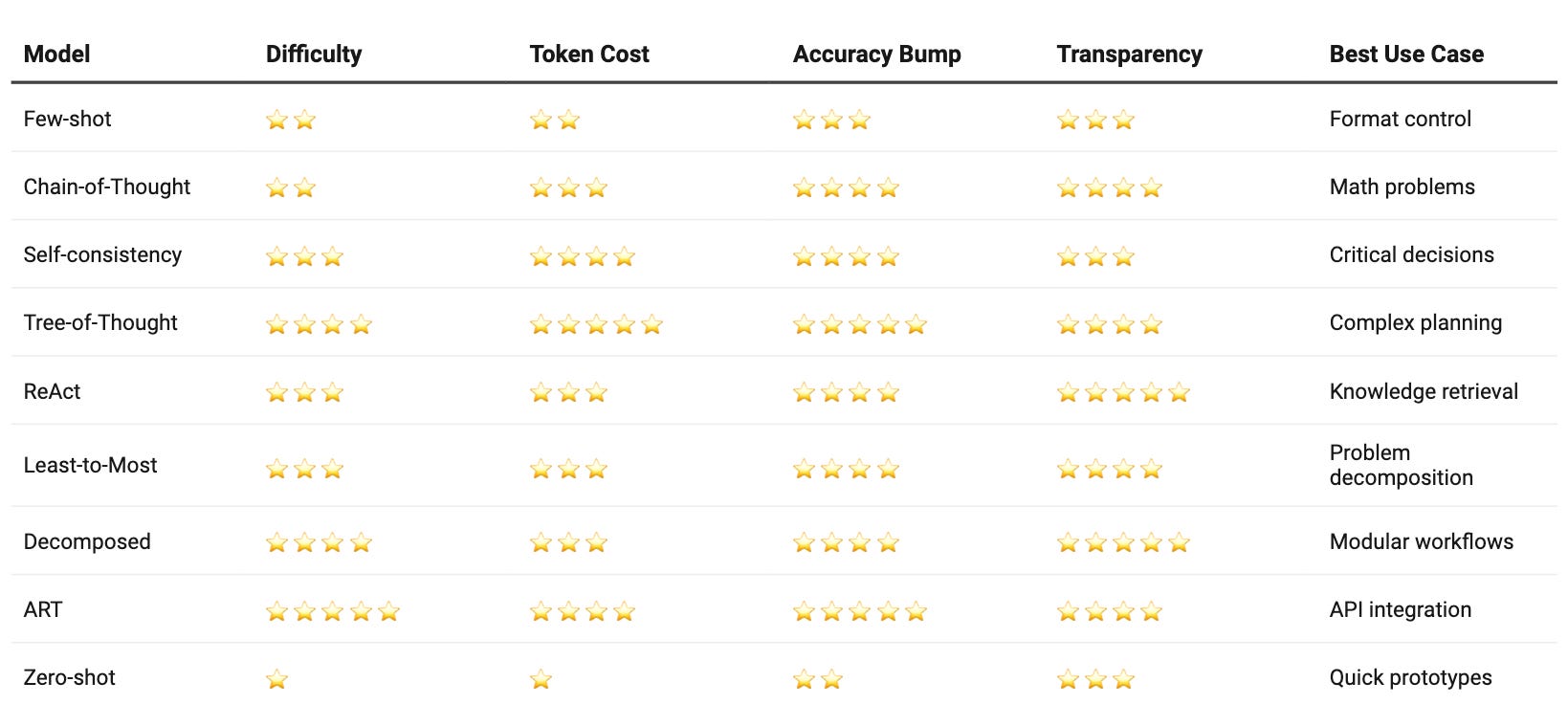
Quick Selection Guide:
High accuracy needed: Tree-of-Thought or ART.
Budget constraints: Zero-shot or Few-shot.
Transparency required: ReAct or Decomposed.
Simple tasks: Zero-shot or Chain-of-Thought.
Complex reasoning: Tree-of-Thought or Least-to-Most.
Overview of Prompting Technique
In this section, I will briefly describe each of the nine prompting techniques. To get an in-depth understanding of these techniques, you can click the link provided at the end of each technique.
Zero-Shot Prompting

Zero-shot prompting asks models to perform tasks using only instructions, without any examples. You simply describe what you want and let the model's training handle the rest.
Key Benefits:
No example collection needed: Skip the time-consuming process of finding representative demonstrations.
Reduced bias: Avoid misleading the model with poorly chosen examples that don't match your actual use cases
Common Pitfall: Performance typically trails well-crafted few-shot approaches by 10-15%. Simple tasks like "classify this email as urgent/normal" work well. Complex reasoning often requires additional techniques.
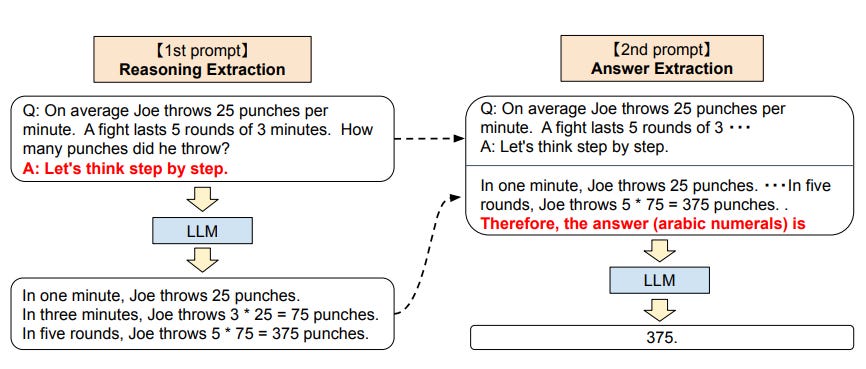
Adding "Let's think step by step" to prompts can dramatically improve results. Research shows significant accuracy gains on reasoning tasks with this simple addition.
Zero-shot works best for quick prototypes and straightforward classification tasks where you need immediate results without prompt engineering overhead.
Read more about Zero-shot prompting here.
Few-Shot Prompting

Few-shot prompting provides 2-5 examples within your prompt to demonstrate the desired response pattern. The model learns both the task and output format from these demonstrations.
Key Benefits:
Format control: Examples show exact output structure, ensuring consistent responses across different inputs.
Rapid adaptation: Models adjust to new tasks without fine-tuning, enabling faster deployment cycles.
Common Pitfall: Example order significantly affects performance. Poor examples can degrade results worse than providing no examples at all.
Research shows optimal performance with 3-5 diverse examples. More examples rarely help and waste valuable context window space.
Few-shot excels for specialized domains like legal document analysis or technical writing where specific formats matter. It bridges the gap between zero-shot simplicity and fine-tuning complexity.
Read more about Few-shot prompting here.
Chain-of-Thought Prompting
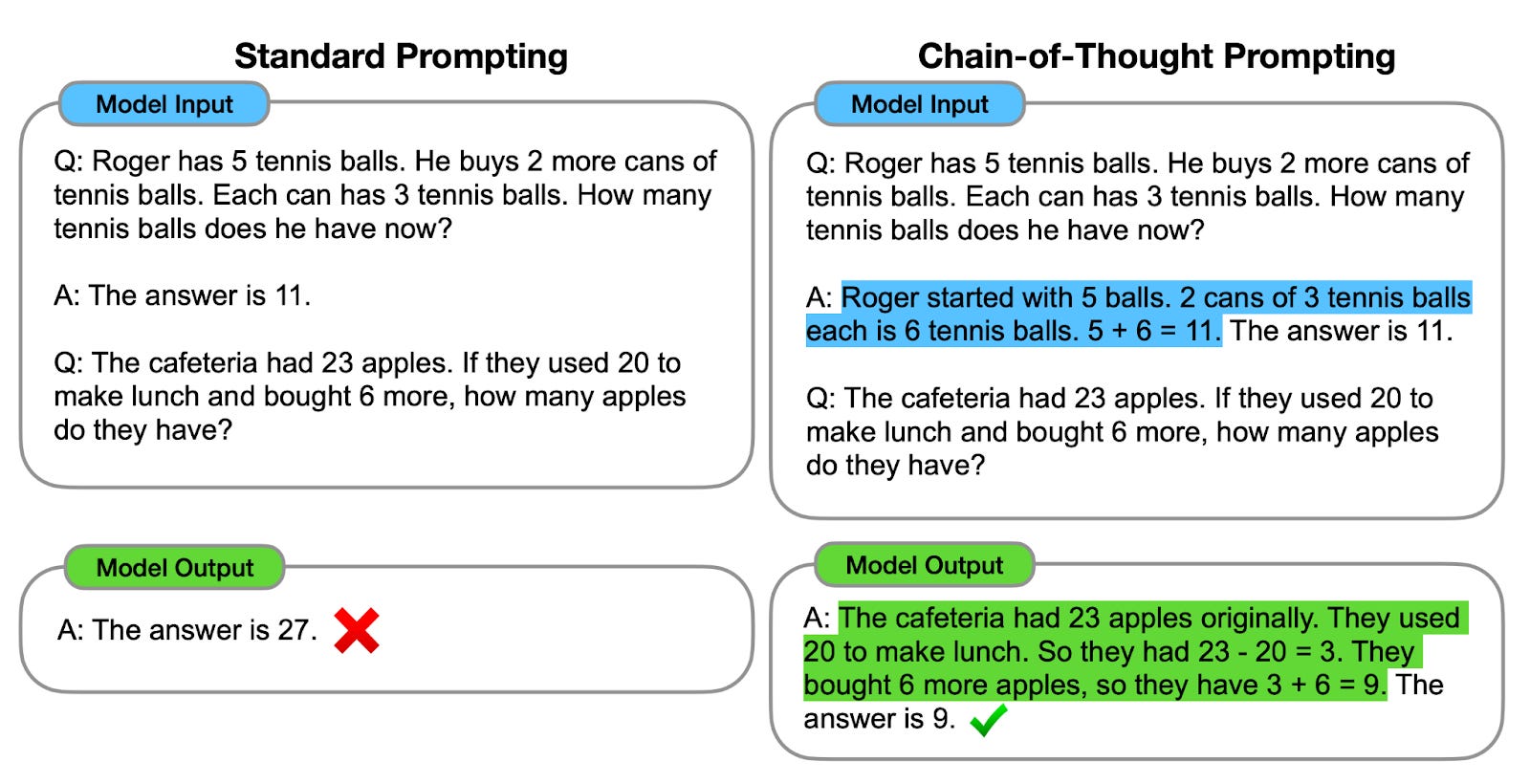
Chain-of-thought prompting guides models through step-by-step reasoning before reaching conclusions. Instead of jumping directly to answers, models show their logical progression.
Key Benefits:
Dramatic accuracy gains: Performance often doubles or triples on complex reasoning tasks like math word problems.
Transparent reasoning: Clear audit trails for debugging and compliance requirements in regulated industries.
Common Pitfall: Token costs increase 3-5x due to lengthy reasoning chains. Simple tasks may perform worse with unnecessary overthinking.
Adding phrases like "Let's work through this step-by-step" triggers the reasoning behavior. The technique transforms opaque AI decisions into interpretable logical sequences.
Chain-of-thought works best for multi-step problems requiring sustained logical thinking, mathematical calculations, or scenarios where explainability matters.
Read more about Chain-of-thought prompting here.
Self-Consistency Prompting
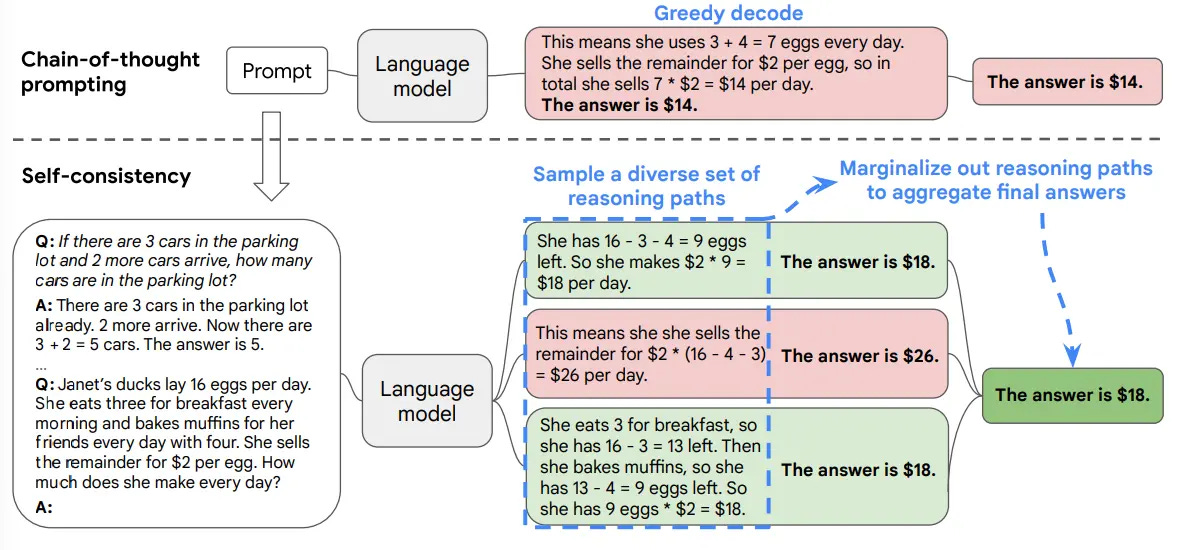
Self-consistency prompting generates multiple reasoning paths for the same problem, then selects the most frequent answer through majority voting. This technique reduces random errors by exploring diverse solution approaches.
Key Benefits:
Error reduction: Decreases reasoning mistakes compared to single-path approaches through statistical averaging.
No training required: Works with any pre-trained model without additional fine-tuning or specialized datasets.
Common Pitfall: Computational costs multiply linearly with the number of reasoning paths. Running 10 parallel chains increases API expenses 10x while adding significant latency.
The technique works by sampling multiple outputs at temperature 0.7, extracting final answers, and counting frequencies. Most gains appear with 5-10 samples.
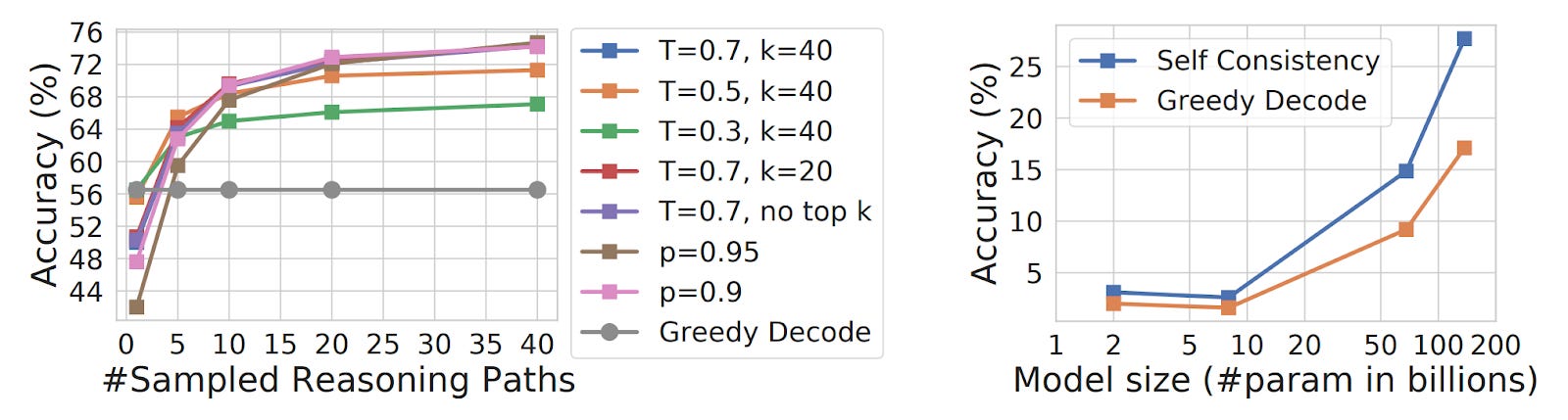
Self-consistency excels for critical decisions where accuracy outweighs cost concerns, such as financial analysis or medical diagnosis support systems.
Read more about Self-consistency prompting here.
Tree-of-Thought Prompting
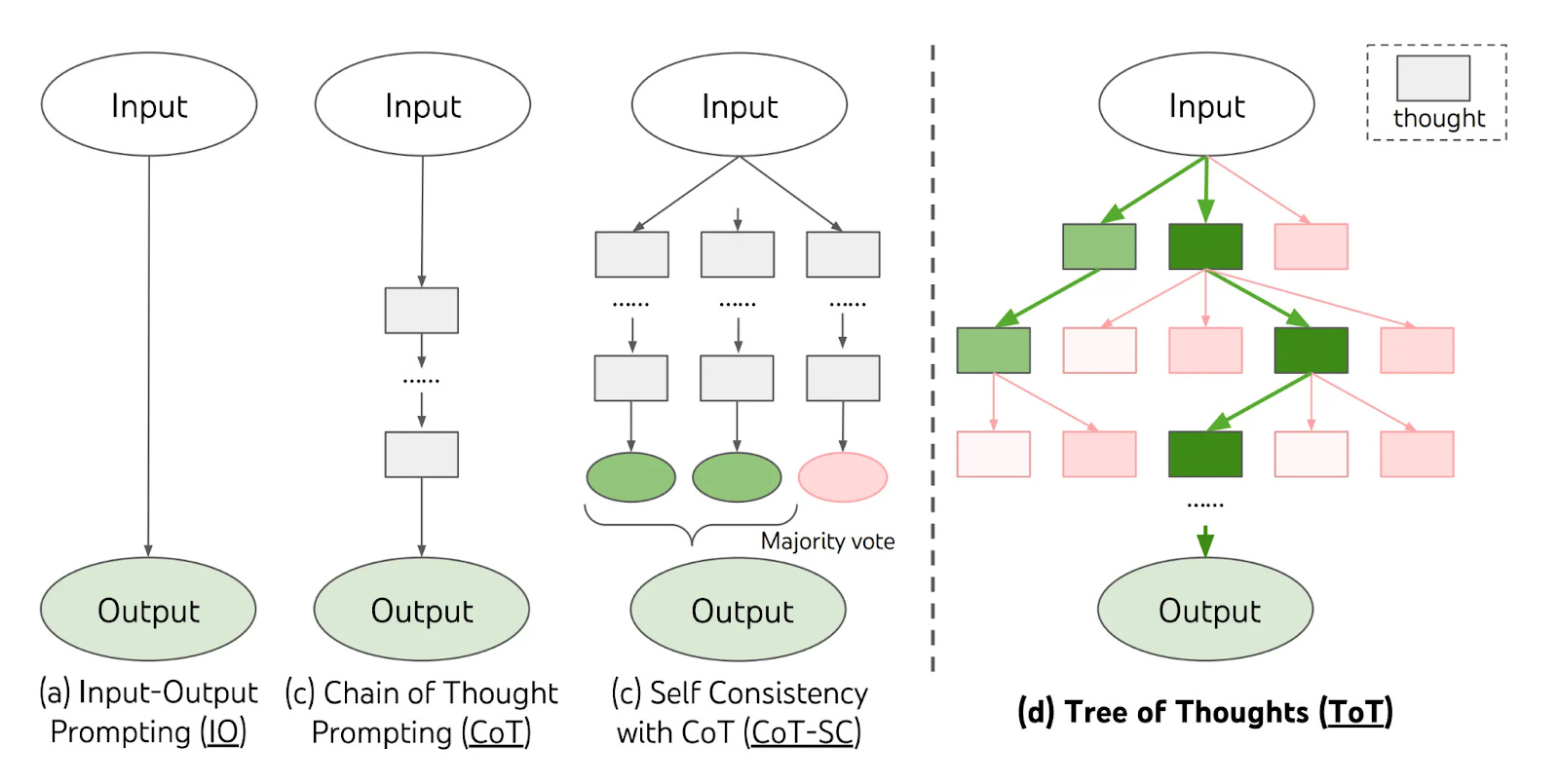
Tree-of-thought prompting maintains multiple reasoning branches simultaneously, allowing models to explore different solution paths and backtrack when needed. Unlike linear reasoning, this creates a searchable tree structure.
Key Benefits:
Strategic planning: Enables lookahead and course correction when initial approaches fail or prove suboptimal.
Superior complex reasoning: Achieves 74% success on Game of 24 puzzles versus 4% for standard chain-of-thought.
Common Pitfall: Extremely expensive computationally, requiring 5-100x more tokens than basic prompting due to extensive tree exploration and evaluation.
The framework uses breadth-first or depth-first search to navigate solution spaces. Each node represents a partial solution that gets evaluated before expansion.
Tree-of-thought works best for complex planning tasks, creative problem solving, or scenarios requiring extensive exploration of solution alternatives.
Read more about Tree-of-thought prompting here.
ReAct Prompting
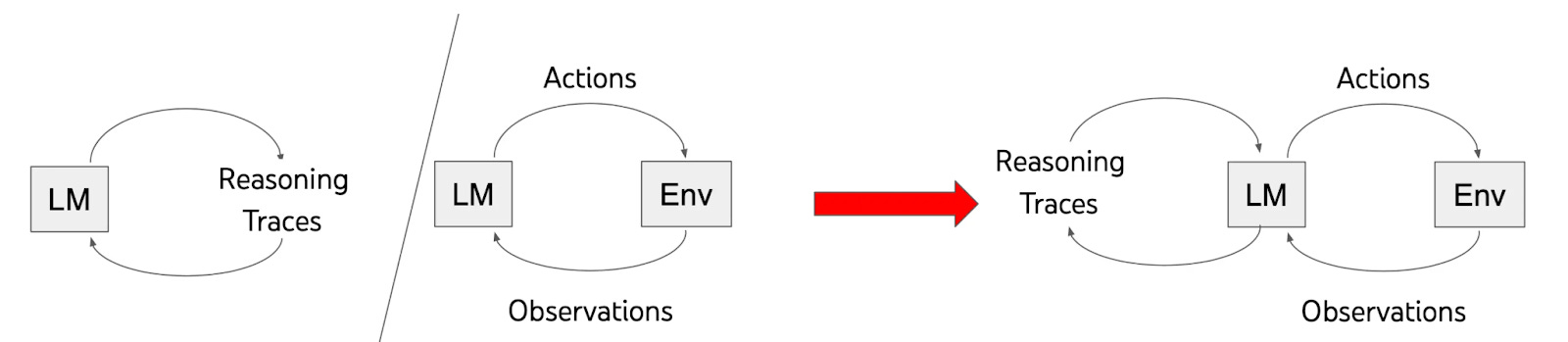
ReAct prompting interleaves reasoning traces with external tool actions, creating a dynamic think-act-observe cycle. Models reason about problems while accessing real-world information through API calls.
Key Benefits:
Grounded outputs: Eliminates hallucination by connecting to authoritative data sources and live information feeds.
Real-time capabilities: Accesses current information that wasn't available during model training through external tools.
Common Pitfall: Depends heavily on reliable external APIs and tools. System failures cascade when search engines or databases become unavailable.
The technique follows "Thought → Action → Observation" loops until task completion. Each cycle builds context for subsequent reasoning steps.
ReAct excels for fact-checking applications, research assistance, and any scenario requiring current information beyond the model's training cutoff date.
Read more about ReAct prompting here.
Least-to-Most Prompting
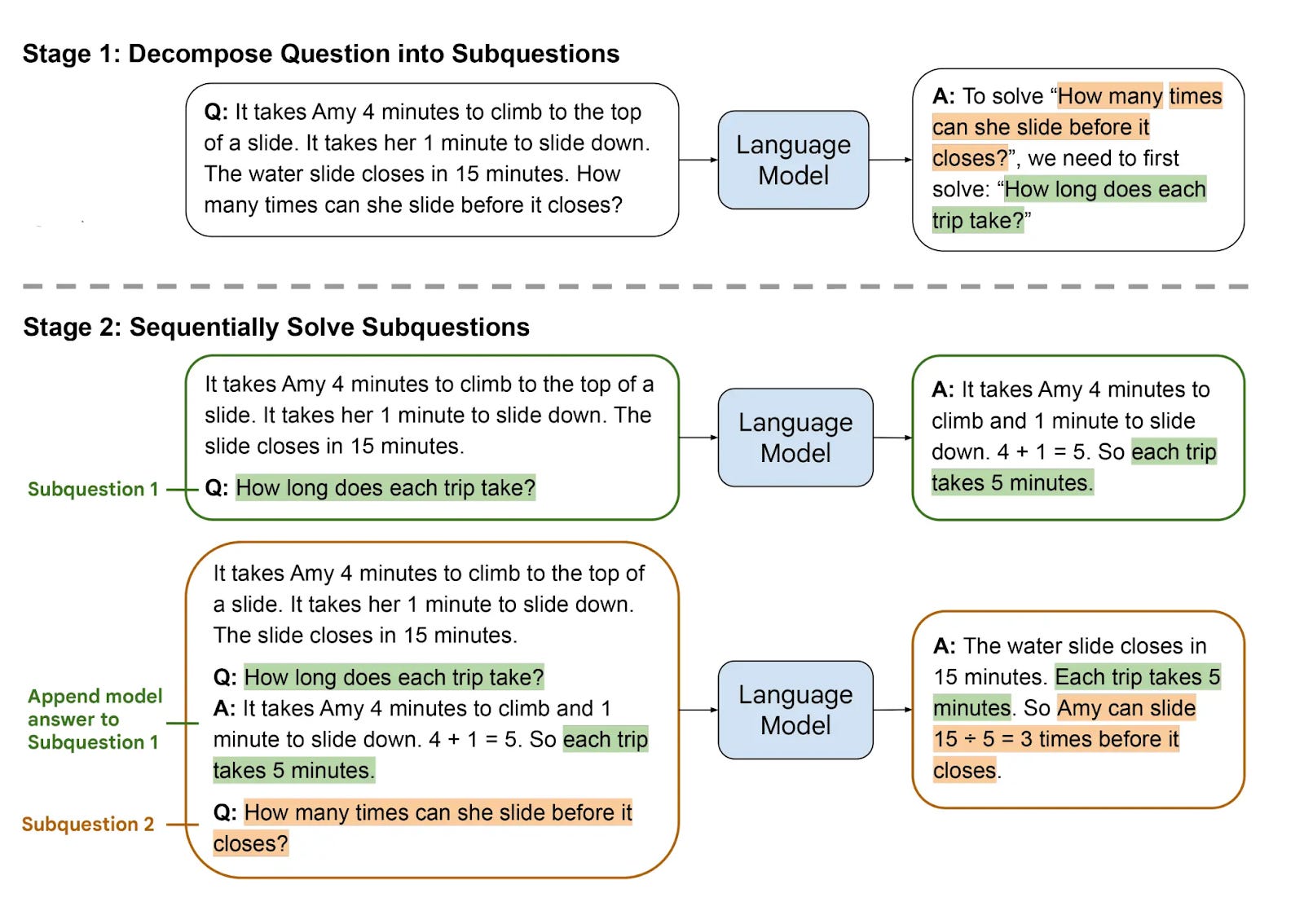
Least-to-most prompting breaks complex problems into simpler, manageable subproblems that build upon each other sequentially. This two-stage approach first decomposes tasks, then solves each piece incrementally.
Key Benefits:
Superior generalization: Solves problems harder than training examples, achieving 99.7% accuracy on length generalization versus 16.2% for chain-of-thought.
Systematic decomposition: Provides clear problem breakdown that makes debugging and verification straightforward for complex workflows.
Common Pitfall: Domain-specific prompts don't transfer well across different problem types. Each new task category requires creating fresh decomposition examples.
The technique operates through explicit decomposition followed by sequential solving. Each subproblem uses answers from previous steps to inform subsequent solutions.
Least-to-most works best for educational applications, complex mathematical problems, and scenarios where systematic problem breakdown adds value over direct approaches.
Read more about Least-to-Most prompting here.
Decomposed Prompting
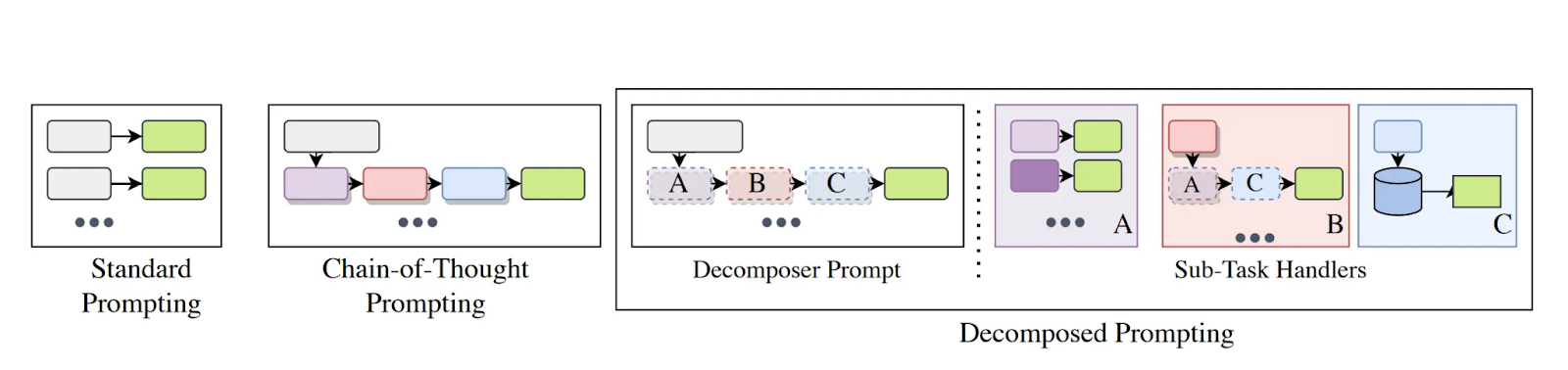
Decomposed prompting creates modular workflows where specialized sub-task handlers tackle individual components. Like software functions, each handler focuses on one specific operation within the larger system.
Key Benefits:
Modular debugging: Isolate and fix specific components without rebuilding entire reasoning chains, accelerating development cycles.
Reusable components: Sub-task handlers work across different applications, reducing prompt engineering overhead for similar tasks.
Common Pitfall: Implementation complexity increases substantially due to orchestration requirements between multiple specialized components and data flow management.
The approach uses a decomposer prompt to control overall task flow while sub-task handlers manage specific operations like data extraction or calculation.
Decomposed prompting excels for enterprise workflows requiring multiple specialized operations, complex data processing pipelines, and systems needing transparent component-level monitoring.
Read more about Decomposed prompting here.
Automatic Reasoning and Tool-Use
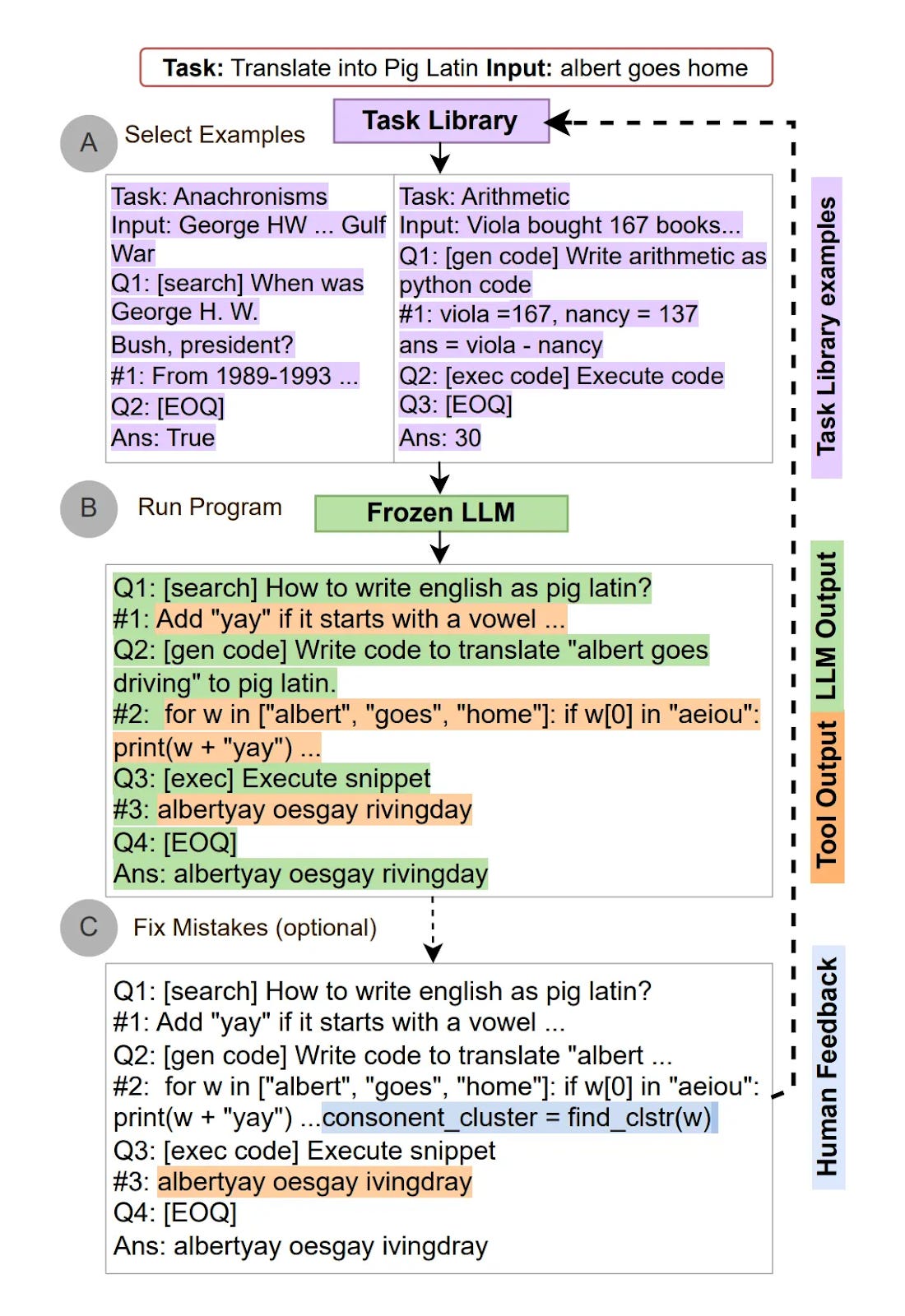
Automatic reasoning and tool-use enables models to autonomously select and execute external tools while maintaining coherent reasoning chains. Systems pause generation to call specialized APIs, then integrate results seamlessly.
Key Benefits:
Autonomous capability: Models independently choose appropriate tools for specific sub-tasks without manual intervention or pre-defined workflows.
Real-world integration: Seamlessly connects reasoning with databases, calculators, web search, and other external systems for enhanced functionality.
Common Pitfall: Creates larger attack surfaces for prompt injection and security vulnerabilities through external tool access and API manipulation.
The technique combines meta-reasoning for tool selection with execution workflows that maintain context across multiple external calls.
ART works best for research assistants, financial analysis systems, and applications requiring dynamic tool selection based on evolving problem requirements.
Read more about ART here.
LLM-Cost Cheat-Sheet
The costs vary dramatically across reasoning techniques. This table combines the prompt technique with estimated cost per call and the best LLM that can provide you with value for money.
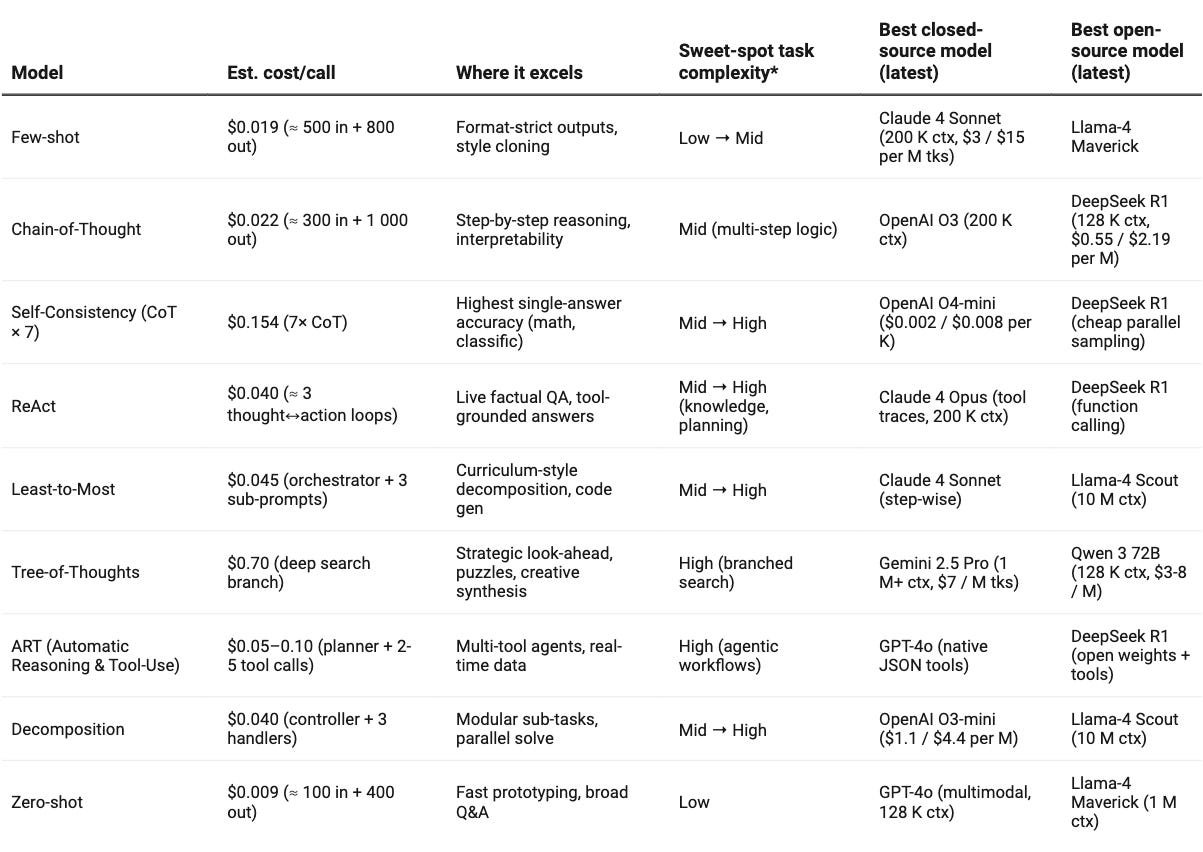
Budget-Friendly Options ($0.009-$0.022):
Zero-shot: $0.009 per call. Perfect for quick prototypes and simple Q&A. Use GPT-4o for closed-source or Llama-4 Maverick for open-source.
Few-shot: $0.019 per call. Ideal for format control and style consistency. Claude 4 Sonnet leads closed-source options.
Chain-of-Thought: $0.022 per call. Best for step-by-step reasoning when you need transparent logic.
Mid-Range Solutions ($0.040-$0.154):
ReAct: $0.040 per call. Excels at live data and tool integration. Claude 4 Opus handles complex tool traces.
Self-Consistency: $0.154 per call. Highest accuracy for critical decisions through majority voting.
Premium Approaches ($0.05-$0.70):
Tree-of-Thought: $0.70 per call. Strategic planning and creative problem solving. Gemini 2.5 Pro offers best value.
ART: $0.05-$0.10 per call. Multi-tool agents for complex workflows.
Choose based on complexity needs and accuracy requirements versus budget constraints.
When to Avoid Each Technique
Understanding prompt pitfalls prevents costly mistakes and over-engineered solutions. Each reasoning technique has specific scenarios where simpler approaches work better.
Avoid these techniques when:
Zero-shot: Skip for tasks requiring precise formatting or complex multi-step reasoning where examples significantly improve accuracy.
Few-shot: Avoid when you have sufficient data for fine-tuning or when context window limitations prevent including enough examples.
Chain-of-Thought: Skip for simple classification tasks where step-by-step reasoning adds unnecessary latency and cost without accuracy gains.
Self-consistency: Avoid for real-time applications due to 5-10x computational overhead or when single responses are acceptable.
Tree-of-Thought: Skip for straightforward problems where the 5-100x token cost doesn't justify accuracy improvements.
ReAct: Avoid when external APIs are unreliable or when tasks don't require external information beyond model training.
Least-to-Most: Skip for problems that don't naturally decompose into sequential subproblems or simple single-step tasks.
Decomposed: Avoid for simple workflows where modular complexity exceeds the debugging and reusability benefits.
ART: Skip when security requirements prevent external tool access or for basic tasks not requiring dynamic reasoning.
Conclusion
Reasoning prompt engineering techniques represent a fundamental shift from reactive AI outputs to systematic problem-solving workflows. Product leaders who master these nine approaches gain competitive advantages through reduced support tickets, faster feature cycles, and transparent decision-making processes.
The key lies in strategic selection:
Zero-shot works for rapid prototyping, while Tree-of-Thought handles complex planning scenarios.
ReAct excels when external data matters, and Chain-of-Thought provides audit trails for regulated industries.
Model choice amplifies the technique's effectiveness.
Claude 4 excels at extended reasoning
o3-mini dominates mathematical tasks
Gemini 2.5 Pro offers cost-efficient performance.
The wrong pairing wastes resources and delivers subpar results.
Critical success factor: Prompt iteration beats perfect initial design. Test your prompts against real user scenarios. Evaluate outputs systematically. Refine based on failure patterns. Even the most sophisticated technique with the best model fails without continuous improvement cycles.
Start with one technique, measure performance, then expand your reasoning toolkit as complexity demands require more advanced approaches.