
Sub-Agents For Product Managers: Stop Directing A Tool. Start Running A Team.
The chatbot model has a structural ceiling. Sub-agents are what's above it.

TLDR: PMs are running workflow through chat windows. That’s the wrong architecture. This blog breaks down why the chatbot model has a structural ceiling, not a prompting problem. And what actually changes when you replace it with orchestrated, parallel, and workspace-native agents. It covers the three constraints killing your current setup, how sub-agents actually work, when to use them and when not to, and what the PM role becomes once the architecture shifts.

We are 2026, and I still find many product managers using AI the same way they use Google: type a question, get a response, and act on it.
The interface is a text box.
The output is text that you copy elsewhere.
The workflow is: prompt, read, paste, and repeat.
This works. But it has a ceiling. But not a ceiling of model intelligence.
Claude 4.6, GPT-5.3, and Gemini 3.1 are all capable of more than what a single chat thread lets you access. The ceiling isn’t the model. It’s the architecture you’re running it through. A chatbot is one assistant, one context window, one sequential thread. Every interaction starts with what you type. Every output ends up in your clipboard.
Sub-agents for product managers aren’t a new feature inside that model. They’re a replacement for the model itself.
The change is from directing a single assistant to orchestrating a team.
And the product teams that have made this shift aren’t just working faster, they’re also working differently.
Research, spec drafting, and backlog triage used to happen one at a time. Now they happen in parallel, each handled by a specialized agent, each returning a structured result to an orchestrator, the PM, who synthesizes and decides.
This article is about the mental model behind that shift.
Not a tutorial.
Not a setup guide.
It is a framework for understanding what sub-agents are, why the interface you run them from matters, and what the PM role actually looks like once the architecture changes.
The Single-Assistant Ceiling
The chatbot model has three structural constraints that no amount of improved prompting can solve.
The first is statelessness.
Every session starts from zero. The model has no memory of your product, your codebase, or what you decided last Tuesday unless you paste it back in.
Now, although ChatGPT and Claude (Web) have memory functionality. But the issue is that they have a common memory space and all the chats access the same memory. So the problem with this setup or workflow is that information will be shared in projects that don’t require it. To put it another way, personal, private, and professional life will be mixed up.
In this case, PMs become context managers. They have to:
Maintain long system prompts.
Copy documentation into chat windows.
Manually filter content and information and bridge the gap into what the AI needs to know and what it actually knows.
The intelligence is there, but the continuity isn’t.
The second constraint is single-threading.
Meaning one thing or task happens at a time. If you’re using an agentic AI product manager setup, you’ve probably felt this. You ask the model to research a competitive feature, then draft a spec, then break it into tickets. Each task waits for the previous.
The model is capable of doing all three — just not at once, not in separate contexts, not in parallel.
Complex PM work rarely has that kind of serial structure. Real product work leverages parallelization. Because it saves time, it's fast and efficient.
The third constraint is isolation from the environment.
A chatbot suggestion lives in a chat window. The action it recommends lives elsewhere — in Jira, in Notion, in a Figma file, or in a codebase. It takes manual effort to bring together “AI output” and “real artifact.”
As a PM, you are the integration layer. You copy the draft. You paste the ticket description. You take the suggestion and do something with it. The AI never touches the actual environment where work happens.
These aren’t complaints about specific products. They are structural properties of the chatbot interface. And together, they explain why product teams save roughly two hours a day through AI automation but watch those gains concentrate in routine, documentation-heavy tasks. Not the complex, interconnected work that makes the biggest difference. The interface caps the upside.
The question isn’t how to prompt better inside the single-assistant model. It’s what happens when you replace the model altogether.
What Sub-Agents Actually Are
Sub-agents are not “more prompts.” They are a different architectural pattern. And understanding the pattern is the prerequisite to using it well.
In a sub-agent system, a parent agent — the orchestrator — decomposes a complex task and delegates pieces of it to specialized child agents. Each child agent, the sub-agent, operates in its own isolated context window.
It receives a prompt with exactly the context it needs.
Works autonomously using its assigned tools.
Returns a structured result to the parent.
The parent synthesizes those results and decides what happens next.
Three things make this fundamentally different from a single-assistant setup.
Context isolation.
Each sub-agent starts with a clean context. A research sub-agent exploring competitive positioning doesn’t share its context window with a spec-drafting sub-agent working on a feature brief. Neither pollutes the other’s focus.
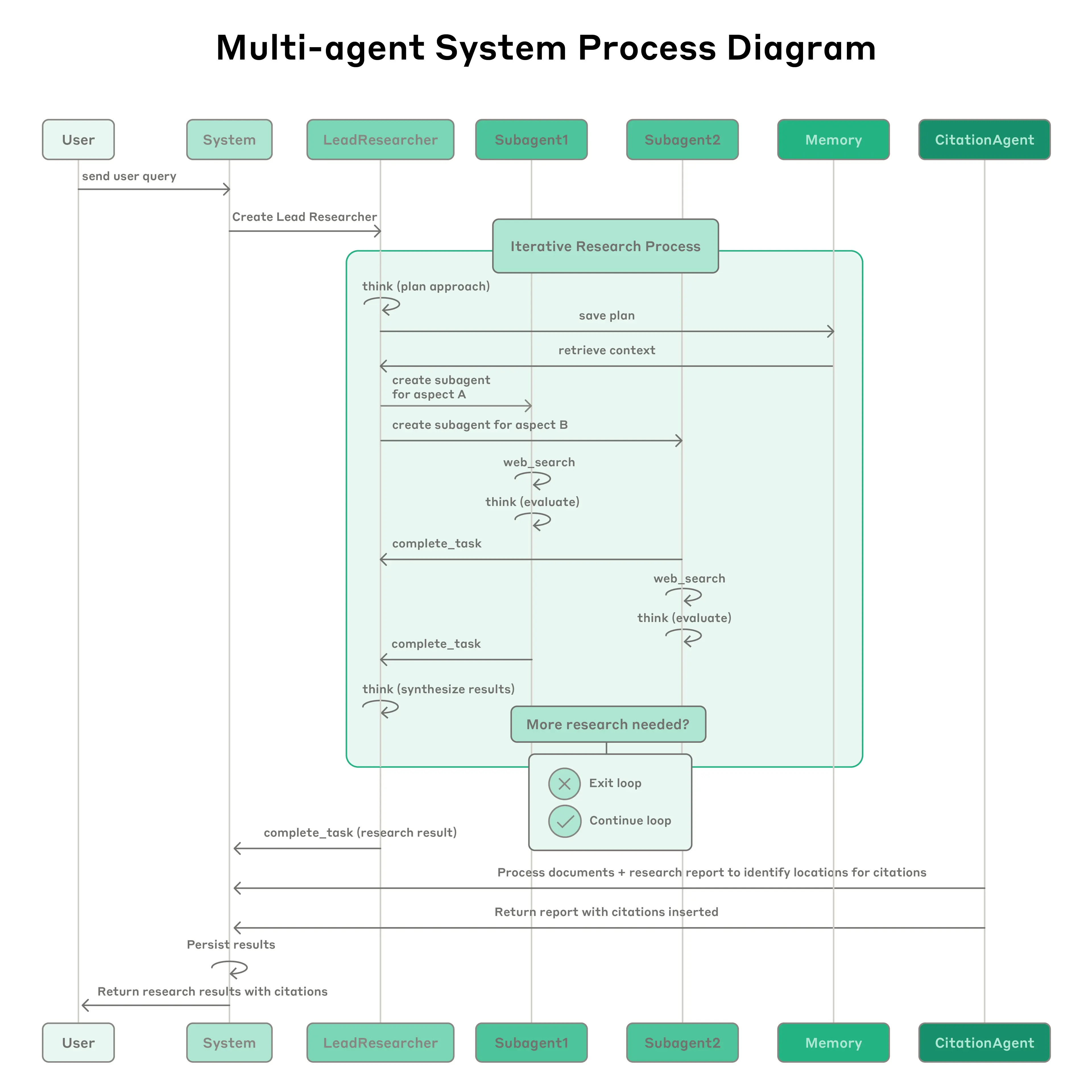
And the orchestrator never sees the intermediate noise. It sees final results. This is how Anthropic’s multi-agent research system works:
A lead agent spawns sub-agents to explore different aspects of a question simultaneously, each returning condensed findings rather than raw search logs.
Anthropic’s engineering team — Jeremy Hadfield, Barry Zhang, and colleagues — documented a 90.2% improvement over single-agent performance on complex research tasks. Not because the model got smarter, but because the architecture distributes the cognitive load.
Parallel execution.
Multiple sub-agents run simultaneously. This is what the Cursor community noticed when sub-agents shipped — that single-threaded prompting suddenly felt archaic.
Agents with real roles, customized skill sets, clean handoffs, deliberate execution.
That was the reaction, because that’s what becomes visible when you move from sequential to parallel.
From a PM standpoint, a research agent, a spec agent, and a triage agent can all be working simultaneously. Each in its own context and each returning to a shared orchestration layer when complete.
Specialization and model selection.
Each sub-agent is configured for its role. That includes its instructions, its tool access, and most importantly, its model.
A sub-agent doing deep reasoning on a product brief might run on Claude Opus.
A sub-agent performing rapid parallel searches might run on Claude Sonnet 4.6, GPT-5.3 Instant, or even Gemini 3.1 Flash. Where speed matters more than depth.
A sub-agent working with long documents such as research papers, transcript archives, and support logs, might run on Gemini, which is optimized for long-context retrieval.
The model choice stops being a single global setting and becomes a deliberate configuration decision per task type.
This is what multi-agent product management actually means in practice: the PM defines the goal and the team's shape. The team executes in parallel. The results come back structured.
The community reaction to seeing this run — “makes single-threaded prompting feel archaic” — is the right reaction.
It’s not hyperbole.
It’s a recognition that the previous model had a ceiling you didn’t know you were hitting until you saw above it.
Why the Interface Matters: Chatbot vs Workspace-Native
Knowing what sub-agents are is half the model. The other half is understanding where they can run. Because the interface is not neutral. It shapes what’s possible.
A chatbot interface is isolated by design.
It processes text and returns text. It has no access to your files unless you paste or attach them. It has no connection to your tools unless you’ve explicitly described them in the prompt. It has no memory of your product unless you rebuild that context every session.
This is fine for answering questions. It is a structural constraint for orchestrating a team of agents that need to read your codebase, push to Jira, pull from Notion, and execute changes in real files.
Workspace-native tools solve this at the architecture level.
The clearest articulation of the distinction is this: ChatGPT works from pasted context. Cursor works from your actual project. That difference sounds obvious. Its implications run deep.
Dennis Yang, a PM at Chime, put it plainly after switching: “Cursor is a much better product manager than I ever was.”
He’s not talking about the model. He’s talking about the environment.
When a PRD is drafted inside the workspace, it references real API endpoints. The spec reflects what the team has actually built. Tickets are grounded in the codebase, not a description of it. The artifacts are real because the tool is connected to the environment where real work happens.
This matters specifically for sub-agents because sub-agents need plumbing.
A research sub-agent needs web search and internal documentation.
A spec-drafting sub-agent needs the product’s existing architecture.
A triage sub-agent needs to read from Jira or Linear and write back to it. None of this is possible inside a stateless chat window.
The Model Context Protocol (MCP) is what makes it possible in workspace-native tools: a standardized layer that connects agents to external tools and files as first-class capabilities, not workarounds.
The MCP Product Playbook: From Idea to Prototype in One Conversation

TLDR: This blog shows how Model Context Protocol (MCP) transforms AI product development from an eight-week engineering marathon into a four-hour prototyping sprint. Through building a shopping assistant, you’ll learn a five-stage playbook that covers tool discovery, product definition, system prompt engineering, guardrails design, and quality evaluatio…
YC’s Spring 2026 Request for Startups named “Cursor for Product Management” as an official startup category.
Naval Ravikant told his 3M+ followers that vibe coding is the new product management. Both point to the same underlying shift: the environment where PMs work is moving from specification documents to executable workspaces.

The AI agent workflow that matters isn’t the one in the chat window. It’s the one running inside the environment where decisions become artifacts.
The PM as Orchestrator: What the Role Actually Becomes
When the interface changes, the role changes. Not in the direction most PMs expect.
The shift from chatbot to sub-agent orchestration is not primarily a technical shift. PMs who make this transition don’t need to become engineers.
What they need to become is more precise about goals, constraints, and boundaries. Because in an orchestrated system, the PM is not directing each step. The PM is defining the brief. The agents figure out the steps.
This is actually a familiar mental model.
A PM working with a research team, a designer, an engineer, and a data analyst doesn’t tell each person exactly what to type. They define the objective, constraints, output format, and handoff structure.
The team figures out the execution.
Sub-agent orchestration is the same mental model applied to AI agents. The PM provides the brief, not the method.
What changes is the cost of imprecision. A vague goal given to a human engineer prompts a conversation, a clarifying question, and a back-and-forth. A vague goal given to a sub-agent produces an output — confident, well-formatted, and possibly wrong in ways that are hard to catch.
The orchestrator’s core competency becomes writing goals precise enough that agents don’t hallucinate arbitrary decisions to fill in the gaps. This is what product teams are starting to call “executable specs.” Essentially, they are requirements so specific that they function almost as instructions. It is the PM skill that matters most in a sub-agent world.
What the PM stops doing is acting as the integration layer.
In the chatbot model, the PM is the one who carries information between tools — from AI to Jira, from research to spec, from spec to engineer. In a well-designed orchestration system, agents handle those handoffs. The PM’s time shifts toward judgment calls: which goals to prioritize, which agent outputs to synthesize, which results to challenge.
Jim Allen Wallace of Redis documented a 40% agentic project cancellation rate by end of 2027. And it isn’t primarily an engineering failure. It’s a coordination failure. Teams underestimate the design work required to define:
Precise enough goals to prevent hallucination drift.
Clear enough scope boundaries to keep agents from doing work that conflicts.
Getting orchestration right is a product design problem. Which means it’s a PM problem.
When Sub-Agents Are the Right Call
Sub-agents are not the answer to every PM problem. The overhead is real and should be taken seriously.
Each sub-agent runs in its own context window, which means each one consumes tokens independently. Anthropic’s engineering team found that multi-agent architectures use roughly fifteen times more tokens than standard chat interactions. That’s an economic reality, not a footnote.
Sub-agents are worth it when the task’s value justifies the cost and when the task’s structure actually suits parallel execution.
Use sub-agents when:
The task is genuinely too large for a single context window.
Distinct parallel workstreams exist that don’t depend on each other’s output.
different parts of the task benefit from different model strengths — deep reasoning, fast retrieval, and long-context analysis.
Don’t use sub-agents when:
The task is simple, sequential, and fits comfortably in a single context.
When all agents need to share the same context to make decisions (this breaks context isolation, eliminating the primary benefit).
When the coordination overhead — designing handoffs, synthesizing outputs — exceeds the time the parallelism saves.
Single-agent approaches often outperform multi-agent in production for tightly sequential tasks.
Complexity is not a virtue.
The orchestrator’s job is to match the architecture to the task. And sometimes the right call is one agent, one context, one clean result.
Conclusion
The chatbot is not going away. But it’s already not the ceiling; it’s the floor.
The PMs who are pulling ahead aren’t using better prompts inside the single-assistant model. They’re designing systems: specialized agents with defined roles, parallel execution, clean handoffs, and workspace-native environments. Where AI output lands as real artifacts, not clipboard text.
The mental model shift is from user to orchestrator. From “how do I ask this better?” to “how do I design a team that handles this without me acting as the integration layer?”
That transformation requires precision, in goal-setting, in constraint definition, in understanding which tasks justify the architecture and which don’t.
It requires tools that are connected to the actual environment where work happens, not isolated chat windows. And it requires a different relationship to AI: not a tool you direct, but a team you run.
The question to sit with: what is the most complex workflow you currently manage by copying responses from a chatbot into five other tools?
That’s the first candidate.
Not because sub-agents make it trivially easy; they actually don’t. But because that workflow has already exposed the ceiling of the model you’re in.
The architecture exists to go above it.