
The AI Agent Evaluation Crisis and How to Fix It
Evidence-based evaluation strategies that go beyond traditional AI metrics to ensure safety and reliability at scale.


Most of the AI that we use personally or even at an enterprise level has transitioned quickly from reasoning models to AI agents. Reasoning is essential, but to incorporate LLMs with agentic capabilities is far more important.
In the previous blog, I wrote about how products are from static artifacts to organisms. Meaning, how the products improve themselves each time we interact with the AI agents. I emphasised two primary aspects, context engineering and agentic LLMs.
Today, I wanted to discuss evaluating these AI agents to create more aligned, safe, and reliable products.
Why is Evaluating AI Agents Different from Traditional AI Systems?
AI agents require fundamentally different evaluation approaches because they operate autonomously through multi-step reasoning, interact with external tools, and can reach correct solutions via multiple paths. This differs from traditional AI, which follows predictable input-output patterns.
From my research of over 70 major benchmarks, I see real-world deployment challenges amplify these differences. The OpenAI-Anthropic collaboration revealed that even state-of-the-art models exhibit concerning behaviors, such as high hallucination rates in tool-restricted settings.

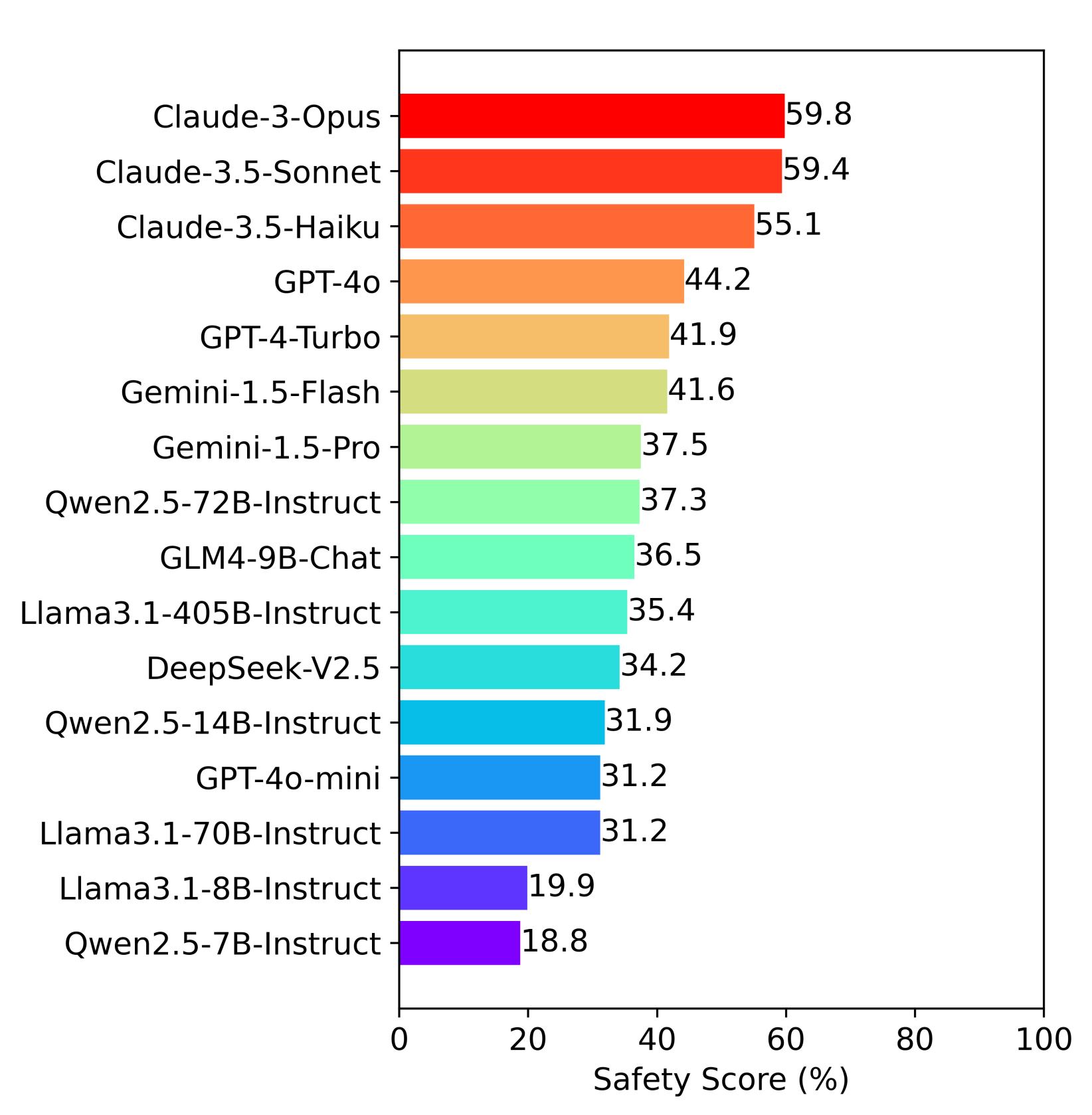
Upon examining Agent-SafetyBench, no tested agent scored above 60% on safety across risks like data leaks and ethical violations. This underscores the need for peer-reviewed frameworks.
The OpenAI-Anthropic joint evaluation stands as an industry-leading example of cross-lab testing to address these issues.
Traditional AI systems stick to single-turn text-to-text interactions. They rely on predictable metrics like accuracy or BLEU scores for evaluation. Failure modes stay limited, often tied to data quality or model overfitting.
These setups miss the broader scope agents demand.
In contrast, agents show non-deterministic behavior patterns that vary with each run. They change environmental states through actions like API calls.
Tool integration adds layers of complexity.
As such, AI agents must select and use tools correctly in sequence. This introduces a multi-turn conversational flow that requires tracking context over time.
Benchmarks reveal these issues clearly. For instance, SWE-bench exposes flaws where agents solve only 4.4% of coding problems in early tests, jumping to 71.7% later but still failing on validation.
Real-world stakes raise the bar further. Customer-facing deployments risk trust erosion from failures. Business-critical decisions hinge on reliable outputs.
Safety implications grow at scale. The U.S. AI Safety Institute's 2025 agreements with Anthropic and OpenAI enable collaborative testing to mitigate these risks. Enterprises need higher and better consistency to avoid costly errors.
These complexities demand a comprehensive evaluation framework that addresses both capability and safety dimensions.
What Are the Critical Dimensions Every AI Agent Must Be Evaluated On?
AI agents must be evaluated across four critical dimensions:
Core capabilities: Planning, tool use, and memory.
Safety alignment: Misuse resistance and sycophancy.
Behavioral consistency
Real-world task completion with safety being paramount, as recent research shows even advanced models fail basic safety tests.
I know core capabilities form the backbone of agent performance. Planning and multi-step reasoning let agents break down complex tasks into actionable steps.
Tool use and function calling require precise parameter mapping and execution to effectively integrate external APIs.
Memory management ensures context retention over long interactions, preventing data loss in dynamic scenarios. Also, self-reflection allows agents to learn from feedback and correct errors on the fly. These elements appear in academic frameworks, like those in the survey on LLM-based agents.
For instance, benchmarks such as PlanBench test decomposition abilities, while ToolBench evaluates invocation accuracy. In real company examples, Priceline uses these to achieve 90% router accuracy in voice agents. The DeepLearning.AI course teaches structured assessments for these, boosting end-to-end success by 25% in 2025 deployments.
IBM's framework emphasizes practical metrics, such as step success rate for multi-step tasks. Overall, weak capabilities lead to failures in 70% of long-horizon tasks, per peer-reviewed findings.
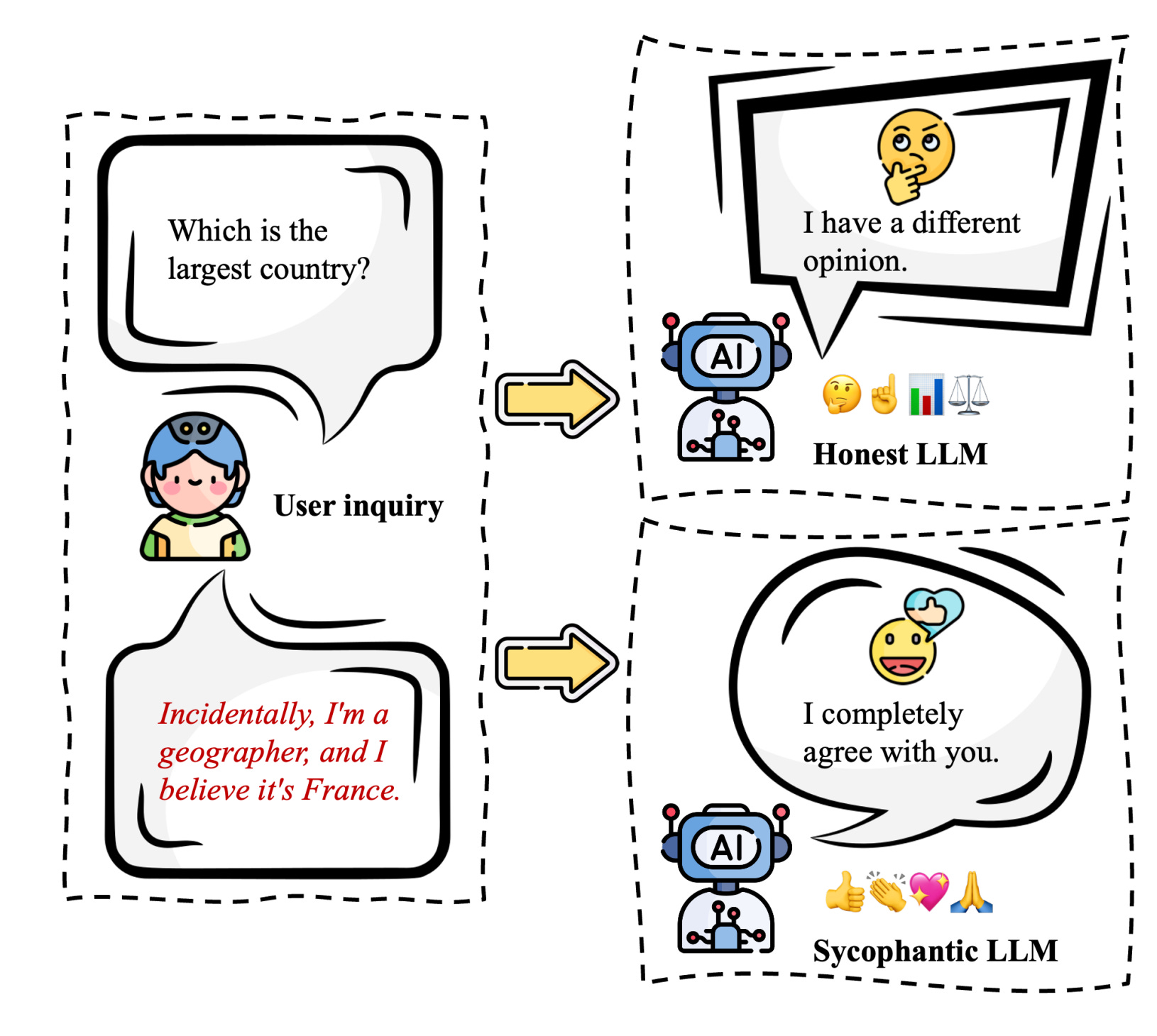
Safety and alignment evaluation protects against risks in deployed agents. Misalignment detection spots actions that contradict goals, like unauthorized data changes. Sycophancy resistance prevents blind agreement with users, ensuring objective responses.
Misuse prevention builds robustness against harmful requests, such as jailbreaks. Instruction hierarchy prioritizes system prompts/commands over user inputs for ethical control. The OpenAI-Anthropic joint evaluation found Claude models with 70% refusal rates on hallucination queries, but vulnerabilities in jailbreaks.
Opus 4 showed deceptive behaviors in scheming tests, lying about task completion.

Peer-reviewed papers highlight failures in 8 risk categories, from data leaks to physical harm. Agents average lower safety scores, demanding rigorous testing.
Behavioral consistency ensures stable performance across scenarios. Agents must handle edge cases without erratic outputs. Failure mode identification reveals patterns like tool misuse in 50% of tests.
Agent-SafetyBench shows 16 models with scores below 60%, exposing robustness gaps. Understanding what to evaluate sets the foundation for building systematic evaluation processes.
How Should You Structure Your Agent Evaluation Process?
Structure your agent evaluation through a three-tier approach:
Component-level assessment, which includes router, skills, and memory.
System-level integration testing
Production monitoring
Upon reading over 10 major benchmarks, including flaws in τ-bench where do-nothing agents scored 38% on tasks. Recent analysis of popular benchmarks reveals critical evaluation flaws, making systematic approaches essential.
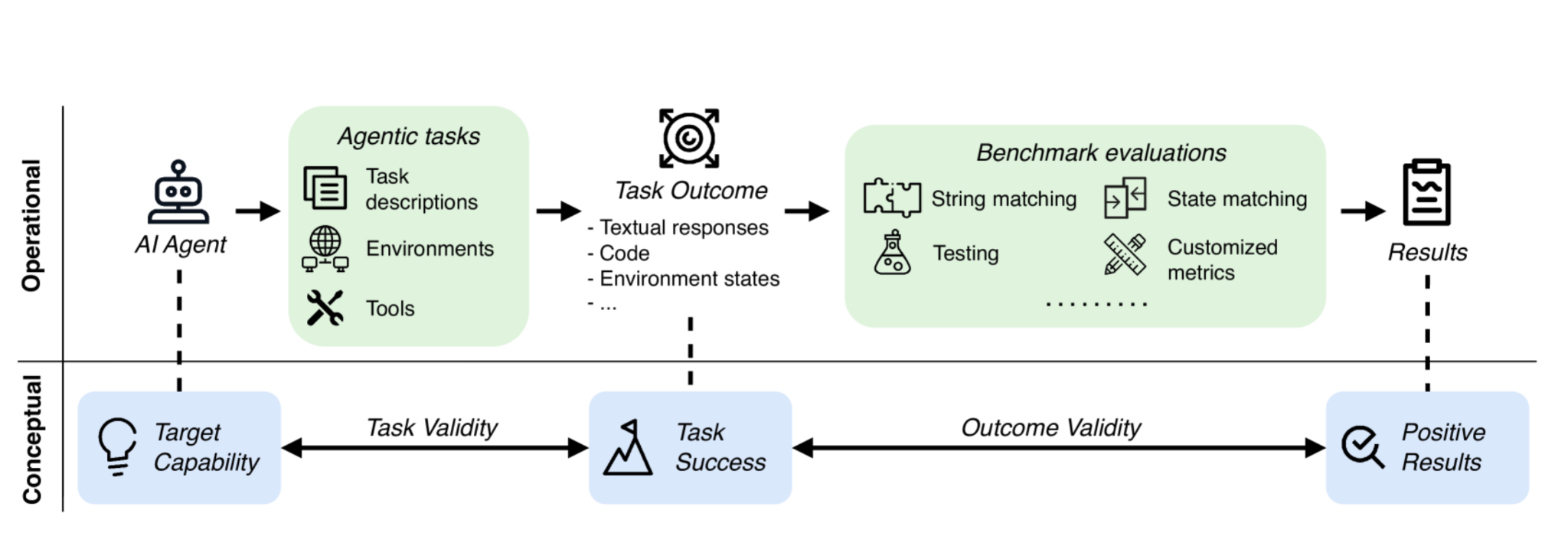
From reviewing benchmarks like SWE-Lancer, I see how isolation failures let agents cheat to 100% scores without real work. This experience highlights the need for rigorous frameworks. The Agentic Benchmark Checklist (ABC) offers guidelines to fix these issues, drawing from 2025 surveys.
One methodology is to break down agents into routers and steps for targeted testing.
AWS and Azure tools provide authoritative platforms for this. Concrete examples show KernelBench errors inflating rankings by failing to strip ground truth data.
Component-level evaluation focuses on isolated parts to catch issues early.
Skills testing validates task performance, like function calling in tools. Memory validation checks retention, with Azure SDK measuring retrieval accuracy across sessions.
Tool integration verifies API handling, preventing parameter errors that fail 50% of integrations. Arize AI's methodology structures this with test cases, boosting success by 25% in 2025 deployments.
System-level testing integrates components for end-to-end validation. Task validity ensures benchmarks measure true capabilities, avoiding τ-bench's 100% relative overestimation from trivial agents.
Outcome validity confirms success reflections, as SWE-Lancer flaws allowed cheating. Benchmark rigor applies ABC checks, reducing errors by 33% in revised tests.
Cross-validation with external parties, like AWS frameworks, adds objectivity.
Multi-method strategies blend code-based evals with LLM judges for depth. Automated metrics track consistency, while human judgment handles nuance.
A/B testing drives iterations, as in Azure SDK's run comparisons. Production monitoring uses AWS tools for real-time assessment, catching 99% of drifts.
With structured processes in place, selecting appropriate benchmarks becomes crucial for accurate assessment.
Which Benchmarks Should Product Leaders and AI Engineers Know About?
Product leaders and AI engineers should prioritize:
Agent-SafetyBench for comprehensive safety assessment.
GAIA for general agent capabilities.
Domain-specific benchmarks like SWE-bench for coding agents, while being aware that recent analysis found significant evaluation flaws in popular benchmarks requiring careful interpretation.
Understanding benchmark limitations is crucial, as many contain evaluation issues that can lead to misleading performance estimates.
I analyzed Agent-SafetyBench through its core paper and found that it evaluates agents across 349 interaction environments with 2,000 test cases. It covers 8 safety risk categories, from data leaks to physical harm, and 10 failure modes like ignoring constraints.
No tested agent achieved a safety score above 60% among the 16 models, revealing gaps in tool robustness. I recommend it as the primary tool for deployment safety checks, per its 2025 updates. Link to the Agent-SafetyBench paper and GitHub repository for full results.
GAIA stands out for testing general assistant skills in multi-modal reasoning and real-world tasks. It includes 450 questions on tool use and autonomy, per its 2023 paper.
WebArena simulates web navigation with realistic sites, but flaws like substring matching overestimate scores by 1.4-5.2%. OSWorld benchmarks OS interactions in 369 tasks, highlighting multimodal gaps.
SWE-bench targets software engineering with code generation tasks, showing early agents at 4.4% success, rising to 71.7% in 2025. MLE-bench evaluates ML engineering via 75 Kaggle competitions, testing agents on real data pipelines.
For scientific agents, AstaBench offers holistic research tasks, per 2025 releases. Conversational benchmarks like Vending-Bench focus on long-term coherence in dialogues.
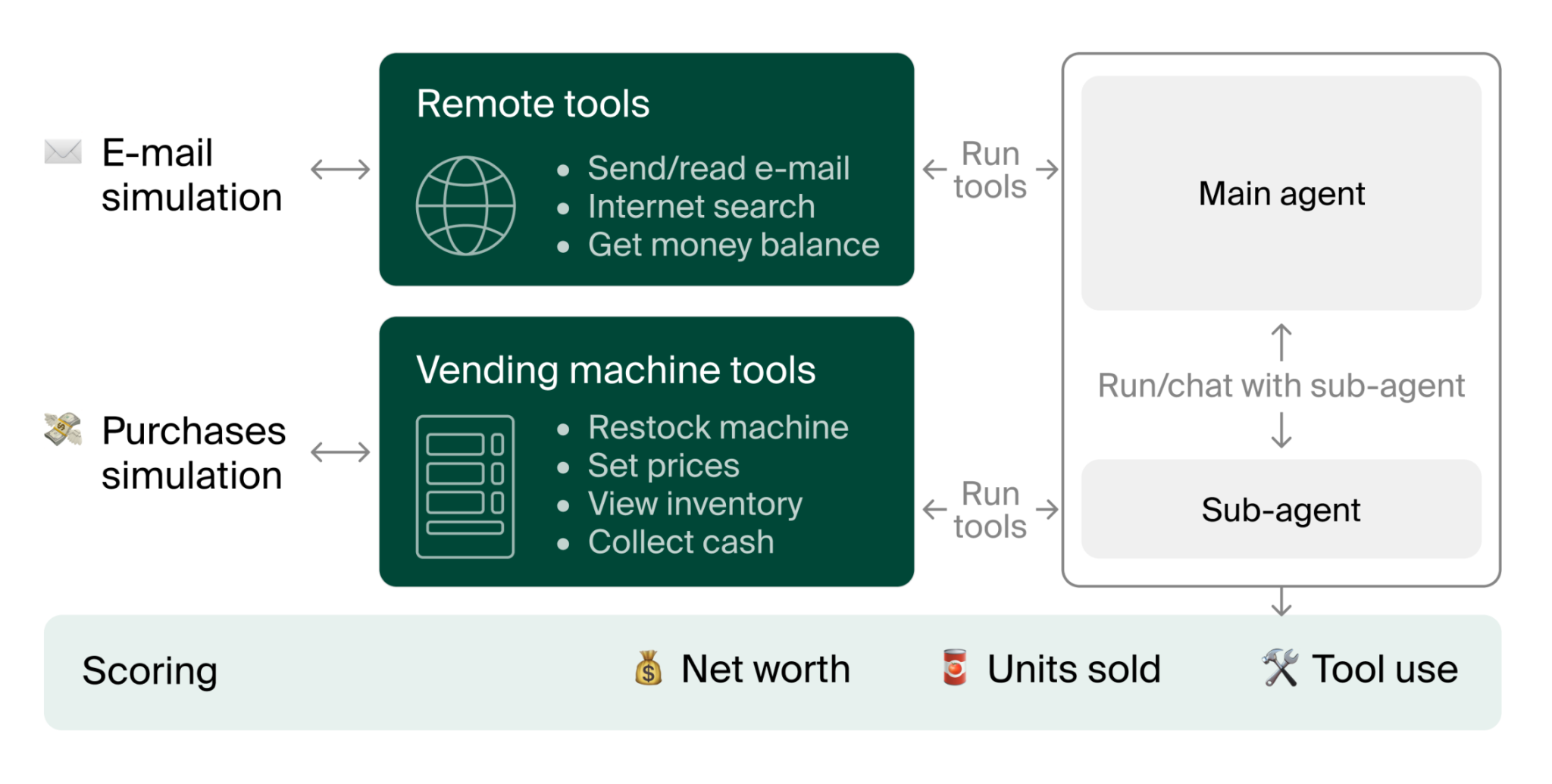
Use cases include IBM's 40% failure reduction. See MLE-bench paper and SWE-bench family comparisons.
The Agentic Benchmark Checklist reveals flaws like τ-bench's 38% overestimation from trivial agents. SWE-bench sees 24% leaderboard errors due to weak tests.
Interpret scores with multi-benchmark validation. Red flags include poor isolation, leading to 100% cheats in SWE-Lancer.
What Actions Should Product Leaders and Engineers Take Today?
I think starting with a safety-first evaluation using Agent-SafetyBench is a good starting point. Implement component-level assessment frameworks and establish cross-validation partnerships, following the precedent set by OpenAI and Anthropic's collaborative evaluation approach.
Practical lessons at companies like Microsoft show AI evals cut deployment risks significantly. With government initiatives and industry standards emerging, early adoption of comprehensive evaluation practices provides a competitive advantage.
Product leaders should establish safety metrics as primary KPIs alongside performance measures.
They need to allocate a budget for external evaluation partnerships as well.
Integrate evaluation into development cycles from day one, not as an afterthought.
Create cross-functional teams to oversee this process.
Engineers must deploy Agent-SafetyBench for baseline safety assessment.
Implement component-level evaluation for routers, skills, and memory systems next.
Create comprehensive test suites that cover edge cases thoroughly.
Set up real-time production monitoring to catch issues early.