
The AI Research Landscape in 2026: From Agentic AI to Embodiment
How agentic workflows, continual learning, world models, and architectural innovation will be reshaping AI from research breakthrough to production reality.

TLDR: 2026 marks AI’s shift from breakthrough to consolidation. This analysis examines seven critical technical transitions reshaping production AI: agentic workflows scaling beyond demos, continual learning solving catastrophic forgetting, world models challenging LLM dominance, reasoning distillation bringing o3-level intelligence to edge devices, infrastructure hitting power constraints, and hybrid architectures replacing pure transformers. For technical and product leaders, this isn't just research; it’s the blueprint for AI that acts as a colleague, not a tool. The research-to-production gap is closing.

2025 will be remembered as the year reasoning models became agents. OpenAI’s o3 achieved breakthrough performance on mathematical reasoning benchmarks. Claude 4 Sonnet and Opus introduced extended thinking modes that matched expert-level problem-solving. These weren’t incremental improvements; they represented a new method in how AI systems approached complex tasks. They essentially used test-time compute, in which the model allocates more compute to reasoning and solving a complex task.

Reasoning or chain-of-thought, which is an intermediate process, is carried on a larger scale. Meaning, there are multiple reasoning paths running in parallel for the same problem. One of the common methods is the tree of thought, as shown in the image below.
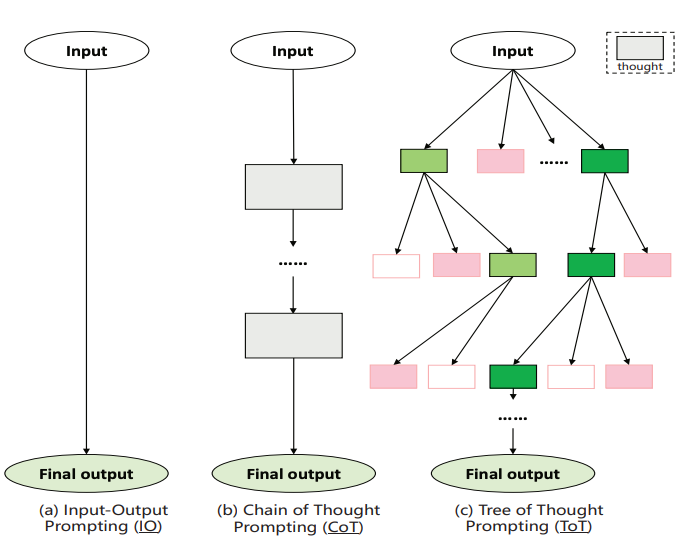
But reasoning alone wasn’t the revolution. The true transformation came when these models gained agentic capabilities. Claude Code enabled autonomous terminal-based development. OpenAI’s Operator handled multi-step web tasks without supervision. Gemini Deep Research synthesized information across dozens of sources independently.
2026 represents the consolidation phase. Research labs and communities, both open and private, have proven that LLMs can reason and act. Now comes the harder challenge: making these systems efficient, adaptable, and spatially aware.
Here, the key transition is moving from reasoning about tasks to reasoning within environments. This approach demands breakthroughs in continual learning, world models, and architectural efficiency; each addressing fundamental limitations that pure scaling cannot solve.
Agent Optimization: From Prototype to Production
The agentic tools launched in 2025 proved the concept. Claude Code demonstrated that AI could navigate codebases and execute terminal commands autonomously. GPT’s canvas mode showed collaborative iteration on complex documents. Gemini’s deep research capabilities synthesized information across dozens of sources without human intervention.
![[Image Alt Text for SEO]](https://substackcdn.com/image/fetch/$s_!L4Wl!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F35092a86-ef3c-4cde-be69-a93af2f3b206_1274x597.png "[Image Alt Text for SEO]")
But demos aren’t products. Gartner projects that 40% of enterprise applications will embed AI agents by mid-2026, up from less than 5% in early 2025. This eight-fold increase reveals both opportunity and risk. Industry analysts predict more than 40% of agentic AI projects will be canceled by 2027 due to escalating costs and unclear business value.
The gap between prototype and production is technical, not conceptual.
2026 will see multi-agent orchestration frameworks become standard infrastructure. Single agents that handle isolated tasks will give way to agent swarms that coordinate across specializations. One agent researches, another writes, a third validates—each optimized for its domain.
Agent-to-agent communication protocols will emerge as the connective tissue. These systems require standardized message formats, state synchronization mechanisms, and conflict-resolution strategies. Without these protocols, agents operate in silos despite running in parallel.
Next, persistent memory systems will separate successful deployments from abandoned pilots. Today, agents forget the context between sessions. ChatGPT introduced memory to encourage recalling details from the previous conversation. Claude introduced the CLAUDE.md file to structure the instructions and store and preserve memory. CLAUDE.md works with Claude Code, and it is automatically loaded upon launch.
Production systems need agents that remember user preferences, project history, and learned patterns across weeks of interaction.

Failure recovery and self-correction mechanisms address the reliability problem. When an 8-hour autonomous workstream fails at hour seven, the system needs graceful degradation, not catastrophic collapse. Research from METR shows AI task duration doubling every seven months. From one-hour tasks in early 2025 to eight-hour workstreams by late 2026.
The technical challenges are precise. Token efficiency determines whether 8+ hour workflows are economically viable. A single long-running agent session can consume hundreds of thousands of tokens. Cost optimization isn’t optional, it is one of the most important thing here. One error or misnavigation to fix the error can cost millions. Error propagation in multi-step workflows means a single mistake compounds across dozens of dependent operations.

Production-ready agents require solutions to all these problems simultaneously. 2026 is the year research becomes engineering. Anthropic, OpenAI, and Google DeepMind are already working on long-horizon agents. So it will be no surprise that in 2026, or more precisely by Q2, long-horizon agents will be perfected.
Continual Learning: Solving AI’s Memory Problem
Current AI systems face a fundamental paradox. They can reason through complex problems but can’t remember the solutions. Train a model on new data, and it forgets what it learned before. This phenomenon—catastrophic forgetting—has constrained AI development for decades.
The technical constraint is architectural. Transformer models encode knowledge in static weight matrices. Learning new information means updating these weights, which disrupts previously learned patterns. Fine-tuning on medical data degrades performance on legal tasks. The model can’t integrate new knowledge without overwriting old understanding.

Google’s Nested Learning paradigm, introduced at NeurIPS 2025, offers the clearest path forward. The breakthrough treats a single model as a system of interconnected optimization problems operating at different speeds. Fast-updating modules handle immediate context. Medium-speed modules consolidate intermediate knowledge. Slow-updating modules preserve fundamental capabilities.
The Continuum Memory System creates a spectrum of memory updating at different frequencies. This architecture prevents catastrophic forgetting by isolating knowledge updates across temporal scales. The proof-of-concept implementation, called HOPE, demonstrated the viability of unbounded in-context learning—the model continuously learns without forgetting.
, Core (in-context learning), and Persistent Memory (fixed weights).")
The Titans’ architecture, released in December 2024, provided complementary advances. It introduced learned long-term memory modules that prioritize information based on how surprising it is to the model. Context windows expanded beyond 2 million tokens. Test-time memorization allowed models to acquire and retain information during inference itself, not just training.
The implications for 2026 are transformative. Expensive retraining cycles—currently costing millions in compute—could be eliminated entirely. Models would adapt in real-time to user preferences without fine-tuning overhead. Domain adaptation without catastrophic forgetting means a single model handles medical, legal, and technical queries simultaneously.
Anthropic researcher Sholto Douglas made a striking prediction on the No Priors podcast: continual learning “will be solved in a satisfying way [38:14-38:38]” during 2026. Anthropic CEO Dario Amodei also reiterated this, suggesting the problem “will turn out to be not as difficult as it seems” and “will fall to scale plus a slightly different way of thinking.”
If these predictions prove accurate, the concept of AI as “virtual coworkers” becomes viable. Systems that learn from every interaction, remember project context across months, and adapt expertise without forgetting existing capabilities.
The year 2026 may solve AI’s oldest problem.
World Models: The Alternative Path to AGI
A fundamental paradigm shift is reshaping AI research. Large language models predict the next token in text sequences. World models predict the next state of a physical environment given actions within it. This distinction matters more than most realize.
The architectural difference is profound. LLMs operate in linguistic space, learning statistical patterns across text corpora. World models operate in latent representation space, learning causal dynamics of physical reality. As Yann LeCun frames it: LLMs can describe a rotating cube, but world models understand what rotation means spatially.
LeCun departed Meta in January 2026 to launch Advanced Machine Intelligence (AMI) Labs, seeking €500 million at a €3 billion valuation—one of AI’s largest pre-launch raises. His position is unequivocal: LLMs represent a “dead end” for achieving general intelligence because they lack grounding in physical reality. “You can’t get to real intelligence just by predicting the next word,” LeCun stated. Text-only training produces systems that discuss physics without understanding physics, describe spatial relationships without perceiving space.
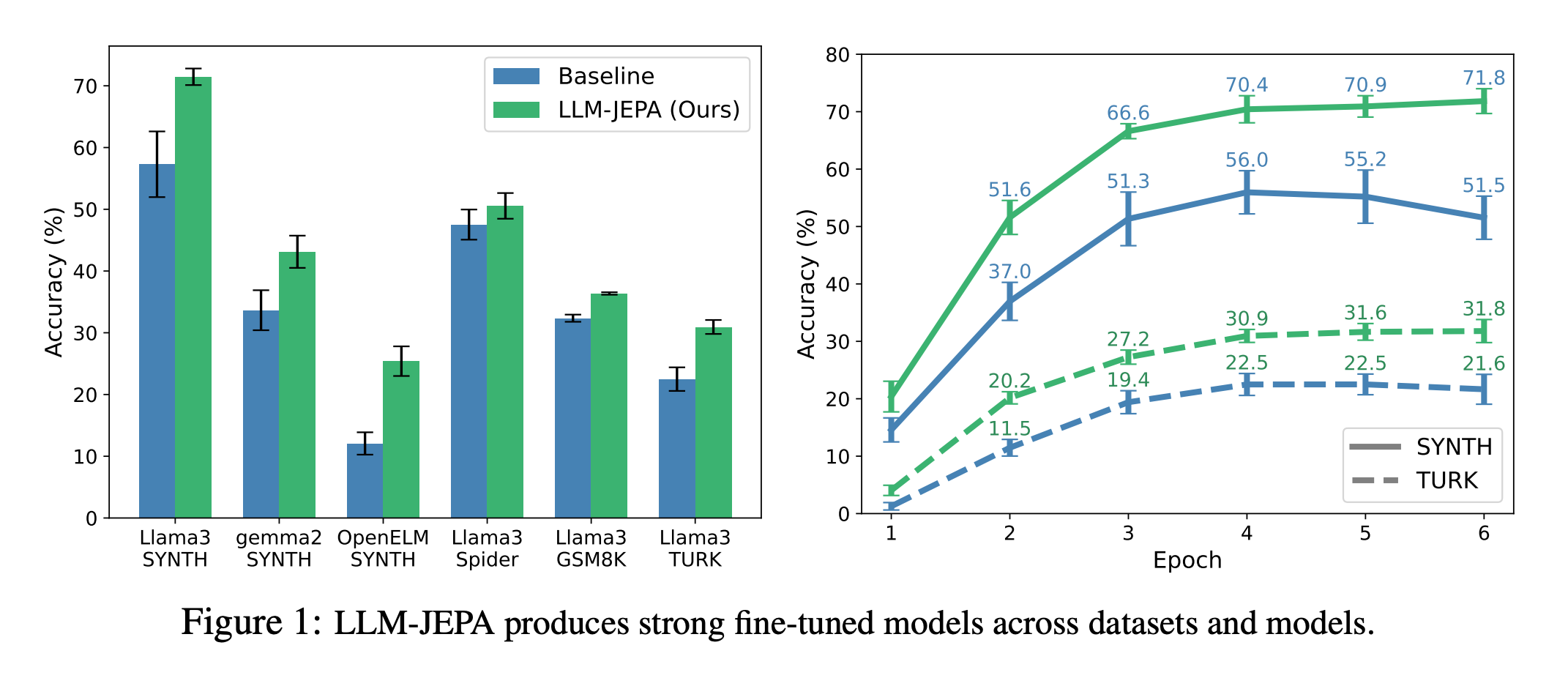
His technical solution is JEPA (Joint Embedding Predictive Architecture), which predicts representations in abstract embedding space rather than reconstructing pixels. Meta released V-JEPA 2 in January 2026, demonstrating state-of-the-art visual understanding after training on over 1 million hours of internet video. The model achieved 65-80% success rates on pick-and-place robotics tasks with unfamiliar objects in novel environments—using only 62 hours of robot training data.
Google DeepMind released Genie 3 in August 2025, the first real-time interactive world model. It generates navigable 3D environments at 24 frames per second in 720p resolution, maintaining consistency for several minutes. Unlike previous systems that require explicit 3D representations, Genie 3 learns physics from observation, generating worlds frame by frame via autoregressive prediction. DeepMind already uses Genie 3 to train its SIMA agent for complex goal achievement.
Fei-Fei Li’s World Labs launched Marble in November 2025 as the first commercially available world model product. Marble generates persistent, downloadable 3D environments from text, images, or video, with exports compatible with Unreal Engine and Unity. The platform offers VR support for Vision Pro and Quest 3. According to Li, Marble represents “the first step toward creating a truly spatially intelligent world model.”
The capabilities emerging in 2026 are foreseeable:
Real-time 3D world generation at 24 FPS.
Persistent state maintenance across minutes of coherent simulation.
Zero-shot robot planning in novel environments.
Multimodal conditioning from text, image, and video inputs.
World models enable physical reasoning rather than linguistic reasoning. They support embodied AI and robotics applications requiring spatial understanding. They provide causal understanding and counterfactual simulation—imagining “what if” scenarios before taking action.
The philosophical debate runs deep as well. Some researchers maintain that sufficient scale and architectural improvements can overcome LLM limitations. Anthropic CEO Dario Amodei predicted “a country of geniuses in a datacenter” as early as 2026 through LLM-derived systems. The debate may prove empirical rather than philosophical. If world models demonstrate reliable physical reasoning while LLMs continue hallucinating impossible physics, the field’s center of gravity shifts permanently.
2026 will inherently test whether language alone suffices for intelligence, or whether understanding the physical world is a prerequisite for general intelligence.
Reasoning Distillation: Fast Models with Deep Thinking
Reasoning models introduced a fundamental tradeoff. More inference-time compute yields deeper intelligence. OpenAI’s o3 achieved breakthrough performance on mathematics and coding by “thinking” through problems before responding. But this deliberation comes at a cost measured in seconds and dollars per query.
The 2026 challenge is transferring this capability to smaller, faster models without sacrificing reasoning depth. The technical breakthrough came from o3-mini, released in January 2025, which achieved parity with the original o1 model while being approximately 15 times more cost-efficient and five times faster. This wasn’t an incremental improvement—it proved that PhD-level reasoning could be democratized.
The distillation approaches gaining traction operate at multiple levels. Knowledge distillation from reasoning traces captures the intermediate steps large models use to reach conclusions. Research demonstrates that the structure of chain-of-thought reasoning matters more than the accuracy of individual steps—models learn reasoning patterns, not just correct answers. Synthetic data generation from teacher models creates training datasets where larger reasoning models produce both problems and structured solution paths. Pruning and quantization of reasoning pathways compress the computational graph while preserving logical coherence.

On 19 December 2025, Ankesh Anand (a research scientist at Google DeepMind) indicated that Gemini 3 Flash was an agentic RL distilled model. Meaning, the Flash is distilled from pro but enhanced with agentic RL.
This suggests that by mid-2026, reasoning is no longer a separate product line requiring distinct models. Gemini will integrate reasoning seamlessly across modalities. Reasoning effort [like we saw in GPT-oss] will likely become a parameter you dial up or down—low for speed, high for accuracy.
The philosophical change matters as much as the technical achievement. Inference-time scaling proved that intelligence isn’t solely about parameter count. Smaller models thinking longer can match larger models thinking less. This democratizes access to advanced reasoning, making it economically viable for applications where o3’s cost structure was prohibitive.
2026 will mark the year reasoning became a feature, not a product category. Every model will reason. The question becomes how efficiently.
Beyond Transformers: The Search for New Architectures
When attention isn’t all you need anymore.
The transformer’s quadratic complexity becomes untenable at scale. Processing million-token contexts requires O(n²) attention operations—computational costs that grow prohibitively as context windows expand. The architecture that powered the AI revolution now constrains its next phase.
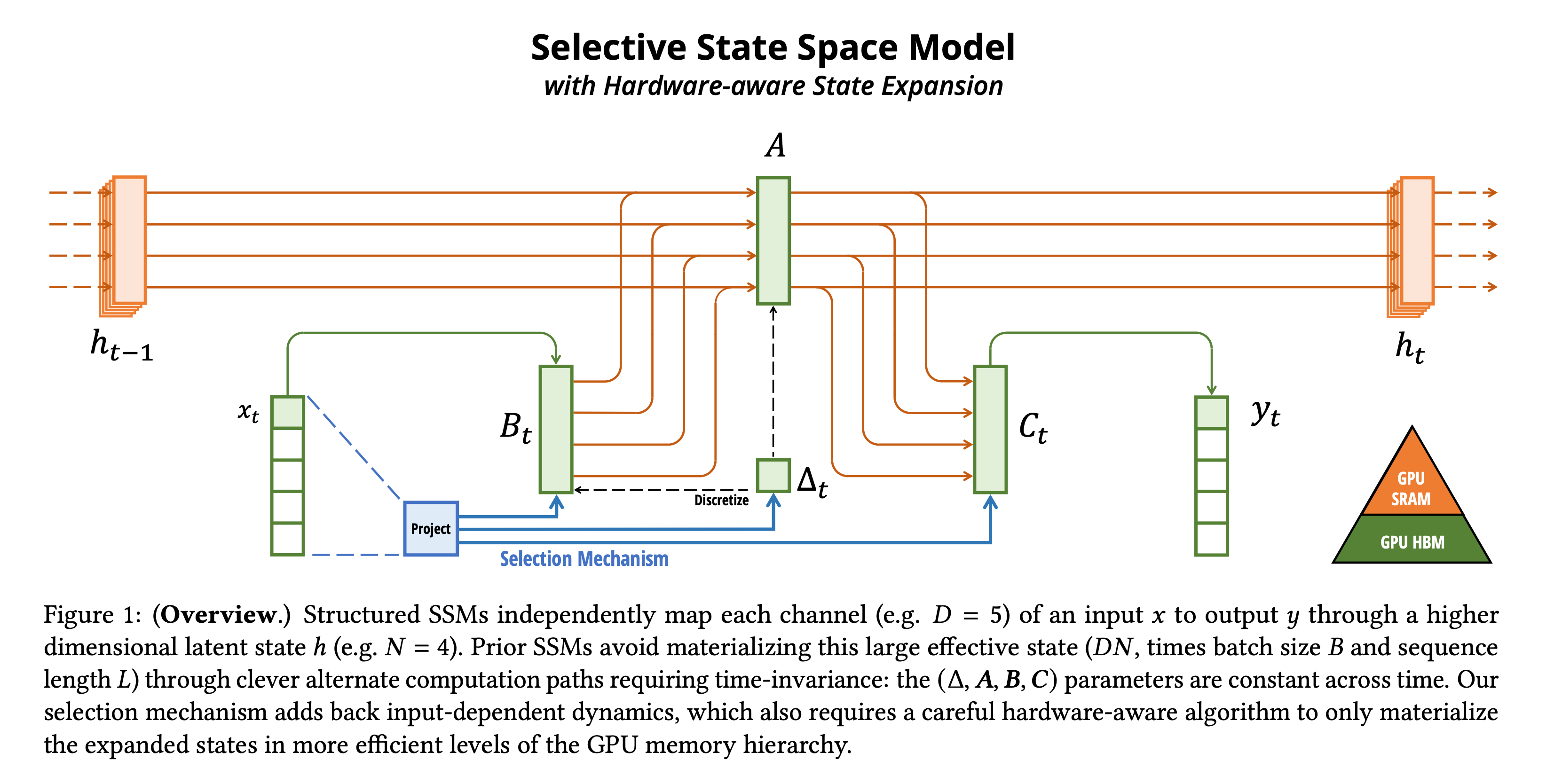
State Space Models (SSMs) emerged as the leading alternative. Mamba, introduced by Tri Dao and Albert Gu in December 2023, achieves linear-time sequence modeling through selective state spaces. The Mamba-3B model matches transformers twice its size while delivering 5x higher inference throughput. The key innovation: making SSM parameters functions of input, allowing selective information propagation.
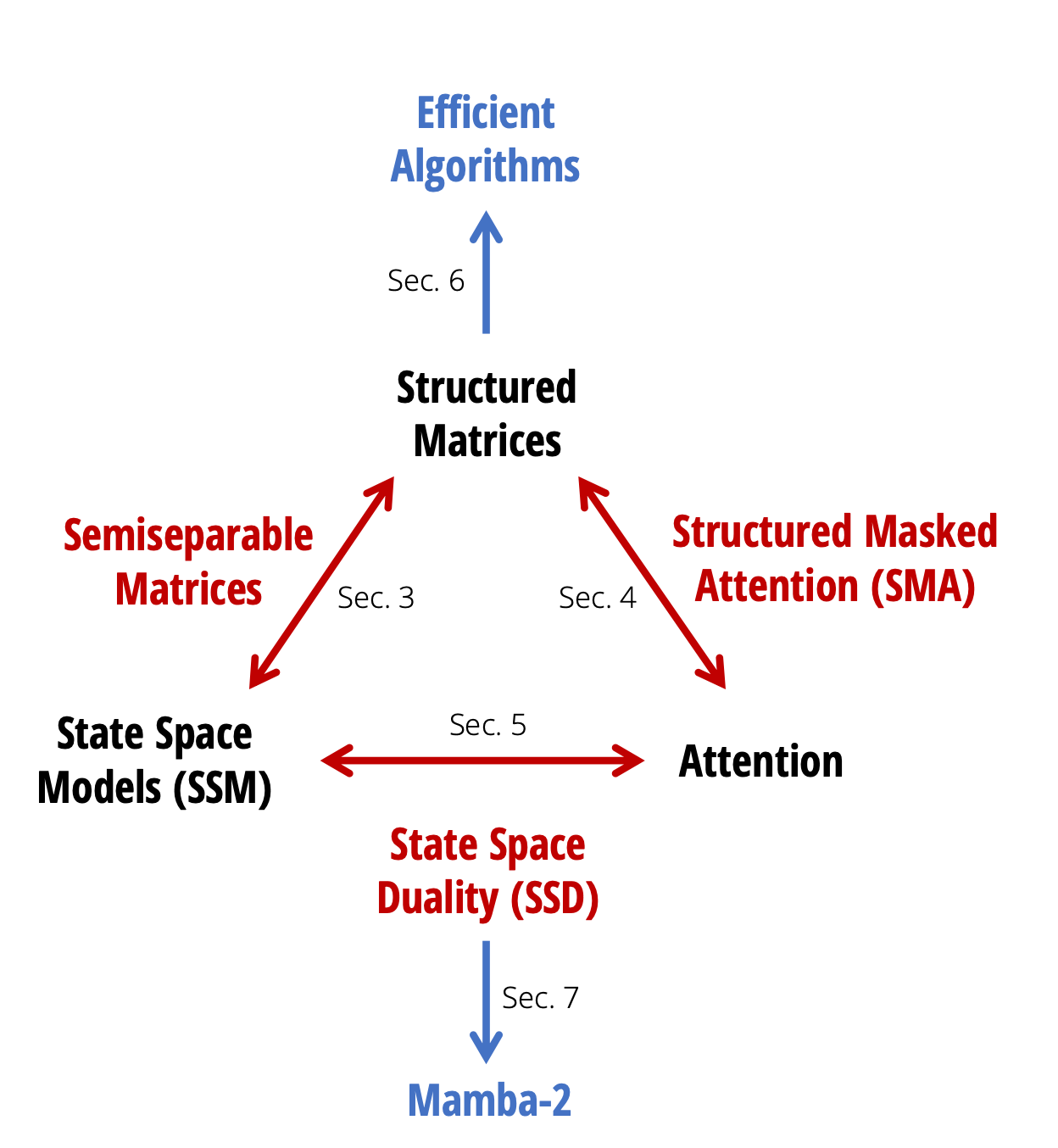
Mamba-2, released in 2024, introduced Structured State Space Duality (SSD), mathematically connecting SSMs and transformers while maintaining linear scalability.
Hybrid architectures proliferate in 2026. IBM’s Granite 4.0 and AI21’s Jamba series combine attention layers with Mamba blocks, leveraging transformers’ content-based reasoning alongside SSMs’ efficiency. Mistral’s Codestral Mamba represents pure SSM deployment at production scale.
Research directions converge on efficiency. Linear-time attention mechanisms eliminate quadratic scaling. Sparse mixture-of-experts (MoE) optimization activates only relevant parameters per token. Test-time compute allocation strategies, demonstrated by o-series models, trade latency for intelligence dynamically.
Memory-augmented neural networks integrate external knowledge stores, addressing context length constraints differently than pure architectural solutions.
The necessity becomes clear as pure scaling hits diminishing returns. Training runs approach data exhaustion by 2026. Epoch AI projects scaling limitations within the year. Architectural innovation isn’t optional—it’s required for continued progress. Transformers dominated 2017-2025, and maybe it will still be till 2030. But something has to change. The next eight years belong to hybrids and alternatives that solve what attention alone cannot: efficient reasoning at an arbitrary scale.
Conclusion
2025 belonged to the realm of reasoning models and agents. 2026 belongs to making them practical.
The technical transitions are solid. Single-task reasoning evolves into multi-agent coordination where systems collaborate on 8+ hour workflows. Static models yield to continually learning systems that update without catastrophic forgetting. Language-only AI evolves into spatially aware intelligence that understands physical reality. Monolithic transformers fragment into hybrid architectures optimizing for efficiency over scale.
The research priorities converge: efficiency, interpretability, robustness. Not coincidentally, these are prerequisites for deployment rather than demonstrations.
Open questions remain. Will continual learning deliver on Anthropic’s and Google’s predictions? Can world models scale beyond research prototypes? Is architectural innovation necessary or merely optimization?
The answers matter because these aren’t abstract research directions. They’re the foundation for AI that acts as a colleague, not just a tool. Agents that learn from correction. Models that understand space, not just syntax. Systems efficient enough for edge deployment.
2026 may be remembered as the year AI research shifted from “how big can we go” to “how smart can we be efficiently.” The models that win aren’t necessarily the largest; they’re the ones that reason deeply, learn continuously, and deploy everywhere. Intelligence, it turns out, is less about parameter count than about architecture, memory, and knowing when to think hard versus when to think fast.
What I find most telling here isn’t any single breakthrough, but the convergence you’re describing between memory, architecture, and agency.
When continual learning, long-horizon agents, and world models all mature at once, “model” stops being the unit of progress — systems become the unit.
It feels like we’re moving from scaling intelligence to operationalizing cognition: not how smart a model is in isolation, but how reliably it can think, remember, and act inside a real environment over time.