
Token Burnout: Why AI Costs Are Climbing and How Product Leaders Can Prototype Smarter
How Jevons' Paradox infiltrated AI development and what product teams are doing about it.


If you are in a lean startup and building products with LLMs, then you know the importance of having a good, ready-to-use API. You don’t need to fine-tune it, just wrap it around your idea and start building. All you need to do is have enough budget to cover the LLM inference cost.
But here’s the twist. While per-token prices are dropping, the total token consumption cost or “cost per token over time” is rising. This means that every additional week of experimentation could consume the budget originally allocated for shipping core features.
That’s expensive.
While I think APIs are extremely good and provide a good ROI, you should use them thoughtfully and strategically. And in fact, the LLM inference costs have gotten pretty cheaper by a factor of 1,000 in just 3 years.
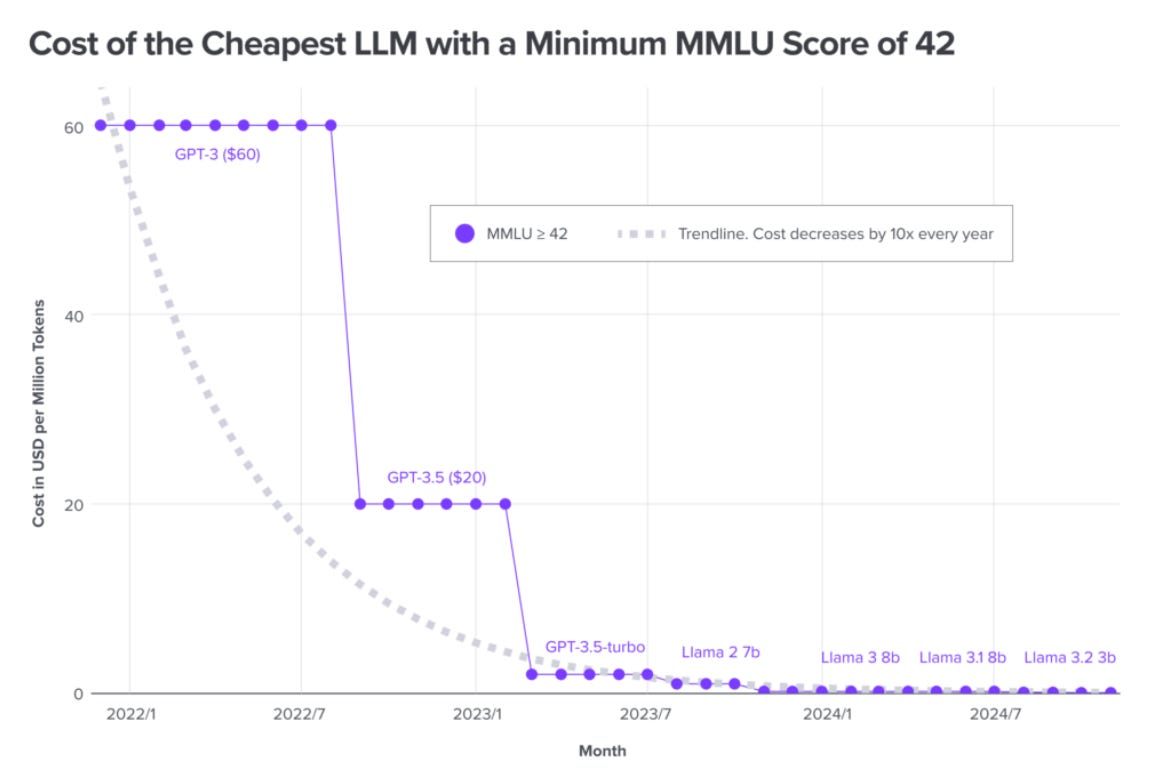
Yet, the cost of prototyping is rising. It is called the Jevon’s paradox.
“…increased efficiency in resource use can lead to increased overall consumption of that resource, rather than the expected decrease.”
To put it in AI-product building terms, “Cheaper tokens lead to increased overall consumption.”
This is (as we are seeing) turning efficient tools into budget black holes.
As product builders, we can easily address this issue by adopting simple strategies with engineering tactics.
The New Token Economics
From Figure 1, we see that the token cost leading LLMs like GPT-3.5 equivalents have fallen dramatically. The price of tokens has decreased from $20 per million tokens in late 2022 to around $0.40 per million tokens in August 2025. But the consumption rate has increased.
This price drop should have meant cheaper experimentation, but instead, new forms of token usage have emerged. This can be traced to the fact that we have two new categories of token usage:
Reasoning tokens: The test-time compute that uses internal CoT to produce better results via reasoning.
Agentic tokens: The tokens that are produced by agents when they access various tools.

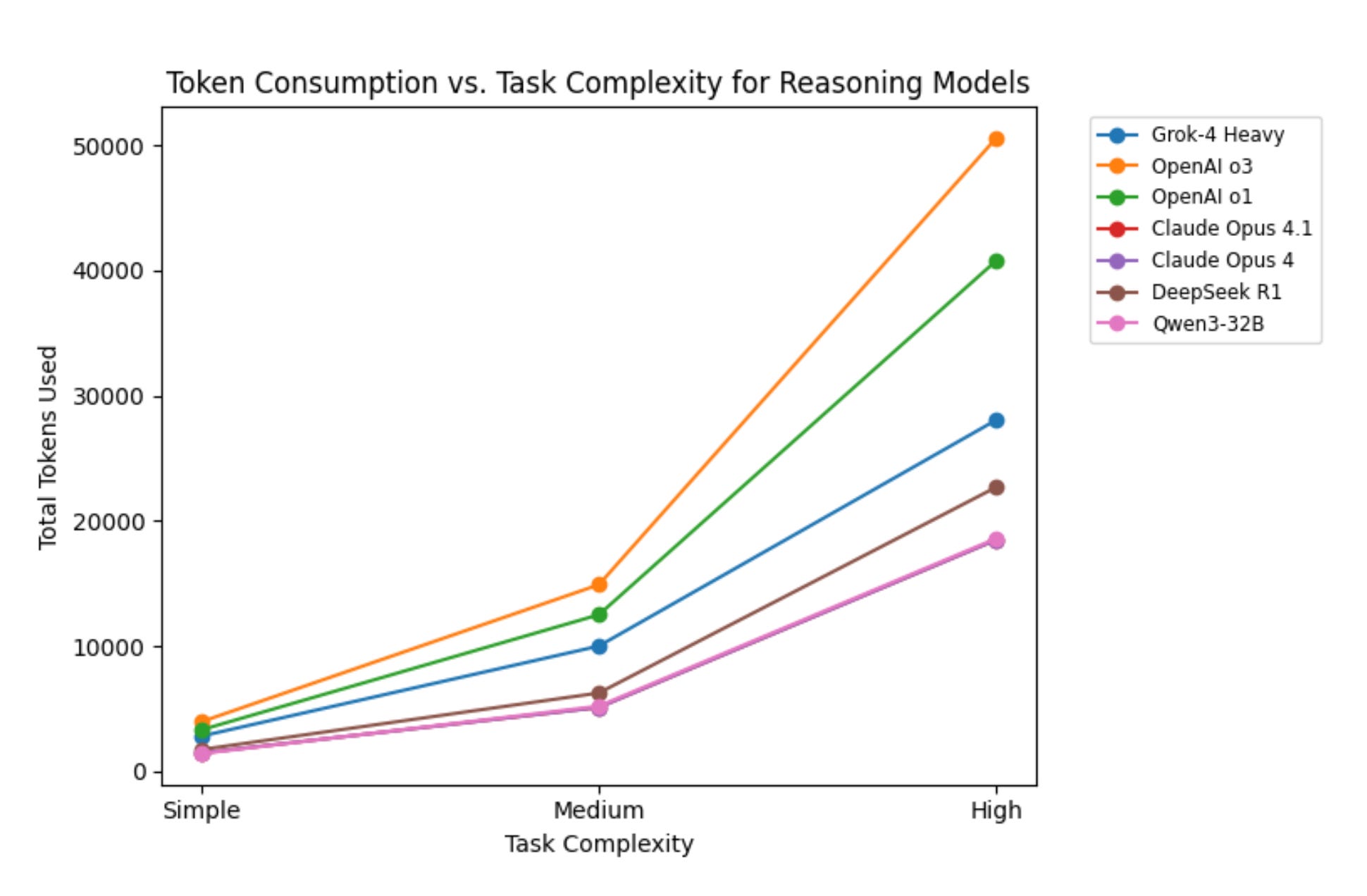
Bear in mind that today’s LLMs consume both reasoning and agentic tokens. Although the inference cost has come down, prototyping and working with agents can consume a lot more (like 100x) tokens during inference. This is especially visible when comparing coding agents — Codex uses 3x fewer tokens than Claude Code on identical tasks, as we cover in our Claude Code vs OpenAI Codex comparison.
On top of that, we as builders iterate on our products unless we get them right or at least workable.
I saw X post from Shopify VP & Head of Eng, where he is “...seeing a [concerning] trend where CTOs/CEOs [question whether they] can afford an extra $1k–$10k/month per engineer [due to LLM usage in tools].”
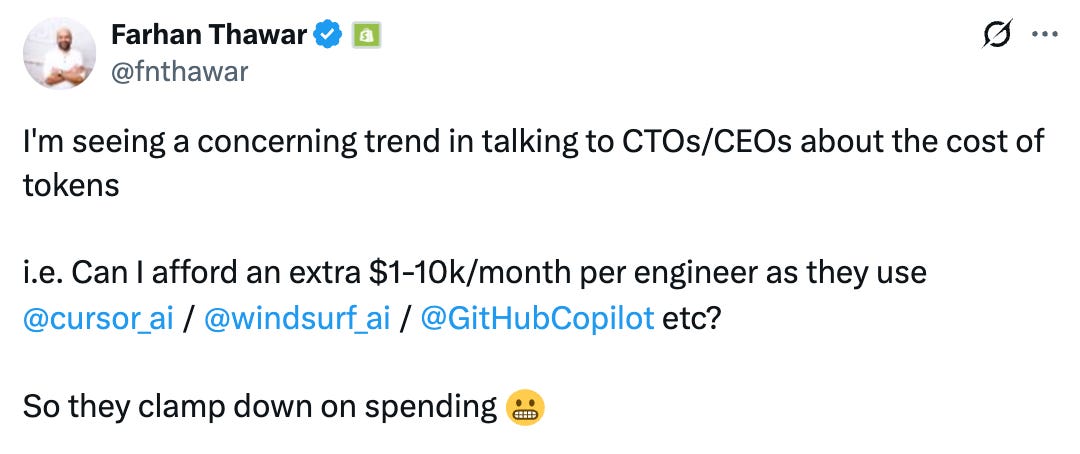
He points out something very interesting.
“If your engineers are spending $1k/month MORE because of LLMs and they are 10% more productive, then that is TOO CHEAP. i.e. Anyone would KILL for a 10% increase in productivity for only $1k/month. Totally worth it” – Farhan Thawar
Another thing is that when you get your hands on LLMs like Grok-4 Heavy, Claude Opus 4.1, Gemini 2.5 pro, or o1-pro you automatically want to try out something new. This will eventually lead to higher token consumption.
“If you are worried about engineers spending $10k/month on tokens -> I wouldn't worry. If they are spending this much, DM me because I want to know what exciting things they have conjured up to spin up LLMs on. If they are spending this much AND getting value out of it, you are winning (DM me!)” – Farhan Thawar
Sometimes, an engineer uses brute force to integrate a feature within a given time constraint or deadline. This is another reason why cost rises.
No thoughtful prompting, vibing (without proper ideation) is a red flag.
If you would just observe, token costs are climbing not from prices, but from our relentless experimentation and agentic workflows. As Thawar wisely notes, if that spending drives real productivity, it's a steal.
But how do we control this without killing innovation? Let’s dive into practical strategies from PM and engineering angles.
Smart Spending in Practice
Let’s start with the PM lens.
First and foremost, it's all about chasing ROI.
Use premium models like o1-pro for planning phases; this will help you understand your requirements. You can also use Claude Code to plan and learn.
Also, if you want to learn your code base to integrate a desired feature then Claude Code is the best. I also found this post on LinkedIn from David Kelly, where he shares how he uses Claude Code for product planning.
I think then you should pivot to cheaper ones for execution. These days GPT-5 series APIs are cheaper.
As Farhan Thawar highlights, if engineers burn $1k/month extra on LLMs for a 10% productivity boost, that's a bargain.
Set token budgets by prototype stage.
Reward value-driven spends. This keeps costs in check while fueling innovation. If you find that you will need models like Opus 4.1 for additional workload, please use it. If you are choosing expensive models to work with, then make sure that they are used for certain occasions, not always as the default.
Lastly, be very much mindful of your domain expertise. Know your startup, product, customers, and tech stack inside out. This will give you clarity as to which API to use.
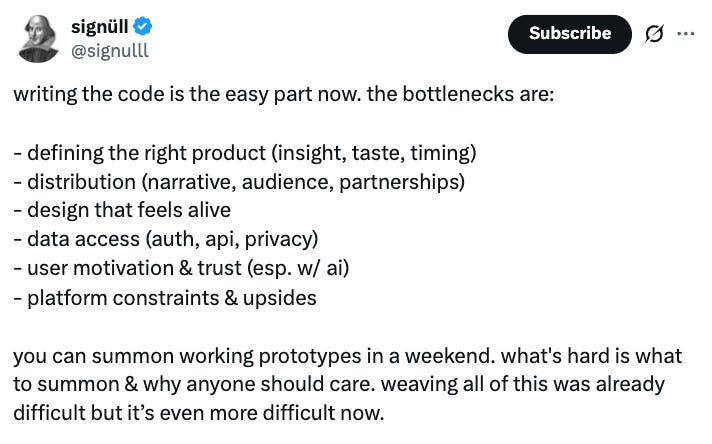
Source: signulll on X
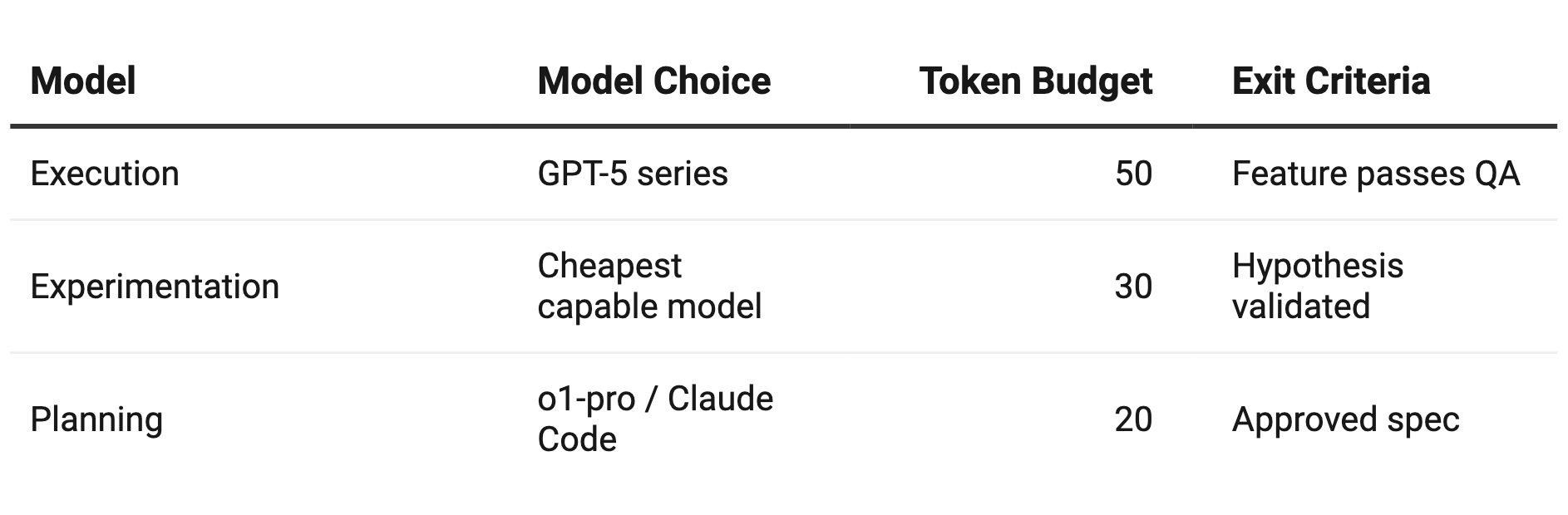
Once PMs set the stage with budget and model mix rules, engineers can execute the cost control playbook.
Now, over to the engineers.
I believe in optimizing through fine-tuning. Swap GPT-oss for Mixtral 8x7B on 100-500 data pairs. It will reduce your costs 5-30x without quality dips. Add caching and summaries. Pre-sort data, cache outputs to dodge raw token waste. It alone can save 30-50% on inference.
Compress prompts too, shrinking 10,000 tokens to half or even one-third while holding 95% performance. Limit outputs with clear constraints to curb rambling.
Blend them in hybrid workflows. Match models to use cases like Gemini Flash, GPT-4o for triage, Claude Opus 4.1, or 4 for coding.
Use prefix sharing for data reuse, putting instructions after reusable content to maximize caching.
Explore LoRA (low-rank adaptation) for lightweight adaptations, further reducing fine-tuning costs. LoRA lets you fine-tune large models cheaply by updating only a small fraction of their weights.
If you are using Claude Code with Opus 4.1, then you can keep a .md file, which will serve as a memory and knowledge database. This will be very effective as you will not have to provide coding and retrieval instructions.
Human smarts turn AI into a cost-saver, not a burner.
The Leader's Edge
AI costs climb with surging usage, despite per-token drops. Harder and complex tasks with brute force will consume more tokens.
But smart leaders master this burnout. They blend model mixes and knowledge database via .md files and caching for efficient prototypes. But more importantly, they ensure that they are aware of the product. They always have a narrative, a definition, and a purpose for your product.
Proof stacks up. a16z charts show inference costs plunging 1,000x in three years, yet Jevons' Paradox fuels consumption booms. Fine-tuning slashes bills. Prompt tweaks and caching save 30-50% on tokens, per AI research.