
Understanding Multimodal Large Language Models
A Systematic Analysis of How Integrating Multiple Perception Channels Reshapes Language Model Capabilities


Introduction
AI systems can now see, hear, and understand like never before. Multimodal Large Language Models (MLLMs) combine different perception channels into unified systems. This marks a turning point in how machines interact with our world.
Recent breakthroughs have transformed the AI landscape:
OpenAI's GPT-4V processes both images and text
Google's Gemini 2.5 reasons across different input types
Meta's Llama 4 handles context windows of 10 million tokens
DeepMind's Flamingo pioneered visual-language understanding
Think of MLLMs as digital brains with multiple senses. They don't just switch between modalities – they blend them together. A doctor might show an X-ray to such a system while asking a complex question. The MLLM understands both inputs together, not separately.

In this article, we'll explore:
How multimodal AI evolved from single-purpose systems
The mechanisms that allow cross-modal understanding
Innovative architectures that connect different perception channels
Real-world applications changing how we work
Challenges researchers must overcome next
Let's examine how combining vision, text, and audio creates AI systems with richer understanding capabilities. These advances open exciting possibilities while presenting new computational and ethical questions we must address.
Foundations of Multimodal Large Language Models
Historical Context and Evolution
The journey of multimodal language models began with traditional text-only systems. These early models processed language but lacked perception in other formats. The area evolved as researchers recognized the limitations of single-modality systems.
In 2021, OpenAI launched CLIP (Contrastive Language-Image Pre-training). This marked an important step toward multimodality. CLIP trained on 400 million image-text pairs using contrastive learning. Contrastive learning aligns images and text in a shared embedding space. It enabled zero-shot image recognition capabilities that were previously impossible with text-only models.

Before CLIP, most systems tackled vision-language tasks with specialized architectures. These early multimodal systems typically used separate networks for different modalities. For example, image captioning systems combined a CNN for images with an RNN for text generation.
An actual watershed moment arrived in 2022 with DeepMind’s Flamingo model. Flamingo became widely regarded as the “GPT-3 moment” for multimodal AI. It accepted mixed sequences of images and text. Then, it generated smooth responses about the visual content.
Theoretical Underpinnings
Multimodal LLMs extend traditional language models by processing many types of data simultaneously. They integrate text with images, audio, or video inputs. This integration requires sophisticated architectures that connects different modalities.
The core theoretical challenge involves creating meaningful representations across modalities. Text exists as discrete tokens. Images are pixel grids. Audio presents as continuous waveforms. MLLMs must translate these diverse formats into compatible representations.
Most MLLMs use dedicated encoders for each modality. These encoders convert inputs into shared latent spaces. The model then processes these unified representations through transformer-based architectures.
Rationale for Multimodal Integration
Multimodal integration offers several compelling advantages over unimodal approaches. Human perception combines many senses to understand the world instinctively. MLLMs mirror this capability by processing diverse information channels.
Single-modal systems face inherent limitations. Text-only models have a hard time with visual ideas and space. Also, vision-only systems can't do symbolic reasoning. By combining modalities, MLLMs overcome these individual weaknesses.
The integration of many perception channels enables richer context understanding. This makes user experiences more intuitive. People can communicate using language, images, or sound.
MLLMs also open new application possibilities that are impossible with single-modality systems. These include visual question answering, image-guided text generation, and multimodal dialogue systems.
Architectural Innovations and Processing Mechanisms
Model Architectures
Most multimodal language models build upon transformer-based architectures. These models integrate multiple perception channels through specialized components. The core challenge involves connecting modalities while preserving their unique properties.
Two main architectural approaches have emerged:
Modular Designs: Separate encoders for each modality connected to a central language model
Unified Transformers: Single networks that process all modalities through one stack

Models like Flamingo exemplify the modular approach. They combine a frozen image encoder (CLIP vision model) with a frozen language model (Chinchilla). Small trainable interfaces connect these components. This approach preserves existing knowledge while adding multimodal capabilities.

Alternatively, models like Kosmos-1 use unified transformers trained from scratch on mixed-modality data. This approach allows seamless fusion but requires more extensive training resources.
Data Fusion Techniques
Data fusion represents how models combine information across modalities. Two primary approaches exist:

Cross-modal attention mechanisms serve as critical bridges between modalities. These components allow the model to attend to relevant information across different inputs.
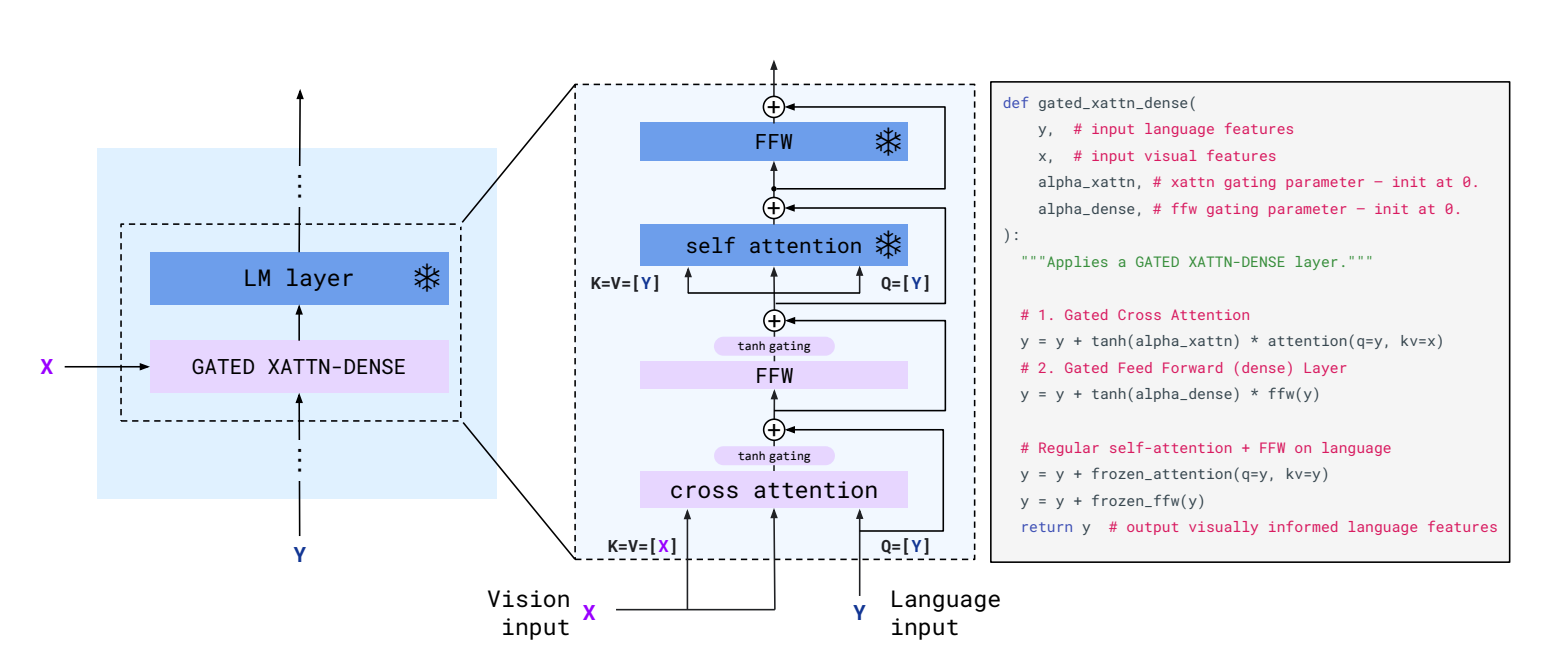
For example, in Flamingo, gated cross-attention blocks enable the language model to focus on specific image regions when generating text.
Processing Pipelines
The processing workflow in multimodal models typically follows these steps:
Input Encoding: Convert raw inputs (images, text, audio) into embeddings
Modality Alignment: Project embeddings into compatible spaces
Cross-Modal Reasoning: Apply attention mechanisms across modalities
Output Generation: Produce responses based on integrated understanding
Pre-processing is essential for each modality. Images typically undergo patch extraction, normalization, and feature extraction. Audio inputs often convert to spectrograms before processing. Text requires tokenization to discrete symbols.

Feature extraction strategies vary by modality:
Images: Vision transformers or CNNs extract spatial features
Audio: Spectrogram analysis captures frequency patterns
Text: Embedding layers convert tokens to vectors
These diverse processing mechanisms enable models to create unified representations from heterogeneous inputs, facilitating proper multimodal understanding.
Integrating Multiple Perception Channels
Types of Perception Channels
Multimodal systems process various types of sensory inputs that mirror human perception. Each channel provides distinct information about the world.
Visual perception forms the foundation of many multimodal systems. Models like GPT-4V can analyze images to identify objects, read text, interpret diagrams, and understand spatial relationships. Visual data captures physical attributes, colors, and arrangements that text alone cannot describe.

Source: GPT-4 Technical Report
Auditory inputs enable processing of speech, music, and environmental sounds. Models utilizing audio can transcribe speech, detect emotions from tone, and identify sound events. This adds temporal understanding that static visuals lack.
Textual information provides explicit symbolic knowledge. Text excels at conveying abstract concepts, definitions, and precise instructions. It remains the primary output format for most current systems.
Additional perception channels under development include:
Video (temporal visual sequences)
3D spatial data (for AR/VR applications)
Sensor readings (temperature, pressure, etc.)
Integration Strategies
Combining heterogeneous data types requires sophisticated alignment strategies. The primary challenge involves creating compatible representations across fundamentally different formats.
Common integration approaches include:

Synchronization across modalities presents unique challenges. Audio and video have temporal dimensions. Images are spatially oriented. Text follows sequential logic. Models must align these different organizational structures.

This diagram shows how DeepMind's Gato works as a truly versatile AI system. Unlike models that handle only text or images, Gato processes many different input types through a unified approach.
At the top and sides, you can see various input streams flowing into the central processing area. Text prompts like "I'm going to London" enter from the left. Atari game images and joystick actions come from the upper section. Robot movement controls appear at the bottom left. Question-answer pairs about images feed in from the bottom.
All these diverse inputs get transformed into a standard format - the colorful batched input grid in the center. The colors represent different data types: orange for text, purple for discrete actions, yellow for continuous movements, and pink for images.
The Gato model (blue box) processes this standardized information and produces masked, shifted targets shown on the right side. This allows the model to predict what comes next, regardless of whether it's playing a game, answering a question, or controlling a robot arm.
What makes Gato special is its ability to handle such different tasks without needing separate systems for each one. This represents a major step toward general AI systems that can seamlessly switch between different skills and input types - just like humans do when we move from reading to playing games to answering questions about what we see.

One effective technique is the perceiver resampler used in Flamingo. This component transforms variable-length visual features into a fixed number of tokens that can be processed alongside text.
Case Examples
Several pioneering systems demonstrate different integration approaches:
Example 1: Flamingo utilized a frozen CLIP vision encoder and pre-trained language model (Chinchilla). Its innovative gated cross-attention mechanism enabled communication between modalities without extensive retraining.
Example 2: Gemini 2.5 takes integration further by handling text, images, audio, and video simultaneously. While implementation details remain proprietary, Google reports that Gemini processes these inputs in a unified manner rather than sequentially.

Example 3: PaLM-E demonstrates an embodied approach. This system processes robot sensor data (visual inputs) through encoders and injects the resulting embeddings into the text stream. This creates "multimodal sentences" combining visual and textual tokens.
These varied integration strategies highlight the evolving approaches to combining perception channels. Each system balances computational efficiency against integration depth.
Impact on Language Understanding and Generation
Enhanced Contextualization
Multimodal models dramatically improve language understanding through added perception channels. Traditional text-only models often miss contextual nuances that visual or audio inputs clarify.
Consider these concrete improvements:
Visual grounding: Models can connect language to specific image regions
Disambiguation: Visual context resolves ambiguous references
Situational awareness: Scene understanding enables appropriate responses
In practical settings, these capabilities transform user interactions. For example, the Be My Eyes application uses GPT-4V to help visually impaired users understand their surroundings. A person can take a photo of a refrigerator's contents and ask, "What can I make for dinner?" The model identifies ingredients and suggests recipes—a task impossible without visual context.
Visual inputs also enable models to understand implicit information. When shown an image of a traffic sign, models can recognize danger warnings or navigation instructions without explicit text descriptions.

Innovative Applications
Multimodal capabilities open entirely new application domains across industries:
These applications extend beyond traditional text generation. In creative fields, models can generate descriptions of artwork that incorporate style elements, emotional impact, and cultural context—all informed by visual analysis.
For conversational agents, multimodality creates more natural interactions. Users can communicate through their preferred modality, switching between showing and telling as humans naturally do in conversation.
Quantitative and Qualitative Performance Metrics
Benchmark results demonstrate substantial performance improvements when adding multimodal capabilities:

This image showcases performance metrics for leading AI models across multiple benchmarks. Llama 4 Behemoth leads in several categories, scoring 95.0 on MATH-500 and 85.8 on Multilingual MMLU. Claude Sonnet 3.7 performs well in reasoning tasks with an 82.2 on MATH-500. Gemini 2.0 Pro shows strong results on reasoning benchmarks but lacks data for multilingual tasks. GPT-4.5 demonstrates competitive scores in image reasoning (MMMU) with 74.4 and multilingual capabilities at 85.1.
The table reveals how these models handle different types of intelligence tests, from mathematical reasoning to visual understanding, highlighting the varied strengths of multimodal AI systems that can process both text and images.

Similarly, this image compares AI models with a focus on cost and specialized abilities. Llama 4 Maverick offers balanced performance at $0.19-$0.49 per million tokens, while Gemini 2.0 Flash stands out for cost-efficiency at just $0.17. DeepSeek v3.1 excels in coding with 45.8/49.2 on LiveCodeBench but lacks multimodal support. GPT-4o shows high costs at $4.38 per million tokens but delivers strong document understanding with 92.8 on DocVQA.
The table highlights how these multimodal systems handle tasks requiring both visual and language understanding, plus long-context processing for translating half and full books, with Llama 4 Maverick scoring 54.0/46.4 and 50.8/46.7 respectively on these translation tasks.

This image presents benchmark results for more compact AI models. Llama 4 Scout leads the pack despite its smaller size, achieving 94.4 on DocVQA and 88.8 on ChartQA, showing strong visual understanding abilities. Larger models like Llama 3.3 70B lack multimodal support entirely, focusing solely on text processing. Mistral 3.1 24B performs impressively on document understanding with 94.1 on DocVQA. Gemini 2.0 Flash-Lite balances size and capability with decent scores across categories.
The table reveals how even smaller multimodal models can effectively interpret images, charts, and documents while maintaining reasonable performance on coding and reasoning tasks, though they show lower scores on translation benchmarks compared to their larger counterparts.
Beyond quantitative measures, qualitative assessments reveal emergent capabilities:
Solving visual puzzles without explicit training
Understanding humor in memes and visual jokes
Writing functional code from hand-drawn sketches
These improvements stem from the model’s ability to integrate information across modalities. The visual context doesn't just add information—it fundamentally transforms how the model approaches language understanding and generation tasks.
Future Directions, Challenges, and Ethical Considerations
Emerging Research Trends
The field of multimodal LLMs is evolving rapidly with several exciting directions emerging. Future models will likely focus on deeper integration of perception channels through architectural innovations.
Recent developments from Meta and Google point to two key trends:
Native multimodality: Rather than bolting on vision capabilities to text models, companies are building models with early fusion that integrate modalities from the ground up. Llama 4 uses an early fusion approach that seamlessly integrates text and vision tokens into a unified model backbone.
Mixture-of-experts architectures: These models activate only a fraction of parameters for each task, improving efficiency. For example:
Llama 4 Maverick uses 128 routed experts
Only ~17B parameters are active during inference (out of 400B total)
This allows powerful models to run on single host machines
Another emerging trend is the divergence between two paradigms:

Technical and Computational Challenges
Processing multiple modalities simultaneously creates significant computational demands. Key challenges include:
Context length handling: Managing extremely long contexts (up to 10M tokens in Llama 4 Scout) requires novel architectural approaches like interleaved attention layers without positional embeddings.
Training efficiency: Multimodal models require massive datasets and compute resources. Meta reports using FP8 precision and 32K GPUs to achieve 390 TFLOPs/GPU when training Llama 4 Behemoth.
Inference costs: Running these models requires substantial hardware. GPT-4.5 is described as "a very large and compute-intensive model, making it more expensive" than previous versions.
Resource constraints also create accessibility issues. While some models like Llama 4 Scout are designed to run on a single GPU, the most capable systems remain out of reach for many developers and researchers.
Balancing capabilities with accessibility will be crucial. Future research must focus not only on capability improvements but also on developing techniques that reduce computational requirements without sacrificing performance.
Conclusion
Multimodal Large Language Models represent a fundamental shift in artificial intelligence. These systems now integrate diverse perception channels to understand our world more comprehensively.
Key developments include:
Pioneering models like CLIP linked images and text in shared spaces. This laid the groundwork for understanding visual language.
Advanced architectures like Flamingo that built upon CLIP's vision encoder to enable few-shot multimodal learning
MetaCLIP shows evolutionary improvements. It boosts data efficiency and improves representation quality. These enhancements go beyond what the original CLIP model offered.
Native multimodality approaches in models like Llama 4 that enable seamless processing across modalities
For product teams and AI leaders, multimodal LLMs offer compelling advantages:
Enhanced user experiences through interfaces that accept natural inputs like images alongside text
Simplified workflows that remove the need for different systems to manage various input types.
Expanded application possibilities in areas from content creation to accessibility tools
Competitive differentiation through capabilities that single-modality systems cannot match
Future challenges remain significant. Computational demands grow with each added modality. Training costs limit accessibility to leading systems. Ethical considerations around data representation require ongoing attention.
Despite these obstacles, multimodal LLMs open exciting possibilities. These systems help visually impaired users find their way. They also make human-computer interactions easier. In short, they change how we use technology.
Researchers are still evolving. They are looking for ways to integrate better. Also, they want to make these capabilities easier for developers everywhere.