
What is Context Engineering for AI Agents?
Learn why managing context—not just prompts— is essential for your AI products.


From Prompt Engineering to Context Engineering
Early AI development focused heavily on prompt engineering. This would include crafting clever, concise instructions to get desired outputs from language models. This approach worked well for simple tasks. Users learned to write effective zero-shot prompts or implement chain-of-thought prompting for basic reasoning.
Similarly, other prompting methods such as ReAct, Self-consistency, Decomposition, Tree-of-thoughts, etc., worked really well for complex tasks. But in the period of Agentic AI or AI Agents, a more better definition of workflow is required.
As applications grew more sophisticated, especially with AI agents and complex workflows, these approaches hit significant limitations. Simple prompts couldn't handle:
Multi-step reasoning requiring tool use.
Long-running conversations with memory.
Dynamic information retrieval from databases.
Coordination between multiple AI systems.
Context engineering emerges as the solution. In an X post, Andrej Karapathy wrote, "the delicate art and science of filling the context window with just the right information for the next step."
It is more than focusing on a single instruction.
This represents a fundamental shift from crafting sentences to architecting systems. Context engineering treats the entire pipeline before the LLM call as engineerable infrastructure. It includes:
Dynamic information gathering: RAG systems, API calls, database queries.
Memory management: Short-term conversation state and long-term knowledge.
Tool coordination: Making external functions available when needed.
Output structuring: Defining schemas and formats for consistent results.
For product teams, this shift means thinking beyond user-facing prompts to the complete AI system architecture. The magic isn't in finding the perfect instruction - it's in providing comprehensive, relevant context that makes the task genuinely solvable.
Why Context Engineering Matters for Your Product
Think of an LLM's context window as RAM. It has limited working memory that determines what the model can process. Just as an operating system carefully manages what goes into RAM, context engineering curates what information fills the LLM’s context window.
This isn’t just technical optimization. It’s the difference between reliable AI products and frustrating ones. Poor context management creates:
Context poisoning: Hallucinations contaminating future responses.
Context distraction: Too much information overwhelming the model.
Context confusion: Conflicting information causing errors.
Context clash: Disagreeing sources and instructions leading to inconsistent outputs.
For product teams, context engineering directly impacts:

AI agent failures arise from context problems, not model limitations.
When engineers say "context engineering is effectively the #1 job of engineers building AI agents," they're highlighting that the difference between a demo and a magical product lies in context quality, not clever prompts.
What is "Context" in the Age of AI Agents?
Context extends far beyond the user’s immediate question. Modern AI agents require multiple context types working together:
Static Context:
Prompts: Core behavior rules and examples. Prompt templates is another way of looking into it.
Tool definitions: Available functions and their parameters.
Output schemas: Response format requirements.
Dynamic Context:
User input: The immediate task or question. These can also be variables that you plug in to the prompt template.
Chat history: Short-term conversation memory.
Long-term memory: Persistent preferences and past learnings.
Retrieved knowledge: RAG results from databases or APIs.
Tool responses: Feedback from executed functions.
Workflow state: Information stored across agent steps.
Think of it as an orchestra where each instrument contributes to the final performance. Too little context leaves gaps in understanding. Too much creates noise and confusion.
Here’s a key insight. More information isn't always better. Effective context engineering means selecting the right combination for each specific task. A customer service agent needs different context than a research assistant, even when using the same underlying model.
This complexity explains why simple, prompt engineering approaches fail with sophisticated AI applications.
The Critical Need for Context Engineering in Agentic Systems
Why AI Agents Are Different
AI agents operate fundamentally differently from simple chatbots. They interleave LLM calls and tool executions across multiple turns, often for complex, long-running tasks.
This creates unique challenges:
Token Accumulation:
Each tool call generates feedback that stays in context.
Multi-step reasoning requires preserving intermediate results.
Context grows exponentially with task complexity.
Feedback Loops:
Tool responses inform the next LLM decision.
Previous actions constrain future choices.
Error recovery requires maintaining full execution history.
Consider a research agent analyzing market trends:
Initial query → Web search tool
Search results → Analysis prompt
Analysis → Database lookup tool
Database results → Synthesis prompt
Synthesis → Final report generation
Each step adds context. A 10-step workflow might consume 50,000+ tokens just from tool calling and feedback.
This means advanced AI features demand sophisticated token budgeting and context pipeline design. The agents that can handle truly complex, multi-step tasks are those with the best context management. This doesn’t necessarily mean the smartest base models.
The Pitfalls of Unmanaged Context: Performance, Cost, and User Experience
Let’s talk about pitfalls now.
Poor context management creates a number of problems. These can directly impact your product's viability. When context grows unchecked, you encounter multiple failure modes that hurt both business metrics and user experience.
Direct Failures:
Context window overflow: LLM simply stops working.
Token cost inflation: Expenses scale exponentially with context size.
Latency spikes: Longer context means slower processing. And if you are working with reasoning models, then you should learn how to wait and be patient.
Quality Degradation:
Context poisoning: Hallucinations contaminate future responses.
Context distraction. Believe me when I say AI can get distracted. Too much information overwhelms the model.
Context confusion: Irrelevant details skew outputs.
Context clash: Conflicting information creates inconsistencies.
User Trust Erosion: Consider Simon Willison’s experience with ChatGPT: the system unexpectedly retrieved his location from memory and injected it into an image generation request. This made him feel the context window "no longer belongs to him."

These aren't just technical problems. They’re product reliability issues that undermine user confidence.
Agent Failures are Context Failures
Most agent failures are no longer limitations of the model. They're context failures. The system around the LLM didn't provide adequate information for success. The context was insufficient, disorganized, or simply wrong.
Consider this example: A user sends "Hey Chen, just checking if you're around for dinner tomorrow."
Naive Agent:
Sees only: User message.
Responds: "Tomorrow works for me. What time?"
Result: Generic, unhelpful.
Magical Agent:
Gathers context: Calendar (fully booked), email history (informal tone), contact database (key partner), and available tools.
Responds: "Hey Tim! Tomorrow I am travelling back home. Can we meet this weekend?"
Result: Relevant, actionable.

The difference isn't a smarter model.
It's a comprehensive context.
Product teams should invest in data quality and retrieval precision rather than waiting for model improvements.
Core Strategies for Mastering Context Engineering
This section breaks down the four fundamental strategies for managing context in AI agents.
Strategy 1: Writing Context (Saving Information for Future Use)
Writing context means saving information or instructions. These must be saved or stored outside the context window. This practice preserves valuable token space while maintaining access to important data.
Scratchpads work like note-taking for agents within a single session. Anthropic's multi-agent researcher saves its initial plan to "Memory" because if the context exceeds 200,000 tokens, it gets truncated and the plan is lost.
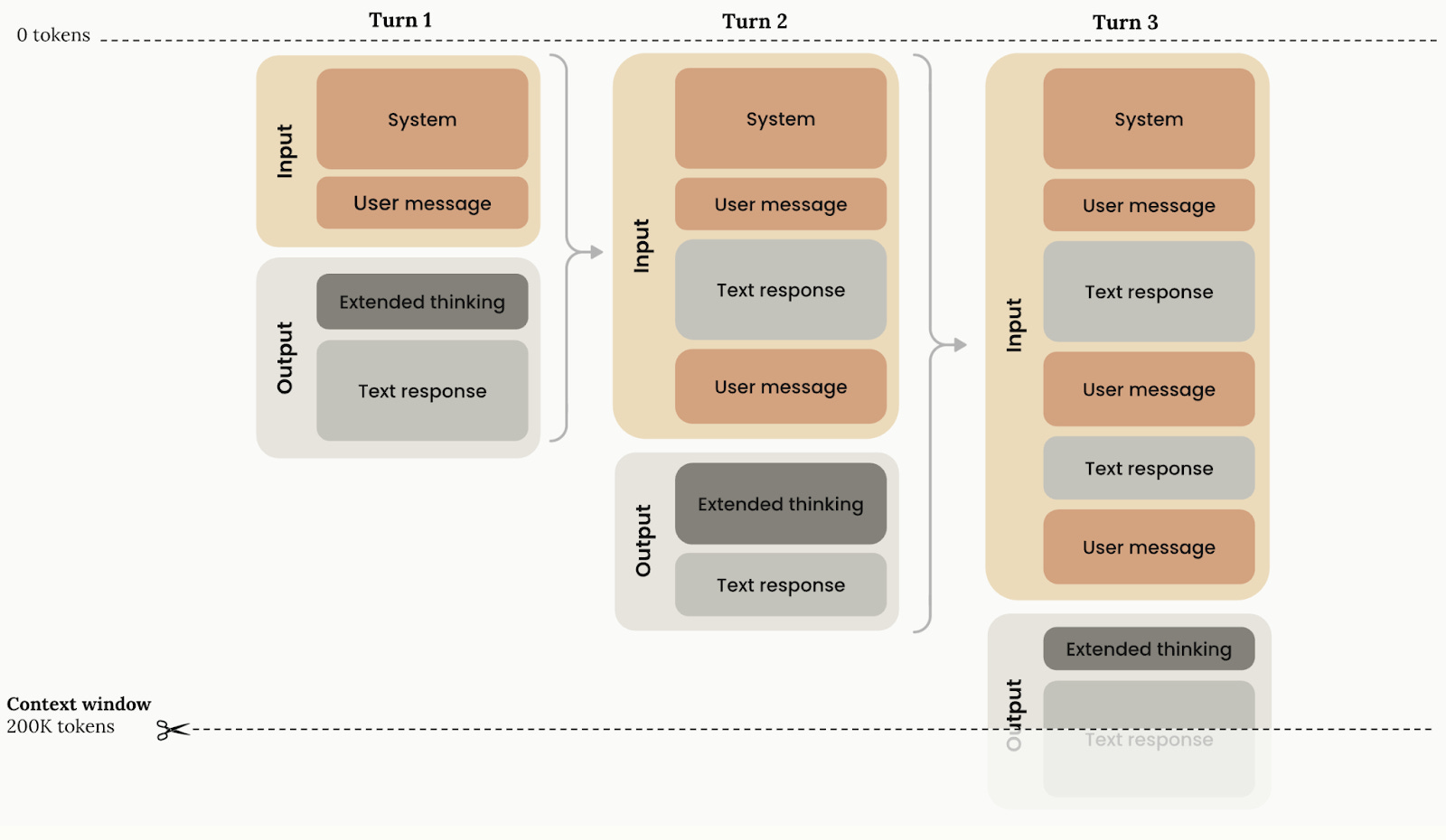
Implementation options:
File-based: Simple tool calls that write to disk.
Runtime state: Object fields that persist during execution.
Long-Term Memories: Unlike scratchpads, memories retain information across multiple sessions. Popular examples include:
ChatGPT: Auto-generates user preferences from conversations.
Cursor/Windsurf: Learns coding patterns and project context.
Reflexion agents: Create self-generated memories from task feedback.

For product teams, memories enable personalization and user retention by creating evolving, continuous experiences that improve over time.
Strategy 2: Selecting Context (Retrieving Just What's Needed)
Selecting context means pulling relevant information into the context window. Since we have a limited space to work with strategic selection becomes critical.
Targeted Retrieval from Scratchpads and State: When information lives in scratchpads or runtime state objects, developers can selectively expose specific parts to the LLM. This fine-grained control ensures the model only sees relevant information at each step. This helps in reducing noise and improving decisions.
Intelligent Selection from Long-Term Memories: Agents must choose relevant memories for each task:
Episodic memories: Few-shot or n-shot examples showing desired behavior.
Procedural memories: Instructions stored in files like CLAUDE.md or rules files.
Semantic memories: Facts relevant to the current context. These can be embeddings or RAGs.
For larger memory collections, embedding-based similarity search or knowledge graphs handle indexing and retrieval. Poor selection creates problems - like ChatGPT unexpectedly injecting location data into image requests.
Agentic RAG, too many tools create "model confusion" about which to use. Applying RAG to tool descriptions fetches only relevant tools. This can improve selection accuracy by 3-fold according to recent research.

Advanced Knowledge Retrieval RAG represents a “central context engineering challenge.” Code agents exemplify large-scale RAG, combining AST parsing, grep searches, knowledge graphs, and LLM-based re-ranking for semantic chunking and retrieval precision.
Strategy 3: Compressing Context (Optimizing Token Usage)
Compressing context means retaining only the tokens required to perform a task. This directly addresses context window limitations and cost concerns.
Context Summarization: Summarization manages token-heavy interactions by condensing information while preserving essential details. Claude Code's "auto-compact" feature demonstrates this. When context exceeds 95% capacity, it summarizes the whole user-agent trajectory.
Summarization applies at multiple levels:
Full trajectory: Complete conversation history.
Specific points: Post-processing token-heavy tool calls.
Agent boundaries: Knowledge hand-off between agents.
Effective summarization can be challenging. Some companies use fine-tuned models specifically for this task. This highlights the engineering investment required.
Context Trimming: Unlike summarization, trimming uses filtering or "pruning" approaches. This includes:
Hard-coded heuristics: Removing older messages from lists.
Learned approaches: Trained context pruners for specific domains.

Trimming offers immediate, predictable context reduction for strict length requirements.
Strategy 4: Isolating Context (Structuring for Clarity and Efficiency)
Isolating context means splitting it up to help agents perform tasks more effectively. This reduces the cognitive load on individual LLMs. It also manages token usage strategically.
Multi-Agent Architectures: Multi-agent systems split context across sub-agents. Each with their own context windows, tools, and instructions. This enables the separation of concerns where different agents handle specialized subtasks in parallel.
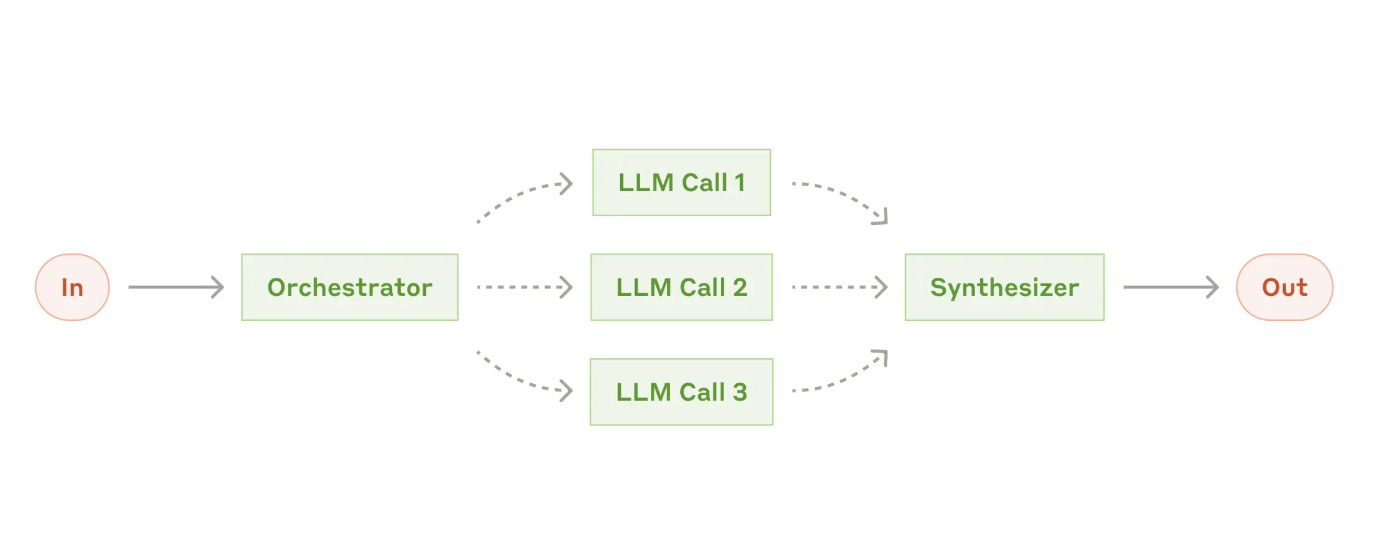
Benefits include expanding total token capacity across the system. Challenges include increased costs (up to 15x more tokens than single-agent chat) and coordination complexity.
Sandboxes and Execution Environments: Sandboxes isolate code execution from the LLM's context window. They persist state across multiple responses. This essentially avoids the need to embed the context at every call or step.
This approach excels at handling token-heavy objects like images or audio files, with only selective results passed back to the LLM.
This internal structuring improves reliability and simplifies debugging complex agent workflows.
Conclusion
In this article, we discussed what Context engineering is, the need for it, and core strategies to master it.
I purposely kept the article limited to these five sections. This term was coined a couple of weeks back. There a lot of things that needs to be explored. But the basic idea more or less will remain the same.
To recapitulate.
Context engineering is a critical craft that teams and leaders building with LLM should aim to master. It’s fundamentally about designing and building dynamic systems that provide the correct information and tools, in the right format, at the right time, giving LLMs everything needed to accomplish tasks effectively.
This discipline transforms products from naive demos to magical experiences. The difference isn’t in the underlying model. It's in the quality of the context provided.
Key Success Factors:
Strategic information selection over information overload.
Dynamic context assembly rather than static prompts.
Systematic measurement of context effectiveness.
Iterative optimization based on real performance data.
For product leaders, investing in context engineering means investing in:
Product reliability and user trust.
Cost efficiency through optimized token usage.
Competitive differentiation through superior AI experiences.
Future-proofing as AI capabilities continue advancing.
I believe the teams that master context engineering will build the AI products that users consider indispensable. This isn’t just about better prompts—it's about architecting intelligent systems that consistently deliver value.