
What is prompt caching? How can product managers leverage it to develop user-friendly products?
A comprehensive review with Anthropic implementation.


Building responsive AI products is challenging. Users expect instant answers, but large language models can be slow and expensive when processing extensive content. Enter prompt caching—a technique that dramatically improves AI performance by storing and reusing context instead of reprocessing it every time.
Prompt caching works by identifying static parts of prompts and storing them temporarily. When users ask follow-up questions, only the new input gets processed against this stored context. This reduces latency by up to 80% and cuts costs by 50-90% for repeated interactions with large models like Claude and GPT.
For product teams, this means you can finally build AI features that were previously impractical. Analyze entire documents, process large codebases, or create educational tools that respond to questions about lengthy course materials—all while maintaining responsiveness and controlling costs.
This article covers:
What prompt caching is and how it works
Technical foundations and implementation mechanisms
Business benefits and strategic advantages
Practical code examples using Anthropic’s Claude API
Best practices, common challenges, and future trends
Note: You can find the notebook related to this article here. I recommend you read this article alongside the related Colab notebook, where the codes are available. This will help you understand the topic better.
What is Prompt Caching
Prompt caching stores and reuses frequently used instructions, inputs, queries, or content in AI conversations. Think of it like remembering a conversation’s context without starting over each time. When you interact with AI systems like Claude or GPT models, prompt caching lets the system recall static information—like lengthy documents or detailed instructions—without processing it repeatedly.
So, how does it actually work? The AI system or LLM identifies the static parts of your prompt and stores them temporarily. When you ask follow-up questions, your new input gets processed against this stored context. This dramatically cuts down processing time and costs.
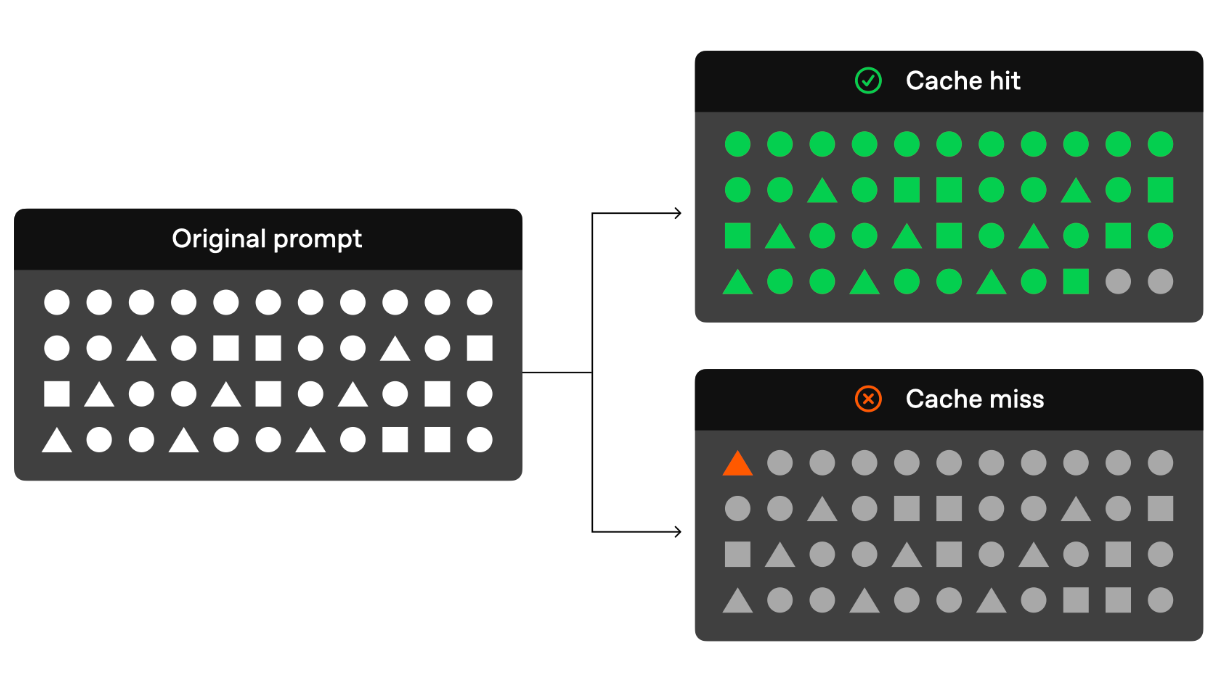
The bens are pretty significant:
Faster responses: Cached prompts reduce latency by up to 80% since the system doesn’t reprocess information it already knows
Lower costs: You can save between 50-90% on input token costs for repeated interactions
Better user experience: Quicker response times mean smoother conversations.
Prompt Caching performance comparison
OpenAI model cost savings

*excludes gpt-4o-2024-05-13 and chatgpt-4o-latest
Anthropic performance improvements by use case

As shown above, prompt caching delivers significant performance improvements across both OpenAI and Anthropic models. OpenAI models consistently see 50% cost reductions for text inputs, while Anthropic's implementation shows dramatic improvements in both response times and costs across various real-world scenarios. These benchmarks demonstrate why prompt caching is becoming essential for production AI applications that handle large documents or maintain complex conversational contexts.
Now let’s say, if you upload an entire book to an AI assistant, prompt caching lets you ask multiple questions about the content without paying to process the whole book each time. This makes analyzing large documents, reviewing codebases, or building educational tools much more practical.
In real-world applications, prompt caching proves valuable for:
Document analysis (books, research papers, legal contracts)
Code reviews and technical documentation
Customer service bots handling common questions
Educational platforms where students ask questions about course materials
Each AI provider implements caching a bit differently. Anthropic’s Claude caches system prompts for 5 minutes, while OpenAI’s implementation caches prefix for 5-10 minutes (occasionally up to an hour during off-peak times).
The thing is, you’ll need to structure your prompts carefully to maximize the benefits. Put static content at the beginning and variable content at the end. This way, the system can easily identify what to cache.
Just remember that caches eventually expire, and there are some limitations around prompt structure and supported models. But prompt caching represents a serious efficiency breakthrough for applications dealing with large documents or repetitive questions.
Technical foundations and mechanisms
Let’s dive into how prompt caching actually works under the hood. The architecture typically relies on in-memory storage for speed, though some implementations use disk-based solutions for persistence. Basically, the system needs to quickly retrieve cached prompts without adding significant overhead.
Most prompt caching systems use these key components:
Cache lookup mechanism: When a prompt arrives, the system checks if a matching prefix exists in the cache using efficient search algorithms.
Storage layer: This keeps the cached prompts accessible for quick retrieval. In-memory caches provide faster access but are limited by RAM, while disk-based options offer persistence at the cost of speed.
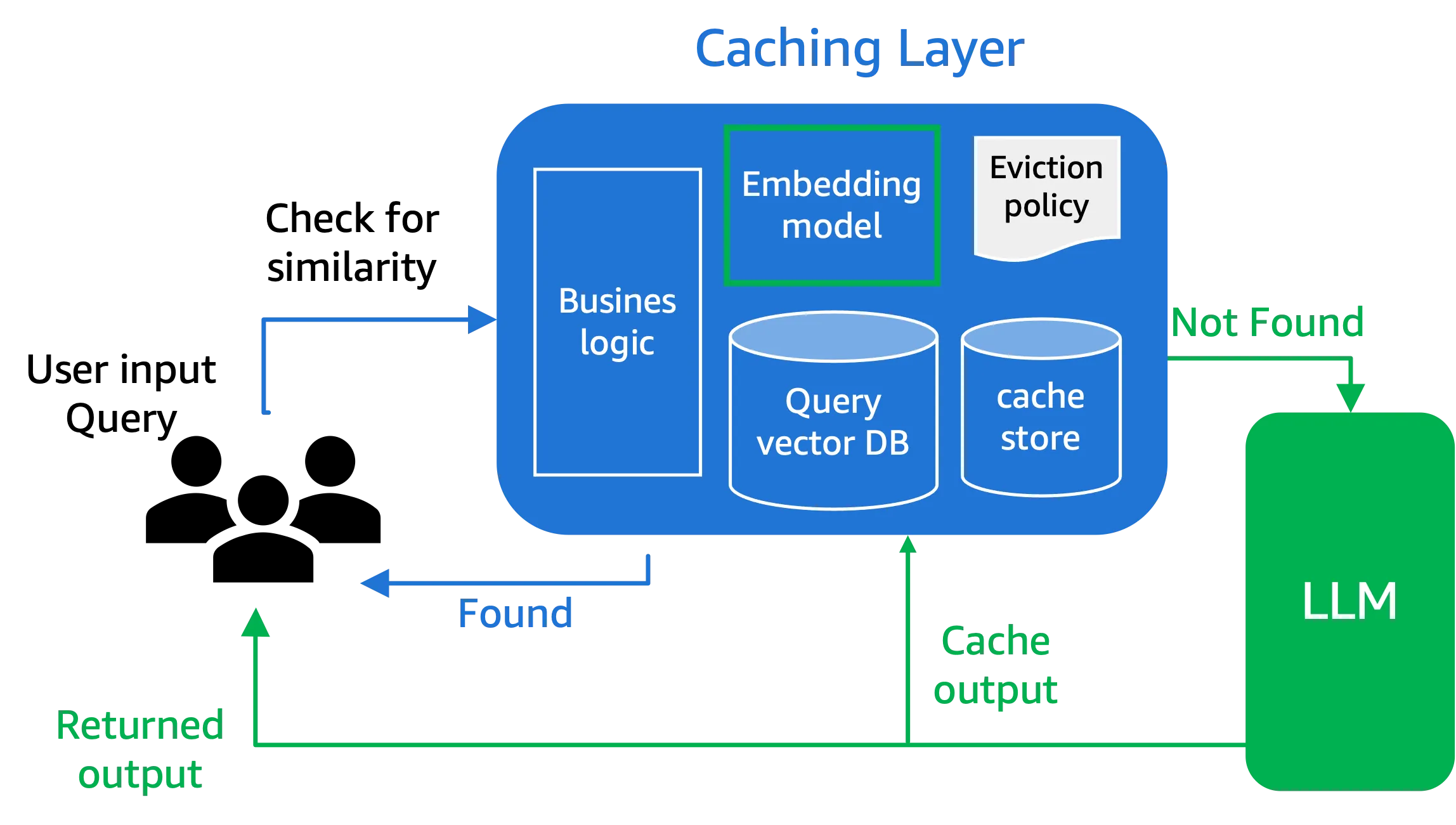
Eviction policies: Since cache space is limited, algorithms like Least Recently Used (LRU) determine which prompts to remove when space runs out. This ensures frequently accessed prompts remain available.

The data structures powering prompt caching include:
Hash tables: For rapid lookup of exact matches
Vector embeddings: Enable similarity matching for fuzzy caching
Time-based expiration queues: Track cache freshness
For Python implementation, you can use several libraries:
# Simple caching with Python's built-in tools
from functools import lru_cache
@lru_cache(maxsize=100)
def process_prompt(prompt):
# Processing logic here
return responseWell, more advanced implementations might leverage Redis for distributed caching or use specialized libraries like cachetools for memory-efficient storage.
If you’re working with LLMs in Python, frameworks like LangChain and LlamaIndex offer built-in prompt caching capabilities. For example, with Anthropic’s Python client, you can implement caching by adding the cache_control parameter to your content object with the prompt-caching beta header.
The thing is, effective, prompt caching requires balancing memory usage with performance gains. Too small a cache means frequent misses, while too large a cache consumes excessive resources without proportional benefits.
Business benefits and strategic Implications
Implementing prompt caching delivers real-world performance gains that translate directly to business value. Let's explore what this means for your products and users.
Performance improvements
The speed improvements are honestly impressive. According to OpenAI's documentation, prompt caching can reduce latency by up to 80% for long prompts. This happens because the system doesn’t need to reprocess information it already has.
In practical terms, this means:
Responses arrive 2-3x faster once the prompt is cached
Server loads decrease significantly
Applications become more responsive and feel more natural
For example, in tests with multiple LLMs, including Llama3, response times dropped from 151.79 seconds to just 42.48 seconds when using cached prompts.
Cost savings
The financial benefits are just as compelling. Prompt caching typically reduces costs by:
Cutting input token expenses by 50-90% for repeated interactions
Lowering computational resource requirements
Enabling more efficient usage of AI budgets
As noted by Anthropic, "By fully leveraging prompt caching within your prompt, you can reduce latency by >2x and costs up to 90%". This means you can build more sophisticated AI features without proportional cost increases.
Enhanced user experience
So, what does this mean for your end users? Well, faster response times create more natural-feeling conversations. Users perceive AI systems that respond quickly as more intelligent and helpful.
This improved experience translates to:
Higher engagement rates with AI features
Increased user satisfaction and retention
More complex AI interactions becoming practical
The strategic advantage is clear: prompt caching lets you handle large documents, complex instructions, or detailed examples without the performance penalties that would normally make these features impractical.
For product managers, this means you can now consider use cases that would have been too expensive or slow before—like analyzing entire books, processing large codebases, or building sophisticated educational tools that respond to student questions about lengthy course materials.
Practical code implementation and walkthrough
Let's walk through implementing prompt caching for a real product management use case: creating a product documentation assistant that can answer questions about large technical manuals without incurring repeated costs.
Environment Setup and Library Integration
Setting up your environment for prompt caching requires several foundational tools. The Anthropic API serves as your gateway to Claude’s capabilities, while specialized libraries handle the heavy lifting behind the scenes.
Let’s start with the essential components. The Anthropic library provides direct access to Claude models, allowing seamless communication with these advanced AI systems. Time-tracking functions help measure performance improvements, which is crucial for demonstrating the value of prompt caching.
import anthropic
import time
import requests
from bs4 import BeautifulSoupYour API key acts as your personal access credential. Store it securely using environment variables rather than hardcoding it into your application.
import os
import getpass
api_key = getpass.getpass("Enter your Anthropic API key: ")
os.environ['ANTHROPIC_API_KEY'] = api_key
from anthropic import Anthropic
client = Anthropic()When working with external content, web scraping tools become invaluable. BeautifulSoup transforms messy HTML into structured data you can easily process. Requests handles the HTTP communication, fetching content from across the web.
The model selection defines your interaction parameters. For prompt caching with Anthropic, newer models like Claude 3.5 Sonnet provide optimal performance.
MODEL_NAME = "claude-3-5-sonnet-20241022"
This foundation creates a robust pipeline for processing text through Claude while implementing efficient caching mechanisms. Each component plays a specific role in reducing latency and controlling costs.
Setting up the API
Here are the steps to setting up the API:
Go to the Anthropic Console at https://console.anthropic.com/
Login to the console.
You will be navigated to the dashboard.
Click on “Get API keys”.
Click on "Create Key" to generate an API

Now, select the workspace, I recommend default as the other one should be used for Claude computer use.

Set the name and click "Add" to generate the API
Save your API key | Keep a record of the key below. You wont be able to view it again
After this, you can execute this command client = Anthropic(), and it will automatically use the environment variable. If not, then it will prompt you to enter the API. Once you enter, it will authorize and you can use the Anthropic model.
Fetching Content for Analysis
The data retrieval component establishes our testing foundation. We use the Requests library to fetch web content and BeautifulSoup to transform raw HTML into usable text.
def fetch_article_content(url):
headers = {'User-Agent': 'Mozilla/5.0...'} # Browser identification
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
# Clean the content
for script in soup(["script", "style"]):
script.extract()
# Extract and format text
article_content = soup.get_text()
lines = (line.strip() for line in article_content.splitlines())
article_content = '\n'.join(chunk for chunk in chunks if chunk)
return article_contentWe also implement content truncation to manage large documents, preventing rate limits while preserving essential information for our caching experiments.
Implementation Details: Mechanism and Pseudo-code
The implementation of prompt caching with Anthropic's API involves several strategic components. Let's break down how the caching mechanism works in practice.
Core Caching Workflow
The fundamental workflow involves two main functions:
Non-cached API call: This establishes our baseline performance metrics
Cached API call: This demonstrates the efficiency gains from caching
Here's how we structure these functions:
def fetch_article_content(url):
headers = {'User-Agent': 'Mozilla/5.0...'} # Browser identification
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
# Clean the content
for script in soup(["script", "style"]):
script.extract()
# Extract and format text
article_content = soup.get_text()
lines = (line.strip() for line in article_content.splitlines())
article_content = '\n'.join(chunk for chunk in chunks if chunk)
return article_content
The key caching mechanism relies on the cache_control parameter. Setting this to "ephemeral" instructs Anthropic's system to cache this content. The special beta header "prompt-caching-2024-07-31" activates the caching feature.
Performance Comparison Approach
To demonstrate caching benefits, we:
Make an initial API call without caching benefits
Wait a short period (30 seconds in our example)
Make a second call that benefits from the cached content
Compare performance metrics between the two calls
The performance comparison typically shows:
Response time: Cached calls are often 1.5-4x faster
Token usage: Input tokens dramatically reduced for cached calls
Output consistency: Similar responses despite different processing paths
Error Handling and Fallbacks
The implementation includes several safeguards:
Time tracking to identify slow responses or timeouts
Exception handling to gracefully manage API failures
Conditional logic that proceeds only if earlier steps succeed
This structured approach ensures reliable performance measurement while providing fallback paths if any component fails. The entire process demonstrates how prompt caching creates significant efficiency improvements with minimal code changes.
Best practices, challenges, and future trends
Best practices for Prompt Caching
When adding prompt caching to your product, follow these key practices:
Structure prompts strategically. Put static content at the beginning. Add dynamic content at the end. This maximizes cache hits.
Monitor performance metrics. Track cache hit rates. Measure response time improvements. Calculate cost savings. Let these numbers guide optimization.
Craft consistent instructions. Use similar formatting across prompts. This helps the system identify matching patterns.
Balance cache size with performance. Too small means frequent misses. Too large wastes resources. Find your sweet spot.
Common challenges and solutions
Prompt caching isn't without hurdles. Here are the main ones:
Cache misses: Sometimes prompts aren't found in the cache. Fix this by reviewing prompt consistency. Adjust similarity thresholds to allow minor variations.
Cache invalidation: Caches expire after 5-10 minutes of inactivity. For critical applications, implement keep-alive pings. These refresh important cached prompts.
Storage limitations: Caches consume memory. Use TTL (Time-to-Live) values wisely. Prioritize which prompts deserve caching.
Privacy concerns: Cached content could contain sensitive data. Use encryption for sensitive information. Implement proper access controls.
Emerging trends
The future of prompt caching looks exciting:
Semantic caching: Beyond exact matching, systems will understand prompt meaning. Similar questions will hit the same cache.
Personalized caching strategies: Different users need different caching approaches. Systems will optimize based on usage patterns.
Distributed cache networks: Enterprise solutions will share caches across applications. This maximizes reuse and savings.
Cache analytics: Advanced tools will help identify caching opportunities. They'll recommend prompt structures for better performance.
The thing is, prompt caching is still evolving. What we see today is just the beginning. As models grow more powerful, effective caching becomes even more crucial. It's not just about saving money—it's about enabling entirely new product experiences that would otherwise be impossible.
Conclusion
Prompt caching represents a pivotal advancement in AI product development. By strategically implementing this technique, teams can dramatically improve performance metrics while reducing operational costs—turning theoretical AI capabilities into practical product features.
The implementation requires thoughtful, prompt structuring, with static content at the beginning and dynamic content at the end. While challenges like cache misses and storage limitations exist, they're manageable with proper monitoring and optimization strategies.
Looking ahead, trends like semantic caching and personalized caching strategies will further enhance these capabilities. For product teams, prompt caching isn't just a technical optimization—it's a strategic advantage that enables entirely new product experiences and use cases.
As AI becomes increasingly central to product development, techniques like prompt caching will separate high-performing products from the rest. Start implementing these approaches now to create AI features that are not just powerful but also responsive, cost-effective, and delightful to use.