
What is Scaling RL in LLMs?
A Technical Exploration of Reinforcement Learning Scaling in LLMs


Scaling RL in LLMs means expanding the reinforcement learning phase across three dimensions: model capacity, training data, and computing resources. Unlike traditional scaling, it focuses on teaching models to use existing capacity more effectively through algorithms like PPO, GRPO, and RLVR to improve reasoning abilities.
Another key aspect of scaling RL in train-time is that it enables and allows the LLM to conduct a long chain-of-thought (CoT) thinking. The long CoT makes use of the train-time compute and scales itself effectively. This, in turn, allows the model to iterate and refine on the thinking process before yielding the answer.
Scaling RL in train-time allow LLMs to spend more time producing longer CoT or reasoning steps by efficiently utilizing train-time compute
Why Reinforcement Learning Matters for LLMs
Reinforcement Learning teaches models to align with human preferences rather than just predict the next word. This approach transforms raw language capabilities into useful, helpful, and safe AI assistants.
Preference Alignment: RL helps models learn what humans actually want, not just what appears in training data.
Behavior Refinement: Models can improve specific skills like reasoning, truthfulness, and helpfulness through targeted rewards.
Safety Enhancement: Harmful or misleading outputs can be penalized, teaching the model to avoid unwanted behaviors.
Task Adaptation: RL enables models to excel at specific tasks like math or coding without needing massive specialized datasets.
Understanding RLHF Through InstructGPT
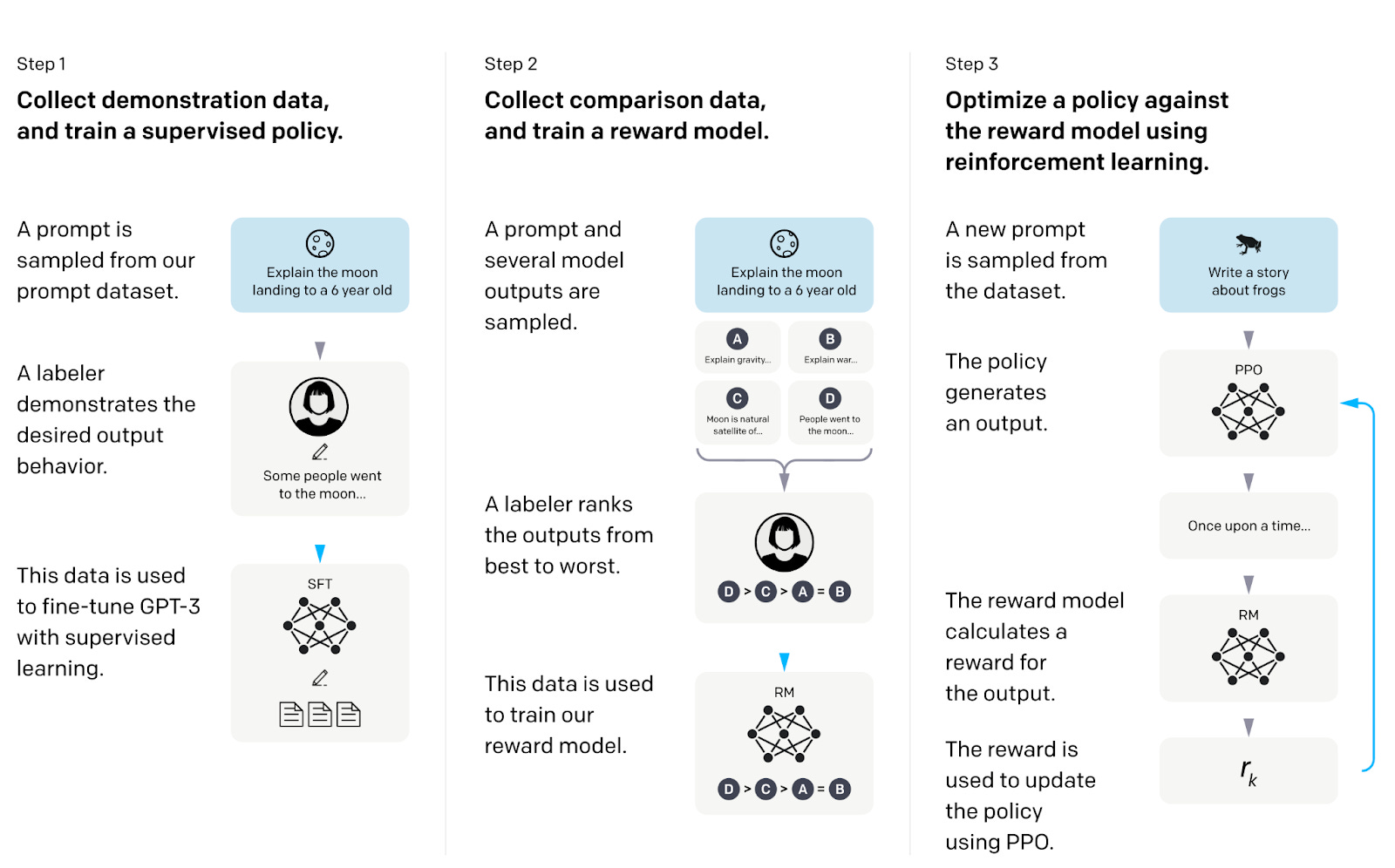
Reinforcement Learning from Human Feedback (RLHF) fundamentally changed how we train language models. OpenAI's InstructGPT demonstrates this approach through a three-stage process.
Assuming that the language model (LM) has been trained to predict the next work or token, the human labelers provide examples of desired outputs for specific prompts. The model undergoes supervised fine-tuning on this dataset. This is essentially where the model is trained on a question-answer pair. Similarly, multiple models are trained on the similar dataset and a vast number of responses from each model is collected.
Next, the human label scores each of the output and align it to their preference or “human preference”. This creates a dataset with LM output and score. This dataset is then used to train a reward model that predicts human preferences.
Finally, the LM is optimized using Proximal Policy Optimization (PPO) to maximize this reward function.
PPO is an algorithm that teaches AI models to improve through trial and error. It works like a coach who carefully adjusts a player’s strategy: the AI tries different approaches, gets feedback on what worked well, and then makes small, controlled changes to get better results next time. The "proximal" part means it doesn’t change too much at once, which keeps the learning process stable and prevents wild, unpredictable behavior.
This process transformed GPT-3 into a more helpful, harmless, and honest assistant. Despite having 100x fewer parameters, the 1.3B InstructGPT model produced outputs preferred over the 175B GPT-3 model.
The Core Components of RL in LLMs
Reinforcement learning for language models requires several key elements:
Policy Network: The language model itself, generating token sequences
Reward Function: Evaluates output quality based on human preferences
Value Function: Estimates expected future rewards from current state
Unlike traditional pre-training that only minimizes next-token prediction error, RL optimizes for longer-term objectives across entire sequences.
RL vs. Next-Token Prediction
Traditional language models train through next-token prediction, essentially memorizing token distributions from their training data. Reinforcement learning provides several advantages:

Policy-Network View of Language Models
When viewing language models through an RL lens, the decoder functions as a policy network πθ(a|s) where:
Actions (a) = tokens in vocabulary
States (s) = text history (previous tokens)
Policy = probability distribution over next tokens
This framework allows for sophisticated optimization beyond simple text prediction.
What “Scaling RL” Means in 2025
RL scaling applies the "bigger is better" principle to the RL phase of language model training. After a model completes its initial pre-training and supervised fine-tuning, RL scaling expands three critical dimensions:
Model capacity: Increasing the size of policy networks and reward models. Now keep in mind that the size of the policy network can be scaled-up after pre-training. There are techniques such as essembling multiple SFT models together.
Training data: Collecting more human feedback and preference examples
Computing resources: Dedicating more processing power to the RL training process.
Unlike traditional scaling that just makes models bigger, RL scaling focuses on teaching models to use their existing capacity more effectively. The goal is to help models:
Think through problems step-by-step
Generate safer and more helpful responses
Show their reasoning process clearly
When properly implemented, RL scaling produces models demonstrating significantly better reasoning abilities (2-3× improvement on complex tasks), more transparent thinking processes, and safer outputs that better align with human preferences.
A practical rule: When you double the model size, you typically need 2.2 times more feedback data and 1.8 times more training steps to maintain performance gains.
Axes of Scale
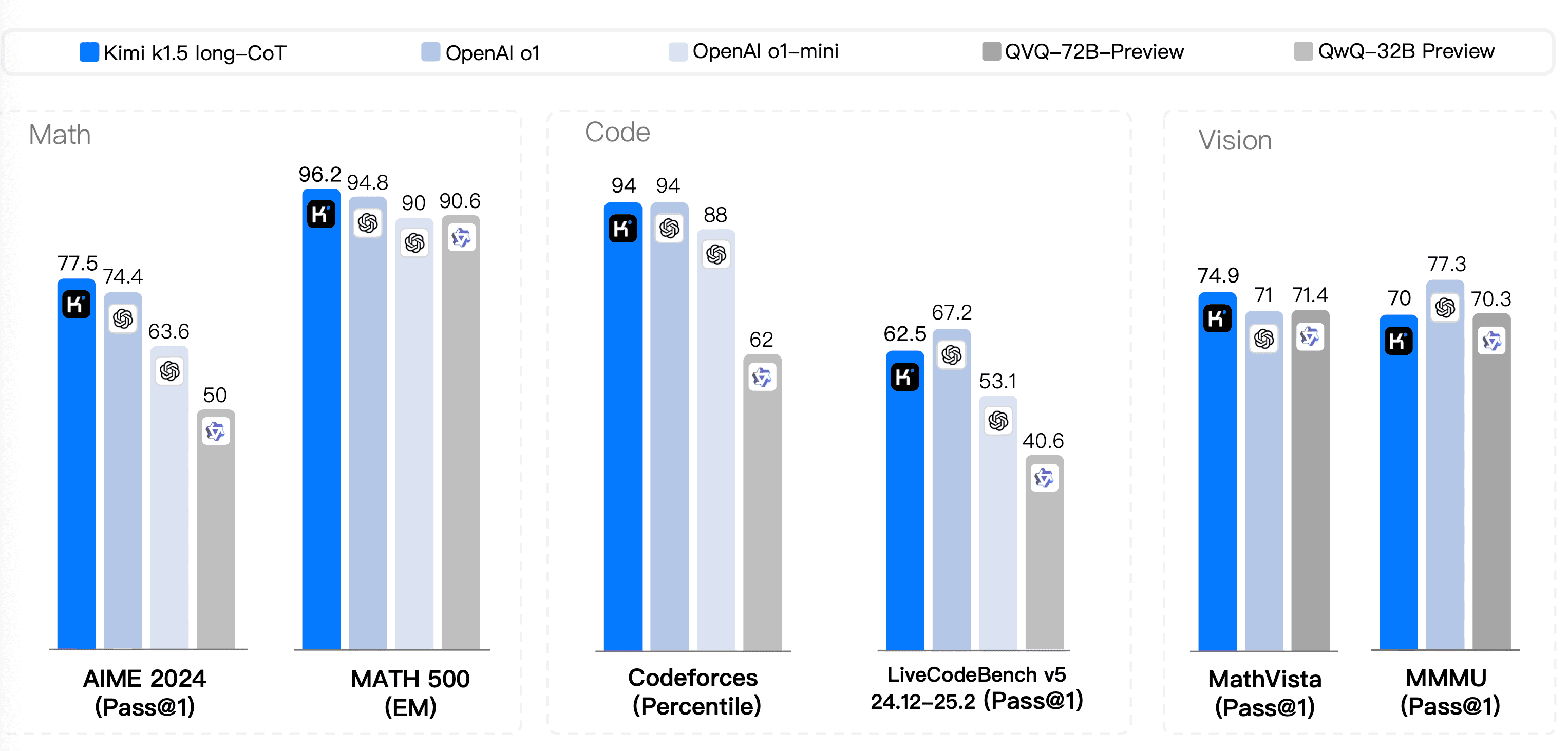
Recent Kimi K1.5 research identifies key scaling dimensions that impact performance:
Model Size: Larger parameter counts provide better capabilities but require more compute
Reward Model Size: Often smaller than the main model (Kimi uses 6B reward models)
Rollout Length: Longer token sequences enable complex reasoning (Kimi scales to 128K)
Batch Size: Larger batches improve training stability (Kimi uses 512 with 64 minibatches)
Preference Labels: More human judgments create better reward models
Gradient Update Budget: Number of training iterations (Kimi uses 256K episodes)
Why Rollouts Matter in RL Scaling
A rollout is like one complete conversation with the AI. It includes:
The starting prompt given to the model
Each token (word piece) the model generates one by one
Feedback scores on how good the response was
When and why the response ended
Rollouts are the building blocks of RL training. The model learns by generating many rollouts and receiving feedback on each one.
What Gets Recorded During Rollouts

How RL Makes Models Think Longer
RL doesn't make the AI think faster. Instead, it teaches the AI to use more computing budget wisely. This often leads to longer, more careful thinking:
Rewards for Good Thinking Steps
The LLM gets rewards for showing its work, not just the final answer
It learns that explaining things step-by-step earns more points
Longer CoT Can Be Better
Each extra word gives another chance to earn reward
The LLM learns to write more when that helps solve problems
Trying Multiple Approaches
The LLM might try solving a problem several different reasoning paths
It then picks the best solution or shows all its attempts
This helps it double-check its own work
Knowing When to Stop
The AI learns when more thinking won't help
It stops when the value of adding more words gets too small
This helps it be efficient with its thinking time
Infrastructure Patterns
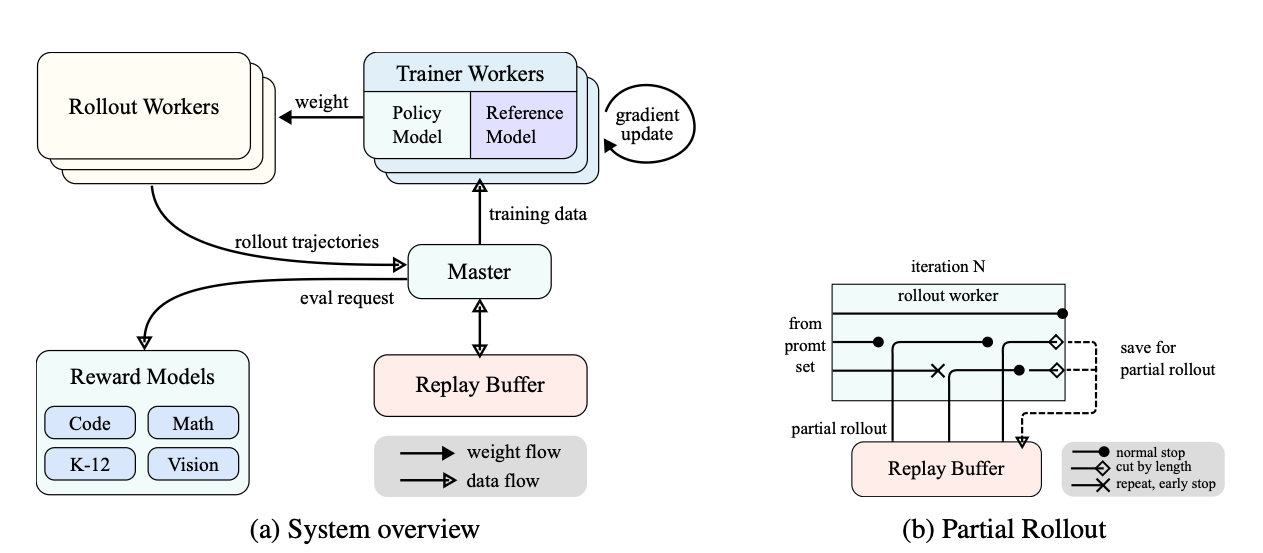
Modern RL training systems distribute work across thousands of GPUs:
Distributed Rollouts: Generate experiences in parallel across many machines
Partial Rollouts: Reuse previous trajectory chunks to improve efficiency
Experience Replay: Store and reuse valuable training examples
Mixed-Precision Training: Use lower precision for efficiency where possible
Synthetic Preference Generation: Smaller LLM models grade outputs to create preference pairs
For example, Kimi's infrastructure uses a hybrid deployment framework combining training and inference phases. Each phase handles different computational tasks:
Training phase runs Megatron for policy updates
Inference phase executes vLLM for efficient rollouts
A "checkpoint engine" manages weight sharing between phases
This approach reduces GPU idle time and enables efficient scaling to massive training volumes.
Core Algorithms Powering Scaled RL
There are three core algorithms that we will touch in this article:
PPO, which is the industry standard.
GRPO, which is a new method introduced by DeepSeek.
RLVR, which is a verification-based reward algorithm.
PPO: The Industry Standard
PPO remains the backbone of large-scale reinforcement learning for language models. OpenAI's o-series models continue to rely on PPO during their RL training stage. The algorithm uses a trust region approach that prevents excessive policy changes during updates.
The core PPO objective can be simplified as:
Where:
π_θ is the current policy
π_old is the previous policy
A is the advantage function
ε is a small constant (usually 0.2)
PPO works well at scale because it:
Handles large batch sizes efficiently
Provides stable updates even with noisy rewards
Integrates easily with KL-divergence penalties to prevent output degradation
GRPO: Efficiency Innovation
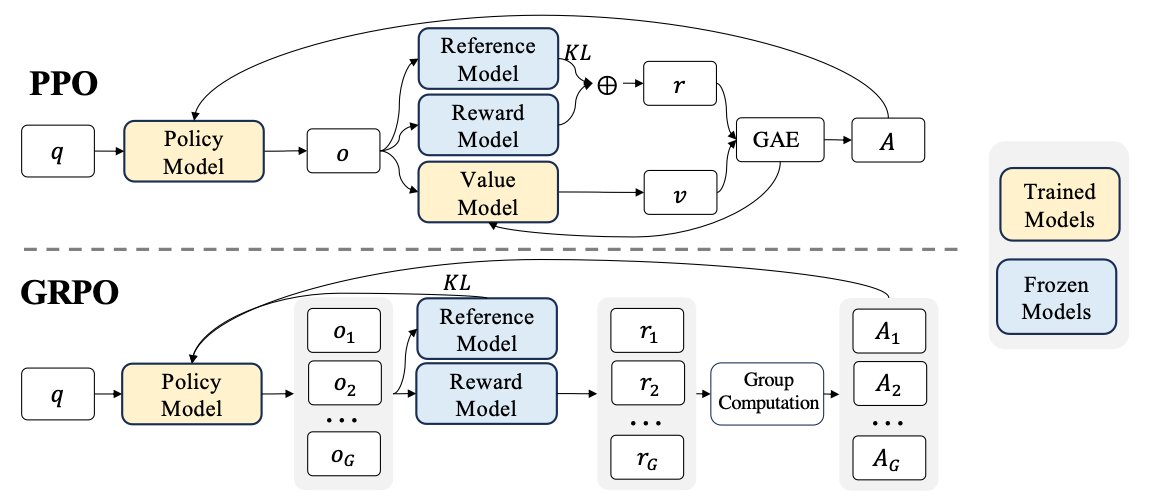
Group Relative Policy Optimization (GRPO) represents a significant advancement in RL efficiency. Introduced by DeepSeekMath, GRPO eliminates the need for a separate value network by using group statistics as baselines.

This approach has proven especially effective for mathematical reasoning tasks, where the algorithm helped DeepSeek achieve over 50% accuracy on competition-level math problems.
RLVR: Verification-Based Rewards
Reinforcement Learning with Verifiable Rewards (RLVR) tackles one of RL's fundamental challenges: reward hacking. Instead of using subjective human preferences, RLVR employs external verification mechanisms to validate outputs.
RLVR offers unique advantages for scaling:
Objectivity: Rewards based on verifiable criteria rather than subjective judgments
Automation: Reduces dependence on human feedback collection
Precision: Particularly valuable for domains with clear right/wrong answers
Early research suggests RLVR principles are being incorporated into the latest o3 alignment techniques. This approach helps models maintain truthfulness even as system scale increases.
The most effective implementations now combine elements from multiple algorithms, creating hybrid approaches tailored to specific domains like coding, mathematics, and factual reasoning.
End-to-End Training Workflow
Reinforcement learning fine-tuning for LLMs follows a structured workflow with several distinct phases. Each phase builds upon the previous one to create increasingly capable models.
1. Data Collection
The process begins with gathering high-quality data. For InstructGPT, this involved:
Human-written demonstrations of desired behaviors
Comparison data where humans ranked model outputs
Prompts collected from the API for diverse use cases
Quality matters more than quantity. A few thousand well-crafted examples often outperform millions of lower-quality samples.
2. Reward Model Training
The reward model (RM) learns to predict human preferences from the collected comparisons. Key considerations include:
Using separate models for reward and policy to prevent overfitting
Ensuring the RM generalizes to new examples through validation
Training with careful learning rate scheduling to avoid collapse
3. Rollout Generation
During this phase, the policy model generates responses that will be evaluated by the reward model. Best practices include:
Using nucleus sampling with temperature 0.7-1.0 for exploration
Forcing visible Chain-of-Thought (CoT) reasoning when appropriate
Generating multiple completions per prompt (64+ for GRPO)
4. Policy Optimization
This is where the actual RL training happens, with several algorithm options:

Fine-grained tips that improve results:
Token-level rewards provide denser learning signals than sequence-level rewards
KL-annealing gradually increases divergence from reference model
Curriculum learning progresses from simple to complex examples
5. Safety and Evaluation Loops
Regular evaluation ensures the model improves without unwanted behaviors:
Check performance on benchmark tasks
Verify safety guardrails remain effective
Test for new failure modes
Return to data collection if necessary
6. Optional Distillation
For deployment efficiency, the final model can be distilled:
Teacher model (full RL-trained) guides a smaller student
Knowledge transfers through supervised learning
Trading minimal performance for significant speed gains
This workflow represents the current best practice for creating models that align with human preferences while maintaining high capability.
Evidence & Case-Studies — Benchmarks, Cost-Efficiency, and Chain-of-Thought Gains
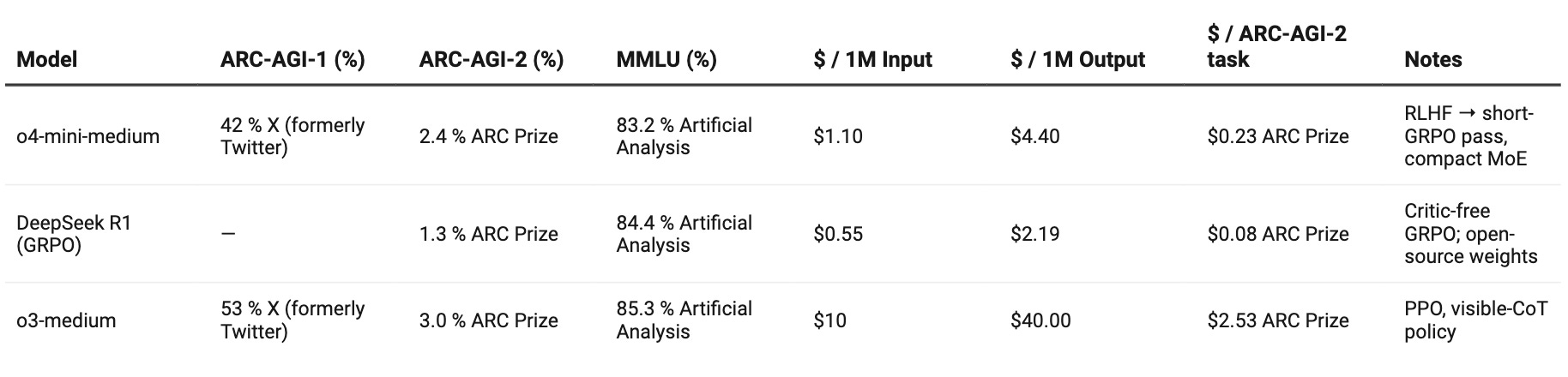
Key Take-aways:
Cost curves flatten faster than performance curves – o4-mini delivers 80 % of o3’s MMLU with ~10× cheaper tokens.
Scaled RL + visible CoT improves ARC-AGI-1 scores sharply—but raw “AGI-2” generalisation still needs verifier-based rewards.
GRPO shows strong efficiency: DeepSeek hits GPT-4-level MMLU for one-tenth the price of o3, albeit with lower ARC-AGI.
Chain-of-Thought–Centric RL Recipes
Today's most powerful language models don't just produce answers—they think through problems step by step. This approach, centered on Chain-of-Thought (CoT) reasoning, has become essential in reinforcement learning recipes.
OpenAI's Deliberative Approach
OpenAI's o-series models, including the recent o3 system, implement what could be called "deliberative alignment." This method follows a specific pattern:
The model is required to explicitly write out its reasoning process
This internal reasoning trace is evaluated for correctness and safety
Rewards are assigned based on both process and outcome quality
For deployment, the trace can be hidden or distilled away
The deliberative approach enables what François Chollet describes as "natural language program search and execution within token space." This allows o3 to achieve an impressive 75.7% score on the challenging ARC-AGI benchmark.
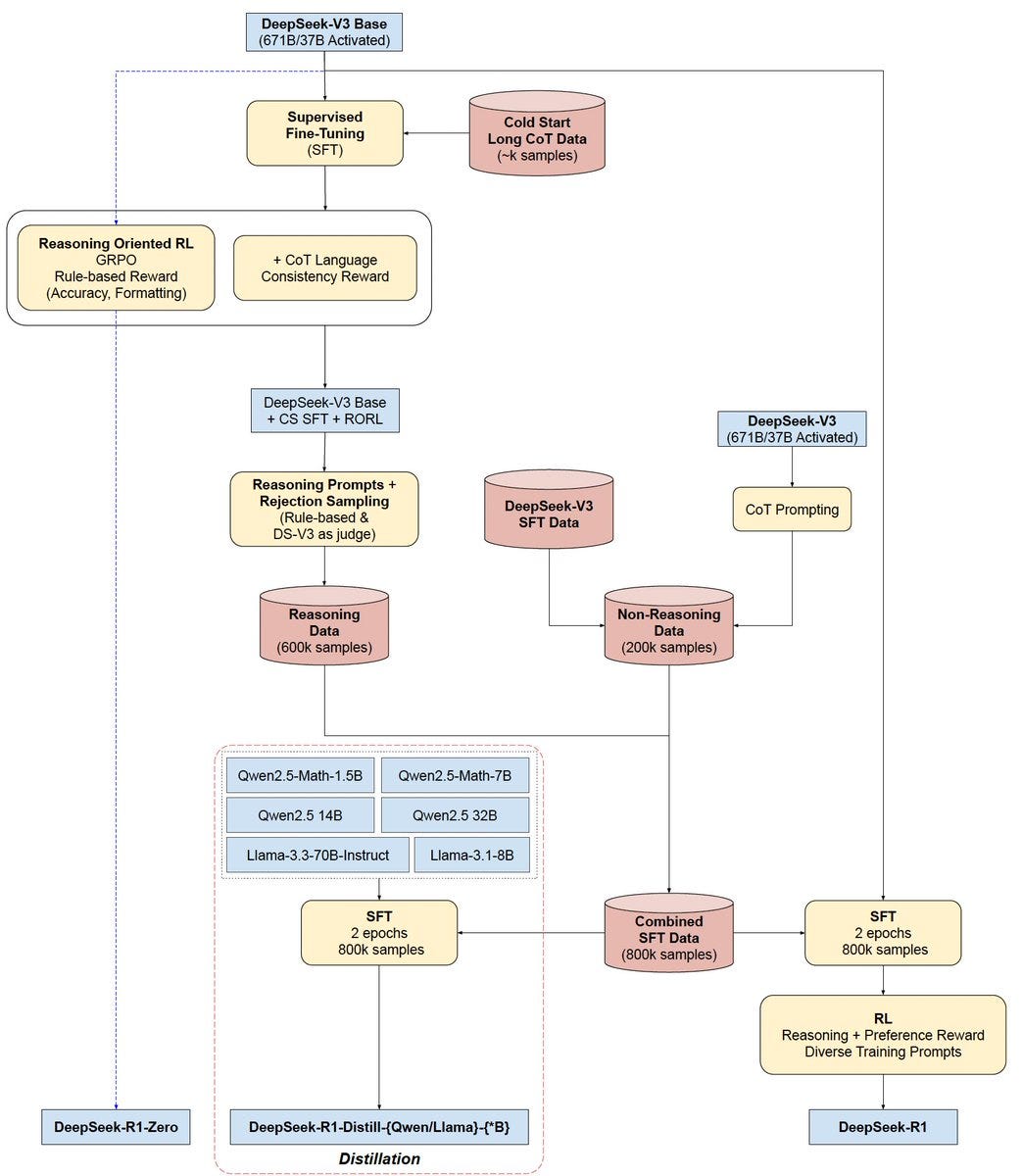
DeepSeek's Efficient Math Training
DeepSeek's R1 model takes a specialized approach to mathematical reasoning using:
Step-by-step math proofs with individual rewards at each reasoning stage
Group Relative Policy Optimization (GRPO) that eliminates the need for a separate value network
Relative normalization of rewards within sample groups
This efficiency-focused method reduces GPU training hours by approximately 40% while achieving state-of-the-art performance on competition-level math problems.
Future Direction: Verified Reasoning
The next frontier combines Reinforcement Learning with Verifiable Rewards (RLVR) and CoT verification. This approach would:
for each reasoning_step in chain_of_thought:
verify_logical_consistency(reasoning_step)
verify_factual_accuracy(reasoning_step)
if verification_failed:
apply_penalty()
breakThis verification process can catch deceptive or truncated reasoning before it receives any reward. The process supervision evaluates not just final answers but how the model arrives at them.
Key Benefits of CoT-Centric Training
Transparency: Reasoning becomes visible and auditable
Accuracy: Complex problems benefit from structured thinking
Alignment: Rewards target both process and outcome
Efficiency: Better training signal from intermediate steps
As models continue to scale, this focus on explicit reasoning will likely become even more central to reinforcement learning workflows.
Conclusion
Reinforcement learning scaling represents a significant shift in LLM training methodology. Rather than simply increasing model size, RL scaling focuses on optimizing how models use their existing capacity through enhanced training processes.
The key components of scaled RL include:
Core algorithms: PPO remains the industry standard, while newer approaches like GRPO offer memory efficiency and RLVR provides objective verification.
Multi-dimensional scaling: Effective RL requires balanced growth across model capacity, training data, and computing resources.
Chain-of-thought focus: Modern RL training emphasizes visible reasoning processes that improve both transparency and accuracy.
Infrastructure patterns: Distributed rollouts, experience replay, and hybrid deployment frameworks enable efficient scaling.
The results of properly implemented RL scaling are substantial: significantly better reasoning abilities, more transparent thinking processes, and outputs that better align with human preferences.
As the field advances, we can expect further innovations in verification-based rewards and process supervision that will enable even more capable, aligned models. The most successful implementations will continue to combine elements from multiple algorithms, creating tailored approaches for specific domains.