
Agent Replay Is A Product Surface, Not A Debugging Feature
Agent replay for production AI agents. The trace spec, who it serves, and why to build it in from day one.

TL;DR: Agent replay is a product surface, not a debugging feature. It is the primitive that decides whether agentic products can be triaged, explained, and audited once they hit production. ML monitoring was built for stateless predictions, and agents break every assumption in that model. This blog outlines the three constituencies, the capture spec to hand to engineering, and why designing it in-house beats retrofitting. Written for AI PMs and product leaders extending the workflow they inherited into agent territory.

There is a recurring pattern that I have been observing quite a lot lately in conversations with AI PMs and product leaders. The pattern reveals something uncomfortable about how we still build agentic products, and why the workflows AI PMs carried over from the last 2-3 years are quietly failing.
Let’s look at this example. A customer flags an agent decision from three days ago, so the PM opens the trace and starts scrolling. Forty tool calls pass by, every one of them reading as normal, and then they stop. There is no obvious break, no red line, no signal that says “the agent went sideways here.” Engineering ships a prompt patch anyway. Support sends a template reply. Nobody can verify the fix, because nobody can replay the run end-to-end.
That is not a bug in the model. It is a hole in the product workflow.
Classical ML monitoring was built for a simpler shape of software: one prediction, one label, one dashboard cell. Agents break every assumption in that sentence. They hold state, they call tools, and they branch on what the last tool returned. They also run long enough for the goal at step one to quietly become a different goal by step forty, without any single step looking wrong on its own.
Meaning, the workflow has to evolve. And the primitive that has to arrive first, before evals, before guardrails, before dashboards, is replay.
In The Long-Horizon AI Agents Ceiling Is A Product Problem, I argued that the planning ceiling is a product problem and offered five product moves to design around it. This blog picks up where that one left off. Every one of those moves quietly assumes something PMs rarely scope: the ability to reconstruct a run after the fact. This is something that I want to focus on eagerly. Take that primitive away, and the moves fall apart. Put it in place, and product leaders finally get the visibility to design under the ceiling instead of pretending it is not there.
Agent replay is that primitive. It is a product surface, not a debugging feature.
The Long-Horizon AI Agents Ceiling Is A Product Problem

TLDR: Long-horizon AI agents fail and fall short in measurable, predictable ways. And the failures are not closing fast enough to be a product strategy. This blog argues the planning ceiling is a product problem, not a model problem. It explains what the ceiling actually is and why “wait for the next model” is wrong. It also explains the five steps prod…
Why Agent Replay Is Different In Kind, Not Degree
Classical ML observability treats every prediction as a self-contained event: input goes in, output comes out, a label eventually arrives, and a dashboard groups predictions by cohort. The whole model rests on one assumption: nothing between input and output matters.
Agents violate the assumption immediately. A single run is a directed graph of decisions. Each node is a model or tool call, and each edge is a choice the agent made based on what it just saw. The output at step forty depends on every branch the agent picked, every tool response along the way, and every piece of state the agent carried forward or dropped.
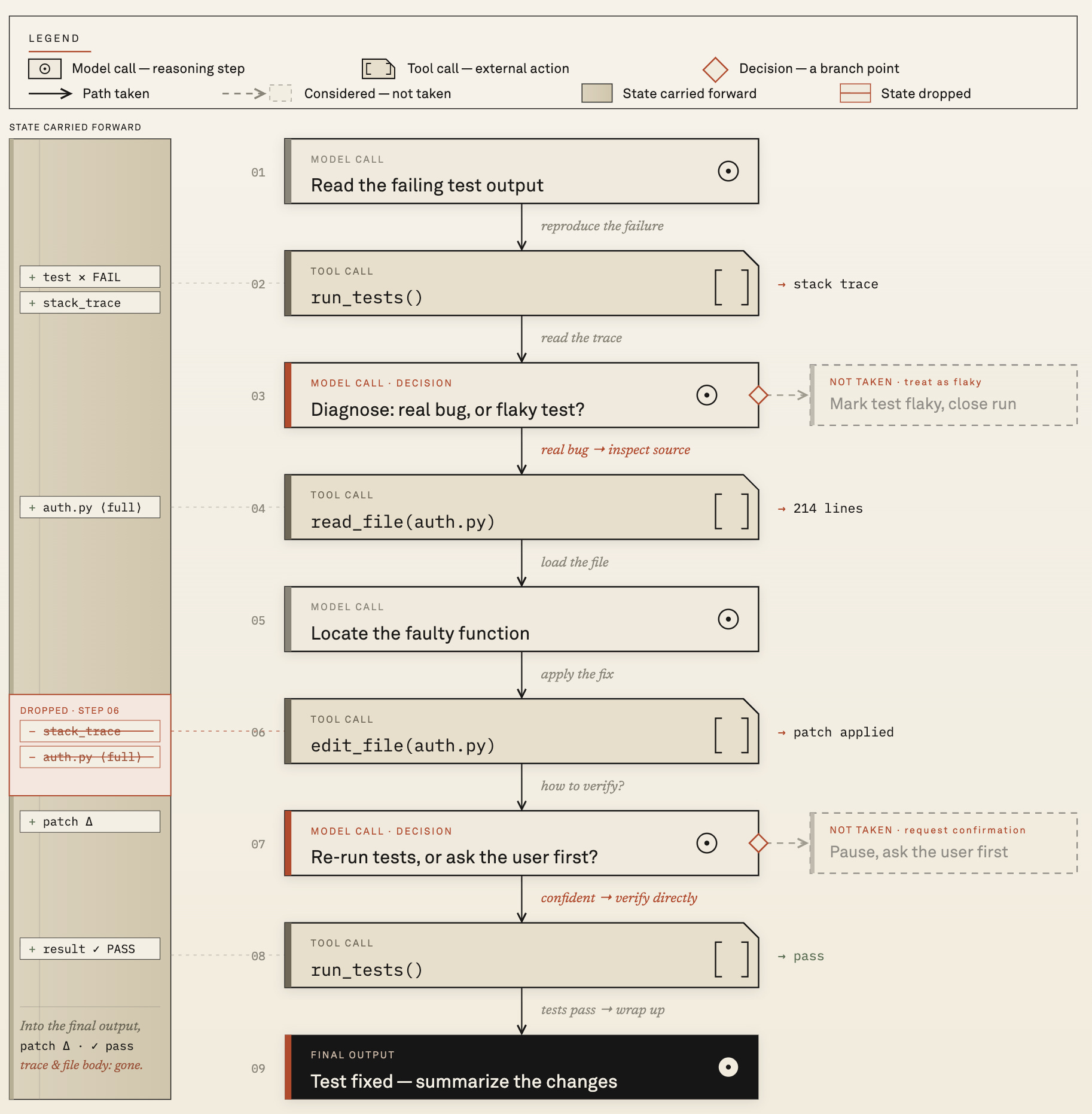
It has been observed that when an agent fails on a complex task, the fix is rarely a better prompt. It is a change to how state passes between steps, how tools are exposed to the model, or how the agent decides when to check in. Input-output views cannot see any of that. Replay can.
Replay for agents is not ML observability with more spans. It is a different data problem. The trace must preserve the causal chain step by step, including the paths the agent considered but did not take.
The Three Constituencies Replay Serves
Replay is not owned by a single team, and this is where the product decision lives. It serves three groups at once, and if any one of them cannot get what it needs from the trace, the product suffers in a specific way.
Engineering uses replay to triage. When something breaks, engineering needs the run itself: the prompts the model saw, the tool responses that came back, the intermediate state, and the decision points. Without that, they debug by proxy, reading logs and guessing.
Support uses replay to explain. A user files a complaint, and support has to answer, in plain language, why the agent did what it did. If replay is only engineer-readable, support falls back on template responses that the customer sees every time.
Compliance uses replay to audit. In regulated settings, “why did the agent make this decision” is not a nice-to-have question; it is a legal one. If the trace is incomplete or reconstructed rather than recorded, the audit fails.
Building replay for only one of these groups is the mistake I see most often. Engineering-only replay drowns support in JSON, and support-friendly replay is too shallow to debug. Neither satisfies compliance. The PM is the only role that sits at the intersection of all three, which is why replay is a product decision, not a devtools one.
The Capture Spec PMs Should Hand To Engineering
The capture spec is not “log everything,” which produces terabytes of noise nobody can navigate. It names the fields that the replay actually needs, in the order engineering can build them.
At every step of every agent run, I would ask for:
Prompt sent to the model: Captured in full, including system prompt, tool definitions, and message history.
Model output: Captured in full, including reasoning tokens if the model exposes them.
Tool call arguments: Recorded exactly as they were passed to each tool.
Tool responses: Recorded exactly as they returned, including errors and timeouts.
Intermediate state: What the agent carried into this step and modified inside it.
Branching decisions: The paths the agent could have taken but did not, when the harness knows them.
Timing and cost: Milliseconds per step and cumulative token cost.
Run configuration pointer: Agent version, model version, tool schema, and user session.
From the above, prompt and output, reconstruct what the model saw. Tool calls and responses reconstruct what the world looked like from the agent’s perspective. Intermediate state and branching decisions explain the choice. Timing and cost tell a stakeholder what the failure costs the business. The configuration pointer makes the run reproducible.
This spec is not just for debugging. It is the raw material for a self-improving agent: an agent whose harness ingests its own production traces, scores them, surfaces failure patterns, and ships targeted improvements back into the running system. That loop cannot begin without the eight fields above.
Designed In Beats Retrofitted
Every replay conversation hits a scoping question: build it in from day one, or bolt it on later? The bolt-on option looks cheaper because it defers the work. In my experience, it is not.
Retrofitting means walking every tool wrapper back and rebuilding the state that was already thrown away: variables garbage-collected, responses never persisted, and branches never recorded.
Most of that data is gone by the time anyone asks.
Designing replay means picking the trace schema before the first tool wrapper ships and instrumenting every call against it on first write. The cost lands in the sprint where the wrapper is being built anyway. It does not become a quarter-long retrofit six months later when a customer complaint forces the issue.
What Good Replay Actually Looks Like
A quick checklist to grade the replay your team already has. One point per item, honest about partial credit.
Full step reconstruction: Any past run pulls up with every model I/O, tool call, and response in order.
Branching view: Counterfactual paths the agent considered but did not take are visible, not just the one it picked.
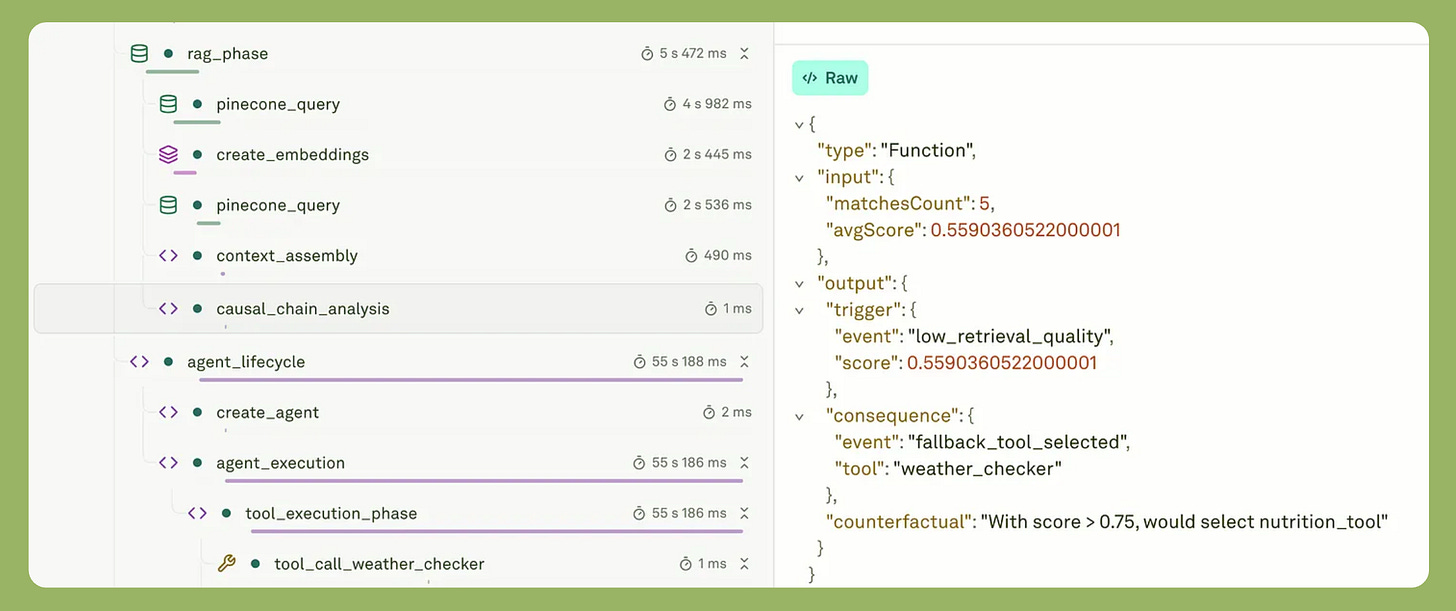
Screenshot of casual chain analysis in the Adaline dashboard. Diff between runs: Two runs of the same input can be compared side by side, with divergences highlighted.
Fork and rerun: A past run can be forked, one input or tool response changed, and rerun from that step forward.
Cross-team readability: A support agent and an engineer can open the same trace, and both understand what happened.
Retention that matches the audit window: Traces live long enough to satisfy compliance, not just this week’s on-call.
Six items. Score below four, and replay is not yet a product surface at your company; it is a dev tool some engineers use when they remember to look.
A team that gets to six does more than debug well. Production traces become the eval set. Every failure becomes a test case that the next model version has to pass. This is the loop that closes. It is what turns a shipped agent into a self-improving one, learning from every run instead of hoping the next model release does the work.
Observability vs Monitoring for Agentic AI Products

TLDR: Your agentic system cost $47 in 10 minutes, and monitoring didn’t warn you. This guide teaches causal observability for autonomous AI systems through three critical dimensions: causal chain tracing, decision provenance, and failure surface mapping
The Primitive Every Other Move Depends On
The previous blog argued five product moves that let AI PMs design under the planning ceiling. This blog names the primitive that makes those five moves work in production. Replay is not the whole workflow; it is the surface every other part of the workflow rests on.
That is the call worth making on any agent roadmap this quarter: pick the trace schema, design the capture spec, and serve all three constituencies from one recorded trace. What you get back is the ability to ship agents that fail sometimes and recover cleanly, instead of agents that fail silently and stay that way.