
Embeddings for AI Agents: What Product Leaders Must Know
Why context quality and not model quality is the defining factor in agentic product performance.

TLDR: This blog makes one argument: embeddings are not just a retrieval mechanism, they are the full context system of every agentic product. You will learn the four jobs that embeddings do in every agent and why each one is a product decision, not an engineering detail. You will also see how multi-agent systems use shared embeddings for sub-agent coordination. This blog is written for product managers, engineers, and builders who are actively building agentic products. If embedding quality is something you have fully delegated to engineers, this blog is where to start.

Philipp Schmid of Google DeepMind put it directly in his June 2025 piece. In “The New Skill in AI is Not Prompting, It’s Context Engineering”, he wrote: “Most agent failures are not model failures anymore, they are context failures.”
The model is capable, but what it receives is where production systems break down. Embeddings for AI agents are the mechanism that determines what an agent receives at every step. They control what gets retrieved, what gets remembered, and what gets passed forward.
For product leaders, embeddings are not an infrastructure decision to delegate. They are product decisions that shape quality and user experience at every layer. This blog is not a vector math tutorial. It is a product strategy argument — why the embedding layer matters, and why getting it wrong explains more failures than a weak model ever could.
What Are Embeddings for AI Agents?
When a language model processes text, it works with numbers, not words. Embeddings are the translation layer that enables this. An embedding model converts text, images, or code into a vector of numbers. Those numbers capture meaning — the relationships between concepts and the intent behind a phrase.
An animated workflow of how the Gemini-2 embedding model works by Google DeepMind.
Tomas Mikolov and colleagues at Google formalized this in their 2013 Word2Vec paper. The paper showed that vectors encode semantic relationships with surprising precision. The most-cited example is the vector for “king” minus “man” plus “woman” yields a vector close to “queen.”
Two sentences that mean the same thing land close together in vector space:
“Cancel my subscription.”
“I want to stop paying for this.”
Two sentences that share a word but mean different things land far apart:
“Bank account.”
“River bank.”
Embeddings encode meaning, not form. That is what makes them the right foundation for any system that needs to understand intent.
The vector produced lives in a vector database alongside millions of others. When the system needs relevant information, it converts the query into a vector and searches for the closest matches. This is called semantic search or vector similarity search.
What product teams build on top of that foundation determines whether agents hold up in production or quietly erode user trust.
How AI Agents Use Embeddings: Retrieval, Memory, Routing, and Personalization
A chat interface processes a message and returns a response.
An agent does much more. It decides what to do, executes steps, uses tools, and builds toward a goal across multiple turns. The difference is not just architectural. It is temporal. That temporal dimension is exactly why agents depend on embeddings in ways a chat interface never needed to.
Retrieval and grounding.
When an agent needs to complete a task, it needs relevant context. The agent converts the current query into a vector and searches the database for the closest chunks. It then pulls those chunks into its context window.
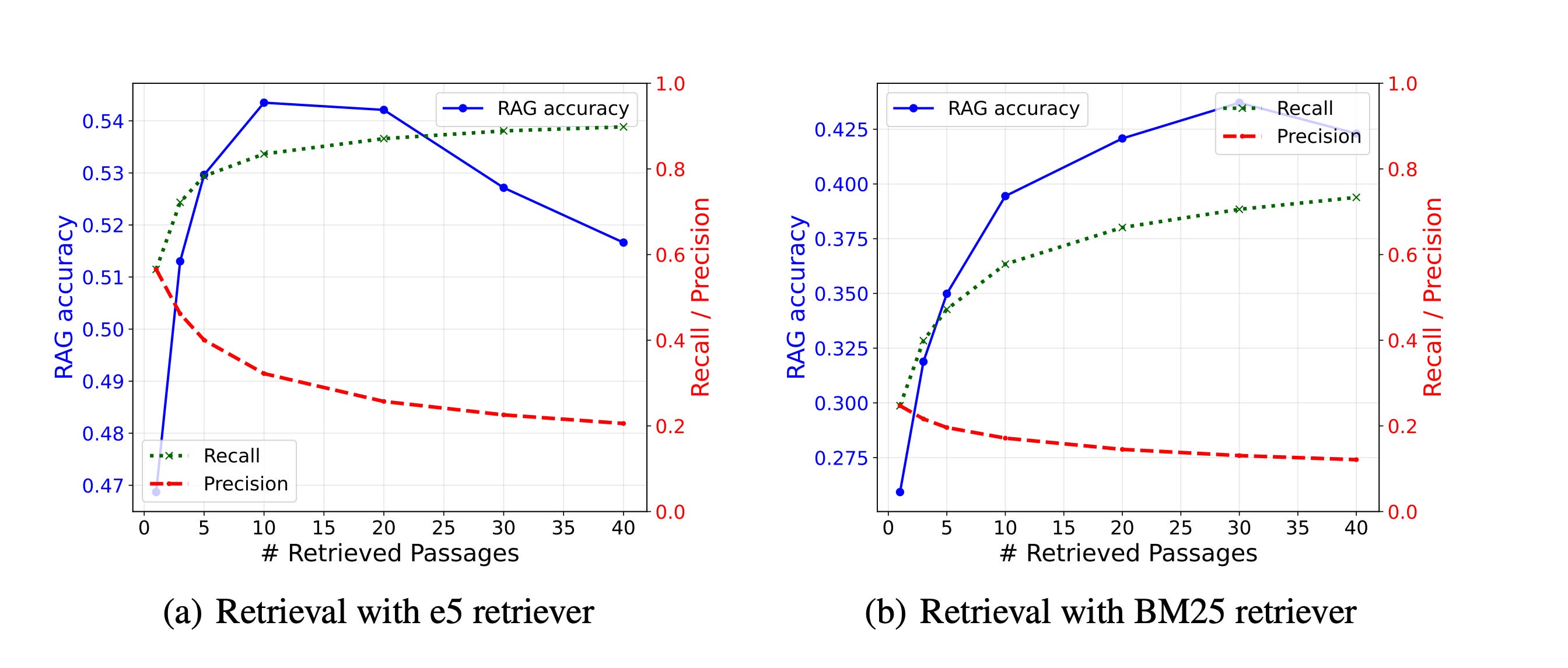
Research at ICLR 2025 found that irrelevant retrieved passages, i.e., “hard negatives,” degrade output quality even when recall is high.
A 2025 paper classifying errors across RAG systems confirmed the same: retrieval failures and generation failures compound each other. When the context layer fails, the model cannot compensate.
Memory.
Agents need to remember things across sessions, not just within one. Consider these examples:
A support agent should remember that a user prefers email over phone calls.
A research agent should remember open questions from the last session.
A sales agent should remember the deal context from six weeks ago.
Embeddings make this possible by encoding past interactions as vectors. The system retrieves them semantically when they are needed. Google’s Agent Development Kit (ADK), released in 2025, treats this as a first-class architectural requirement. It separates short-term session memory from long-term persistent memory. It then uses vector similarity search to retrieve only what is relevant, not inject an entire history into the context window.
Routing.
In multi-step workflows, agents decide what happens next. The choice might be:
Which tool to call?
Which knowledge base to query?
Which sub-agent to hand the task off to?
Semantic routing uses embeddings to match an intent to the right next step. Instead of brittle “if X then Y” rules, the routing layer uses embedding similarity to match queries to capabilities. This makes the system far more flexible as user language varies across thousands of real interactions.
Personalization.
Embeddings encode user behavior, preferences, and history in a form that is queryable. A recommendation agent that understands a user’s history as a vector finds semantically similar content without an explicit search term. The personalization is grounded in the meaning of past behavior, not keywords. That is what makes it feel relevant rather than mechanical.
How Multi-Agent Systems Use Shared Embeddings for Coordination
Multi-agent architectures are becoming the standard production pattern for complex agentic products. A customer success platform might coordinate across:
A billing agent.
A technical support agent.
A knowledge retrieval agent.
An escalation agent.
Each sub-agent is specialized. The coordination challenge sits between them. When the coordinator passes context to a sub-agent, it needs to be semantically accurate. The sub-agent needs the relevant pieces of conversation history, user state, and task context to do its job. A raw transcript dump does not cut it.
Research on the DyTopo routing system (February 2026) found a clear result. Reconstructing agent communication paths using embedding-based semantic matching at each reasoning step produced a 6.2% average improvement over fixed routing rules. That is a meaningful margin in workflows where failures accumulate across steps.
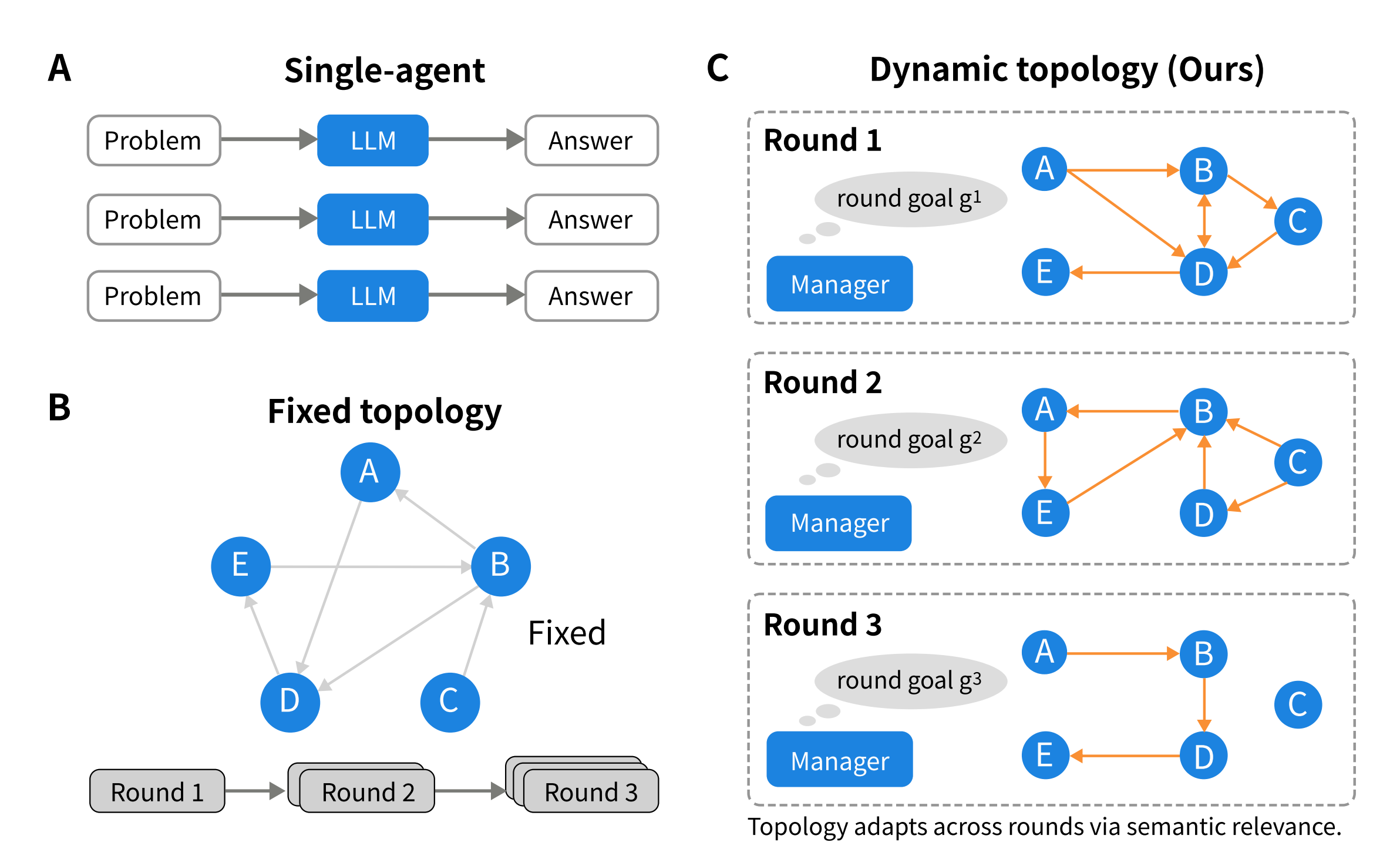
A shared-memory architecture relies on all agents accessing the same vector database. When one agent learns something important, like a user preference, a resolved constraint, or a task dependency, it writes that to shared memory as an embedding. When another agent needs it later, it retrieves it semantically.
The Federation of Agents framework demonstrated this at scale. Using Versioned Capability Vectors — agent profiles indexed and retrieved through semantic search — it achieved a 13× improvement over single-model baselines on complex multi-step reasoning tasks.
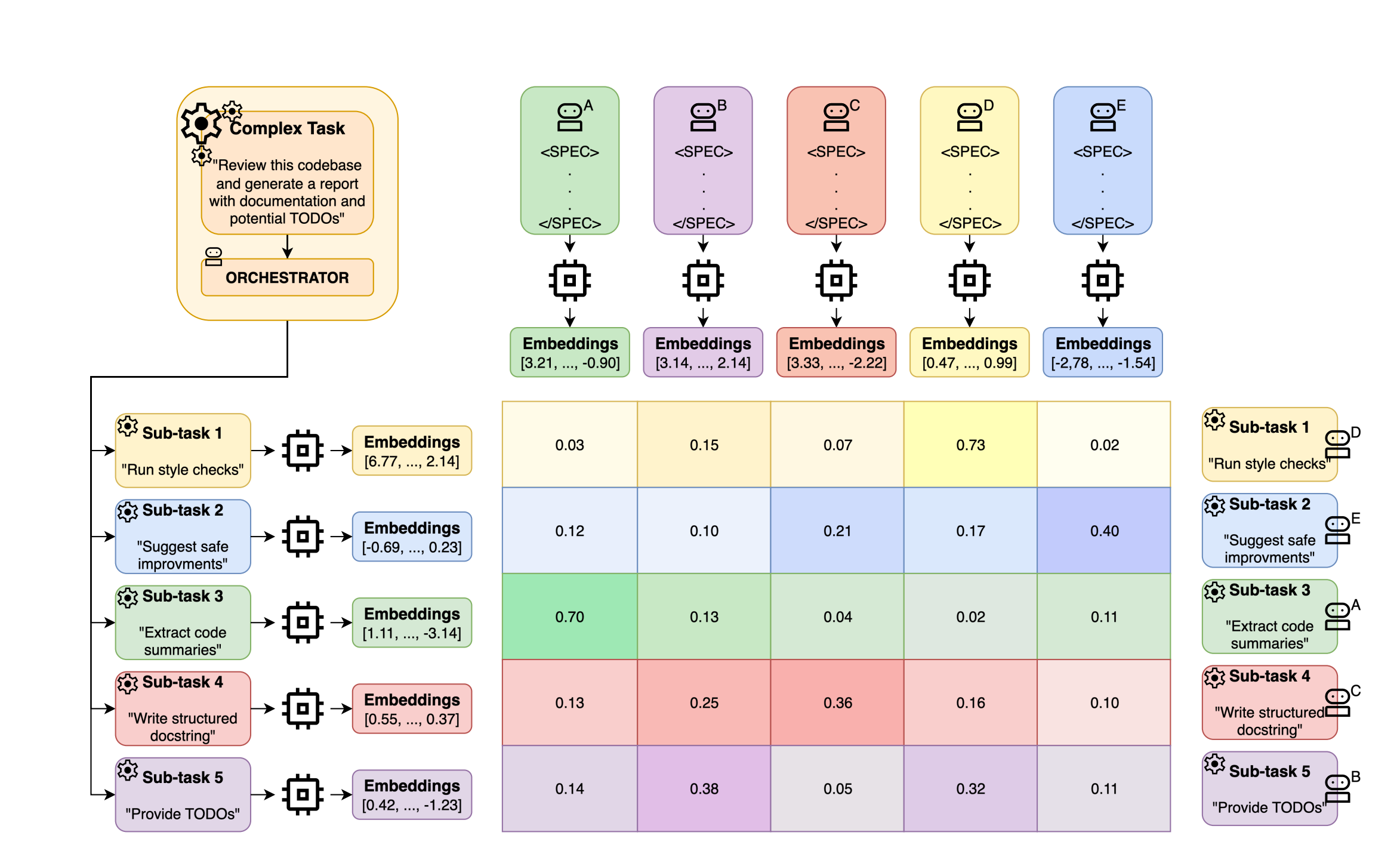
The pattern is consistent: sub-agent systems with a well-maintained shared vector store outperform systems built on static context injection or keyword routing — not because the models are stronger, but because the context system is better designed.
Why Embedding Quality Is a Product Decision, Not an Engineering One
Embedding quality is a product decision. The choices involved directly determine user experience:
Which embedding model do you use?
How do you chunk documents before embedding them?
How often do you refresh the vector store?
Which retrieval strategy do you apply?
A support agent who retrieves stale documentation frustrates users.
A research agent that misses the most relevant source because it was chunked poorly loses user trust.
A sales agent who forgets a deal detail because it was never stored loses the deal.
Product leaders who understand embeddings make better calls here.
They push for retrieval quality metrics to be tracked in production, not just during demos.
They ask whether the embedding model was fine-tuned on domain-specific content.
They question whether the chunking strategy preserves meaning at document boundaries.
They insist that memory architecture is designed before launch, not patched after users complain.
The most common mistake is treating embeddings as only “the RAG layer.” Retrieval-augmented generation is one use case. Embeddings also power:
Memory across sessions.
Semantic routing between agents.
Personalization based on behavioral history.
Anomaly detection when the agent outputs diverge from expected patterns.
A team that scopes embeddings as only a retrieval pipeline leaves memory, routing, and personalization undesigned. Teams that treat embeddings as the full memory and coordination layer build systems that scale with workflow complexity. The others spend months patching failures that could have been designed away from the start.
The Strategic Edge in the Agentic Era
Model quality is converging faster than most teams expected. As of early 2026, LMSYS Chatbot Arena — which aggregates nearly five million human preference votes across 296 models — shows frontier models clustered within a few Elo points of each other.
Zylos Research’s January 2026 benchmark analysis found leading models scoring above 88% on MMLU. A threshold that would have been a meaningful performance gap just twelve months earlier.
The differentiation will not come from which foundation model you pick. It will come from how well your system retrieves, remembers, and routes across the full lifecycle of a user interaction.
Embeddings are what make that possible. They connect memory to retrieval, retrieval to routing, routing to coordination, and coordination to user experience. They are not a backend detail. They are a design decision that compounds across every feature you ship.
Product leaders who understand this layer will catch failures before users do. The ones who delegate it entirely will keep shipping agents that perform in demos and fall apart in production. The model is not the bottleneck. The context system is. Build accordingly.
Frequently Asked Questions
What are embeddings in AI agents?
Embeddings are numerical vector representations of text, code, or data that encode semantic meaning. In AI agents, they power four core functions: retrieval from knowledge bases, memory across sessions, semantic routing between tools and sub-agents, and personalization from user history. Every time an agent finds relevant context or remembers past information, it relies on embeddings.
Are embeddings only used for RAG in AI agents?
No. Retrieval-augmented generation is one use case among many. Embeddings also power memory across sessions, semantic routing between agents and tools, personalization based on user behavioral history, and anomaly detection. Every time an agentic system finds something relevant, recognizes a similar pattern, or organizes data by meaning, it is using the same embedding infrastructure.
How do embeddings improve AI agent memory?
Embeddings encode past interactions as vectors stored in a vector database. When the agent needs relevant context from a prior session, it converts the current query into a vector and retrieves the closest semantic matches. Google’s Agent Development Kit (ADK) treats this as a first-class architectural requirement, separating short-term session memory from long-term persistent memory retrieved via vector similarity search.
What is semantic routing in multi-agent systems?
Semantic routing uses embedding similarity to match an incoming query or task to the most appropriate agent, tool, or knowledge base. Unlike rule-based routing, it generalizes across varied user language. Research on the DyTopo system found embedding-based semantic routing produced a 6.2% improvement over fixed routing rules across code generation and reasoning tasks.
Why should product leaders care about embeddings for AI agents?
Embedding quality is a product decision, not just an engineering one. The choice of embedding model, chunking strategy, vector store refresh schedule, and retrieval approach all directly determine user experience. Product leaders who understand these choices identify context failures before users encounter them — and ship agents that hold up beyond the demo.