
From Prompts to Agents: How Product Teams Should Think About Product Development
Discussing the three stages of AI product development.


Earlier today, I came across an illustration on X (formerly Twitter) that perfectly captured the evolution of AI products: the three ways to build with AI. It was shared by Damian Player, and it immediately caught my attention.
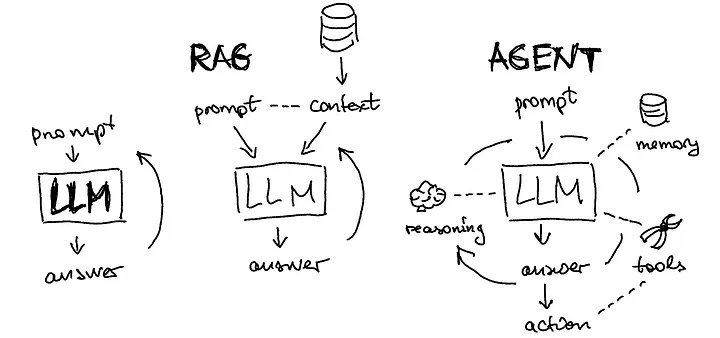
The sketch outlined a simple yet powerful progression of AI products. Something that every product builder should understand.
It inspired me to break down how AI products evolve over time. Essentially, from the first stage of simple prompt-response systems to retrieval-augmented models, and finally to autonomous agents. Each stage brings new capabilities and design decisions. In this blog, I’ll explore how product teams can navigate these stages thoughtfully and build AI products that are not just functional, but intelligent and reliable.
Stage 1: Prompt-Only Systems
When LLM was introduced as a product via ChatGPT, it was a basic prompt-response model. It wasn’t a new idea, but the fact that it became revolutionary was because it could do multiple tasks. It can write code, articles, summarize, provide meaningful feedback on a piece of content, etc. But it wasn’t perfect. But it opened the door to many possibilities and, more importantly, building products.
GPT-3 was a result of the scaling law. Simply put, the bigger the model, the better it performs. Moreover, training a large model promotes transfer of learning from one domain to another. But GPT-3 was not an instruct-tuned model. Meaning, it cannot follow the instructions or prompts that the user gives. It was more of a text completion model.
When the OpenAI team launched the GPT-3 API [in 2020] in their playground environment, users began treating it as a conversational interface. Even though the model underlying the experience wasn’t fully designed as a chat system, users used it like a conversational interface. In 2022, a tuned version of GPT-3 (GPT-3.5) emerged with instruction-following ability and human-alignment, which then powered ChatGPT.
However, the first generation of chat-based LLMs had a serious issue: hallucinations. These models would “make up facts,” generate persuasive yet incorrect statements, or lose coherence when contexts grew complex. But for product builders and developers, this stage (Stage 1: Prompt-Only) illustrates a key lesson: the prompt is not just the input, it’s an interface. How you craft the prompt determines much of the output quality, the user experience, and the boundaries of trust.
Prompt engineering mattered. Thoughtful prompts improved accuracy, guided the model’s tone, and reduced risk of unwanted behaviour. In short, for product teams building at this stage, the emphasis is on:
Defining clear user intent.
Managing model output and expectations, i.e., alignment.
Iterating prompt designs as product artifacts.

Stage 1 is about laying the foundation: you experiment, evaluate, iterate, and build trust. Without this base, moving into RAG or agentic systems becomes fragile.
Stage 2: RAG
Retrieval-Augmented Generation, or RAG, is where the LLM begins to grow up. In this stage, the model doesn’t rely only on its internal weights to answer a question. It pulls relevant information from external sources and uses that to create a context. The context is then fed to the LLM to shape a better response.
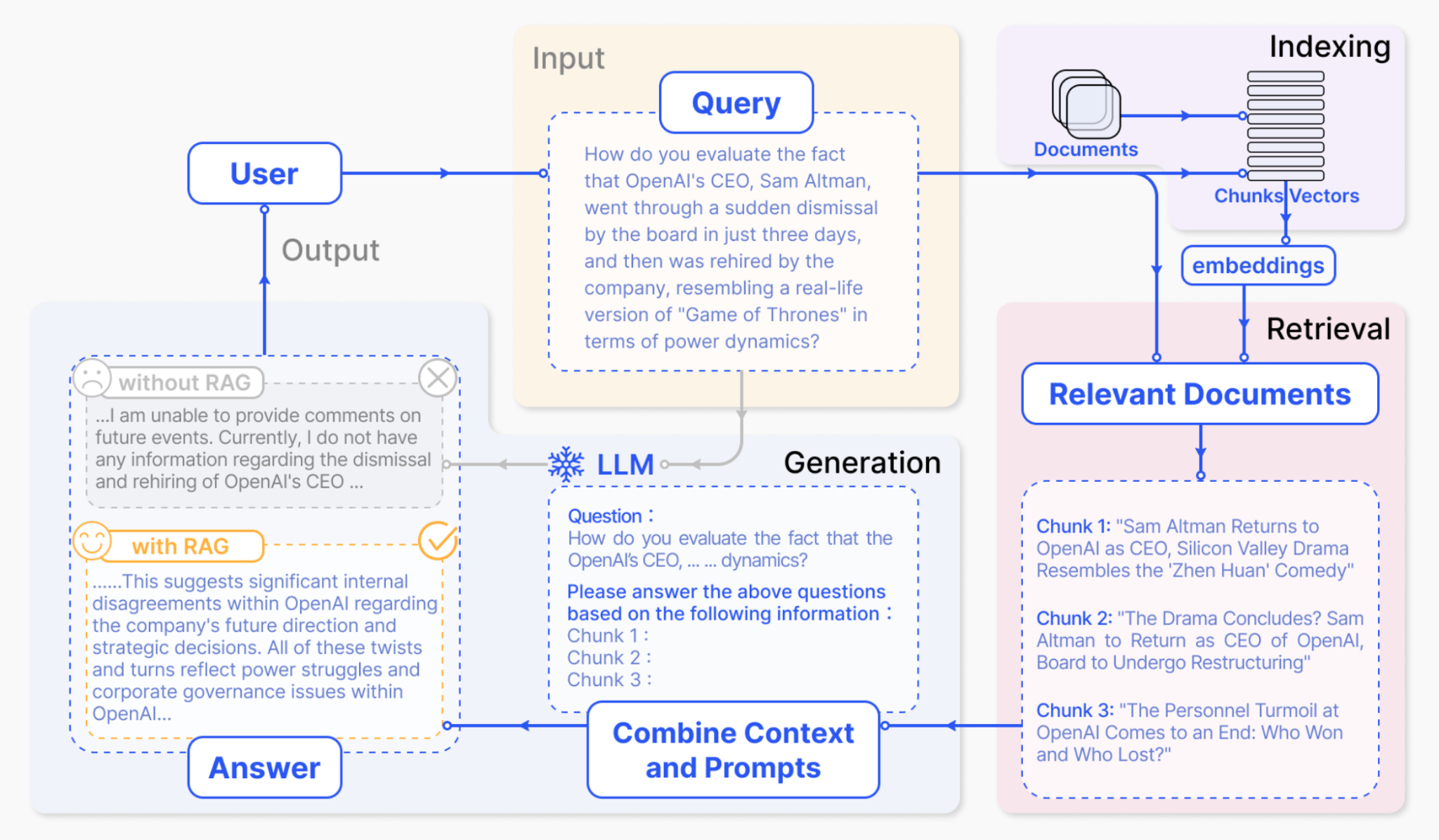
You find that LLMs aren’t trained on RAG. But the whole mechanism is incorporated into the LLM. A basic LLM only remembers what it was trained on. LLM here can be considered a mathematical model that captures the overall representation of the data. A RAG system, on the other hand, can access a live knowledge base—documents, APIs, or databases—and retrieve facts in real time. This single step transforms the model from an oracle to a reliable assistant.
Here’s how it works in practice:
The user sends a prompt such as “Summarize our Q3 performance.”
The system searches the company’s internal data store for relevant documents.
Those documents are embedded as context and combined with the prompt.
The LLM then generates an answer that reflects both its reasoning and the new information.
That was a simple intuition. But a complex version looks very different. Consider a research-writing application designed around multiple LLMs working in sequence.
User Input: The user submits a research topic or query through a prompt template.
Query Generation (LLM 1 – GPT-5 Mini): The first model expands the user prompt into several optimized search queries.
Information Retrieval (LLM 2 – Perplexity Sonar Pro): A search-specialized model identifies relevant and credible sources across the web.
Data Collection: The selected resources are fetched automatically via APIs.
Vectorization: Retrieved documents are converted into embeddings, such as OpenAI embeddings, and stored in a vector database, like Pinecone, for efficient retrieval and indexing.
Outline Creation (LLM 3 – Claude Sonnet 4.5): Another model organizes the gathered knowledge into a structured outline.
Instruction Generation (LLM 4 – Claude Sonnet 4.5): A fourth model produces detailed writing instructions for each section of the outline.
Content Drafting (LLM 5 – Grok 4): The fifth model writes each section using those instructions and retrieves supporting data from the vector store.
Evaluation & Refinement (LLM 6 – Claude Sonnet 4.5): Finally, an evaluation model reviews coherence, factual accuracy, and tone, then polishes the final draft.
Now, it is vital to understand that each LLM will have its own prompt template, and context from the previous step will be augmented into the next step. This fusion of retrieval and generation solves a critical product problem: hallucinations. When teams ground the model’s responses in real data, factual accuracy improves and user trust rises. It also reduces the need for frequent fine-tuning, saving time and cost. In this case, prompt templates and RAG tools align the LLM to the user intent while keeping the entire process grounded in truth.
RAG-based software or products are extremely good for research, as you can retrieve a lot of information. Similarly, if you want to learn something new or even analyze a result, RAG-based systems are extremely capable. But RAG is not a full agent. It doesn’t reason over long sequences or take independent action. Its intelligence is conditional, limited to the quality and scope of the retrieved context.
For product teams, RAG represents a maturity milestone. It’s the stage where LLM-powered applications stopped being clever demos or MVPs and started becoming dependable tools. Implementing RAG requires good data pipelines, vector databases, and robust prompt management.
Once that foundation is in place, the next evolution becomes natural. The model learns not just to recall, but to reason, decide, and act. That’s where agents begin.
Stage 3: Agentic System
Agentic systems mark the most significant shift in the overall development of LLM-based applications. At this stage, the model ceases to be only a responder. It now starts to behave as an active participant in a workflow. These agentic systems can reason, plan, and take actions toward a defined goal.
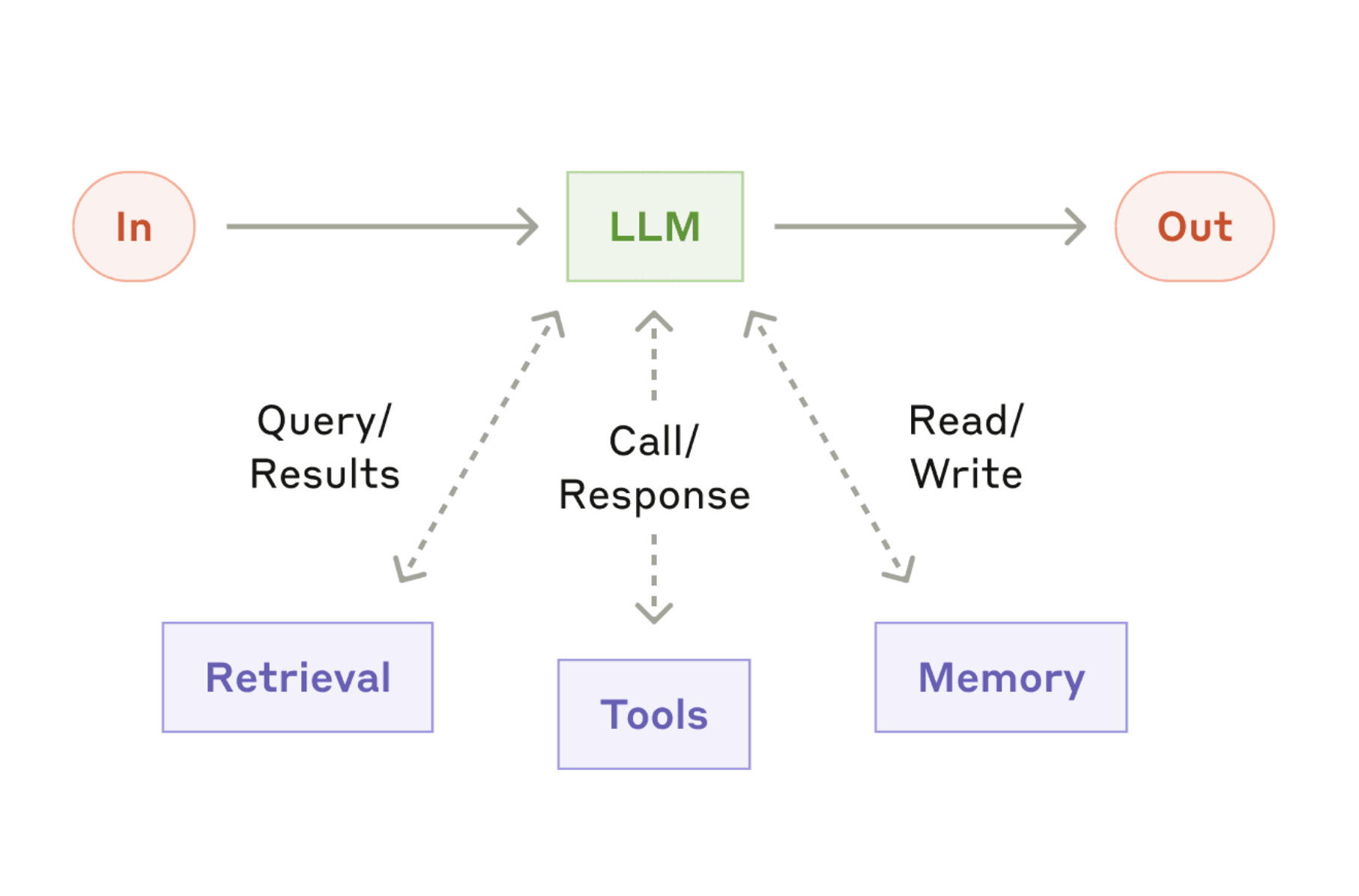
Unlike RAG, which simply retrieves context, an agent can decide what context it needs. It can also decide which tools to use and when to stop. It’s not just reacting to prompts or instructions; it’s coordinating steps to achieve outcomes.
All of these capabilities lie in the prompt and the way the prompt assembles the context. Meaning, a clear and well-defined prompt can make the necessary tool call in the right order. It can also align the model to accept responses from the tool that doesn’t clutter its memory.
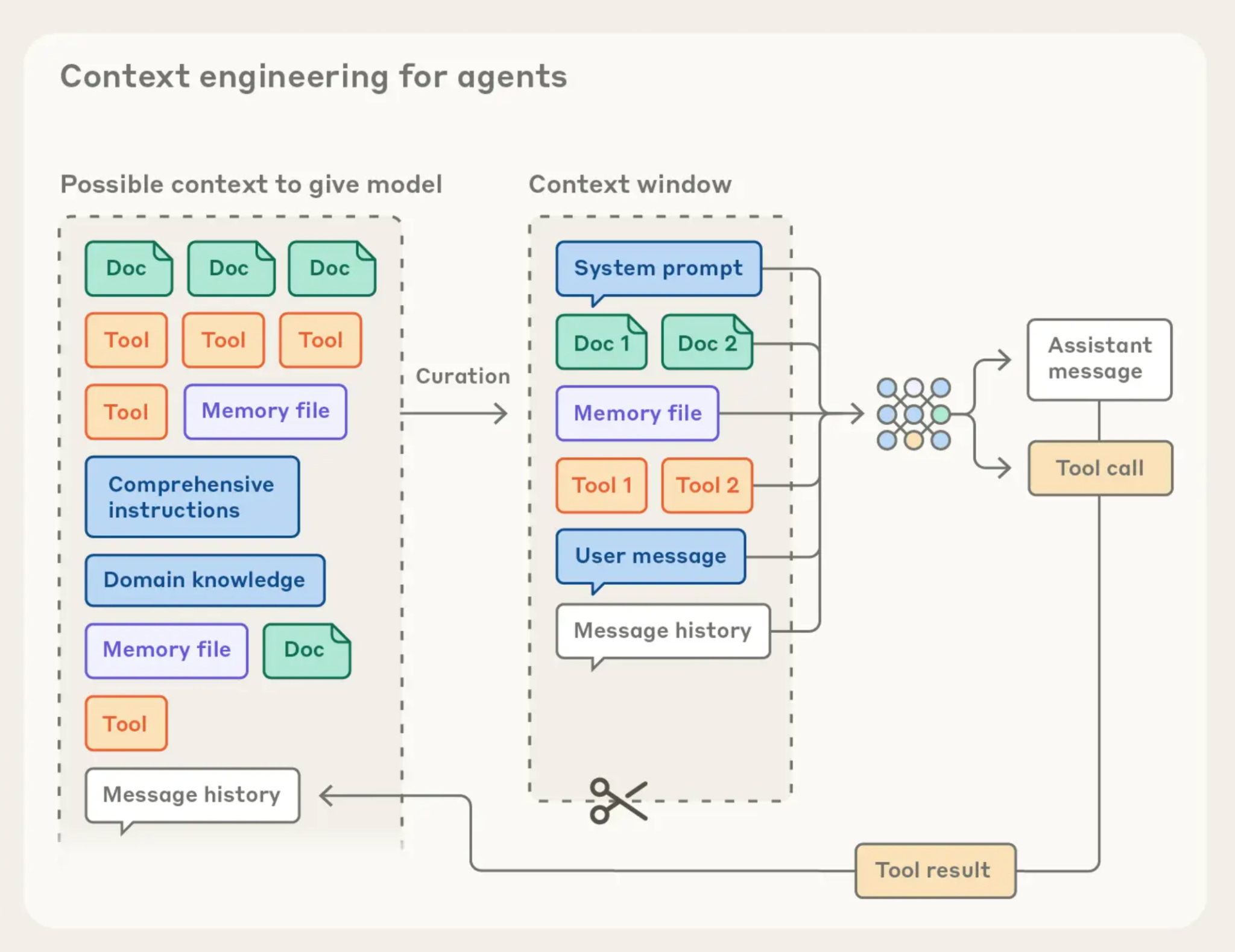
A modern agentic system usually integrates four key capabilities:
Memory: It stores and recalls previous interactions, preserving continuity across tasks.
Tool use: It connects with APIs, databases, or services to perform real actions.
Reasoning: It breaks problems into smaller goals and sequences steps logically.
Autonomy: It monitors its progress and adapts plans without continuous user input.
Now, if we transform the RAG-based research-writing application into an agentic we would just need one LLM. That one LLM, let’s Claude Sonnet 4.5, can do all the processes, provided the tools are properly connected. Essentially, this LLM can now take the user query and go to the internet, find relevant content or resources, and draft a research article.
Other examples would be a support agent can read customer emails, check internal systems, suggest solutions, and even draft replies. A coding agent can write, test, and debug code across sessions. Each step involves goal decomposition, reasoning, and feedback loops between perception and action.
For product teams, this stage changes how AI features are designed and shipped. In all of this, prompt engineering and defining tool-calling functions are important skills. If these two are not implemented properly, the product can break. These two skills have shifted products from static artifacts to dynamic organisms. Meaning, with agentic capabilities and user feedback, products continuously evolve. New features can be essentially shipped on a prompt level now.
Evaluation has also evolved. You no longer measure only accuracy. You measure reliability, latency, cost, structure of the response, and success rate of end-to-end tasks.
Building an agent requires orchestration layers, sandboxed execution, and observability. It demands thoughtful design of memory, safety checks, and reasoning boundaries. These are engineering challenges as much as product challenges.
When done well, agentic systems unlock new categories of software—adaptive, continuous, and goal-driven. That is the moment your AI becomes an operator, not just an assistant.
Mapping to Product Teams
For product teams and builders, understanding how LLM evolved is more than a technical framework. It allows you to decide where to invest time, data, and engineering effort. Each stage—prompt, RAG, and agent—demands a different kind of thinking about design, infrastructure, and measurement.
At the Prompt stage, teams focus on clarity and iteration. It means start simple; complexity comes later. This is also the stage where you define vision of the product. The goal is to find reliable prompt patterns that consistently produce high-quality responses. You’re testing ideas fast, learning what the model understands, and shaping tone, style, and reasoning behavior.
At the RAG stage, teams shift from surface quality to factual reliability. The product challenge becomes integration. You need pipelines that retrieve accurate data, store embeddings efficiently, and feed context into the model seamlessly.
At the Agent stage, the challenge expands to orchestration. Teams now design systems that reason, act, and learn across time. The focus moves from feature-level success to workflow-level reliability. You need observability for agent decisions, sandboxing for tool calls, and governance to control unintended actions.
Here’s how product maturity can map across these stages:
Prompt apps: Ideal for prototypes and early user testing.
RAG systems: Suitable for scaling accuracy in production environments.
Agents: Designed for automation, long-horizon reasoning, and real-world integration.
Progressing through these stages is not just about model sophistication. It reflects how your product evolves as an organism. Meaning, how teams align product vision with user feedback, UX, safety, and engineering under a single learning loop.