
Why LLM Evals Are Every Product Manager's Secret Weapon
Product builders who poccesses user-centric mindset will write better evals and ship products confidently.


A couple of weeks back, I wrote about how products are evolving from artifact to organisms. Meaning, how the products improve themselves each time we interact with the AI agents. Essentially, the idea was to portray how our [or users’] interaction with AI creates an iterative feedback loop which leads to product evolution.

But in this evolution, there are two major factors involved:
Product Managers
LLM Evals
These two are pivotal characters in the entire product lifecycle. The former’s domain expertise allows to hone AI via prompts and creating test cases to evaluate AI on large datasets.
In this blog, I will share why Evals are crucial in developing products that are aligned with users and what the role of AI PMs is.
Why Product Managers Hold the Key to AI Product Success

Why do so many AI projects stall before launch?
Recent 2025 reports show that most pilot apps never graduate to production. In 2024, Gartner wrote that only 48% make it that far, and in 2025, at least 30% of gen-AI projects are abandoned after proof-of-concept. MIT even reports 95% pilot failure rates. Causes include weak evaluation, governance, and integration.
What role should a product manager play?
A product manager acts as the principal domain expert who aligns technical capability with user value. In practice, that means defining AI evaluation goals, selecting metrics, and tying results to decisions.
At Anthropic, deployment is gated by ASL-3 standards that require explicit capability and safety evaluations before release.
OpenAI’s open-source Evals shows how PMs can codify task-level tests and regression suites for LLM applications. The PM owns that flow from hypothesis to metric to ship or stop.
Why trust this approach now?
Google DeepMind details safety and capability evaluations in its Frontier Safety work and cybersecurity threat testing.
Anthropic activated ASL-3 safeguards when launching Claude Opus 4, demonstrating evaluation-driven release gates at scale.
Companies that institutionalize LLM-as-a-judge and red-team evals reduce hallucinations and tighten ROI loops by turning subjective quality into measurable scores. Meaning, the responses are user-satisfactory and aligned to a broader level of safety.
Now, when it comes to lean and small startups that work and build with AI, the problem of alignment still exists. You have a product that is meeting the needs of a certain kind of user spectrum. If product managers don’t step in and hone the product to the user's needs, then the product will not succeed.
To succeed, a PM must be user-centric and should have a mindset of a user to mold the product. PM responsibilities in AI evaluation are:
Defining success metrics tied to user tasks, not generic leaderboards. Read Lenny's Newsletter.
Build an AI evaluation framework with automated regressions plus targeted human review.
Use LLM-as-a-judge for scalable scoring, then calibrate with human audits. Read about Adaline’s LLM-as-a-judge doc.
Enforce release gates based on safety and quality thresholds before deployment. Read Anthropic.
By owning AI evaluation, product managers convert model capability into AI product success. That is how we move from prototype to durable value.
Understanding AI Evaluation Beyond Basic Metrics
Traditional software testing assumes deterministic code. AI systems are probabilistic and context sensitive, so classic unit tests miss silent regressions, tool-use errors, and jailbreaks.
In 2025, for instance, Google DeepMind updated its Frontier Safety Framework to standardize deployment mitigations for unpredictable capabilities, highlighting the gap with legacy testing.
So, what makes AI evaluation different from traditional testing? In software, I test deterministic functions. In LLM testing, I score probabilistic behaviors.
Think testing a spreadsheet versus testing a chef: the chef can make the same dish taste slightly different each time.
Teams that treat products as fixed artifacts fall behind. Artifact-thinking focuses on shipping outputs like features, models, releases, etc., while ignoring the systems that evolve them. In contrast, the organism paradigm views a product as a living system that learns, adapts, and improves post-deployment. — From Artifacts to Organisms
Core approach for AI system evaluation:
Task-level metrics: exact match, F1, and semantic similarity for generative AI evaluation.
LLM-as-a-judge: scalable rubric scoring, calibrated against human review. Read “An Empirical Study of LLM-as-a-Judge: How Design Choices Impact Evaluation Reliability.”
Regression suites: fixed datasets replayed across versions to catch drift. Platforms like Adaline allow you to run evaluations on 1000s of user feedback or golden datasets and see which ones fail and pass.
Reforge cut a major recommendation update from 1 month to 1 week, onboarded in 1 day. They enabled non-technical teams to ship via hot-swap deployments with iteration cycles reduced up to 50× by centralizing evals, deployment, and logs. That is how rigorous LLM evaluation metrics convert into faster releases and real ROI.
The Complete Framework for Product-Led AI Evaluation
I use a three-stage AI evaluation framework that turns fuzzy model behavior into product certainty. Stage 1 maps real-world AI performance patterns from user behavior. Stage 2 builds meaningful quality systems with LLM-as-a-judge. Stage 3 operationalizes continuous monitoring so teams ship faster with lower risk and higher ROI.
By the way, this is what Lenny Rachitsky also mentioned in his last post.

Stage 1: Mapping Real-World AI Performance Patterns
Lab tests hide how models fail with real users. Edge cases, ambiguous prompts, and context drift surface only in production logs.
I think that models, like GPT-5.1, Gemini 3, Claude Sonnet 4.5, or Opus 4.5, etc., are general models. They are aligned with more general safety measures and harmful scenarios. When we build products, we are much more domain-centric, and hence these general models fail to capture details and edge cases from user behaviour.
Without structured pattern mapping, teams optimize for synthetic wins and miss the behaviors that drive churn, cost spikes, and support tickets.
I analyze behaviors, not only responses. I segment by persona, task, channel, and context length. I cluster failures using error taxonomies, then quantify impact by frequency and business cost. I slice results by retrieval hit-rate, temperature, and tool-use paths to expose hidden regressions and hallucination pockets.
Funnel analysis: prompt → retrieval → reasoning → tool calls → answer.
Slice and dice: persona, document age, context size, latency bands.
Failure taxonomy: refusal, hallucination, off-policy tool use, unsafe output.
Track cohorts in Adaline, Arize Phoenix or Weights & Biases.

Capture user feedback with lightweight thumbs and tags. Prioritize fixes by “frequency × business impact,” then promote the top slices into your eval set.
Stage 2: Creating Meaningful Quality Assessment Systems
“Quality” is contextual. Legal, support, and growth teams value different things. A single accuracy metric misses tone, safety, and grounding. We need an AI quality assessment that reflects business goals, not leaderboard vanity.
System design. Combine automatic checks with calibrated judges and targeted humans.
Task metrics: exact match, groundedness, answer coverage.
Policy checks: safety, PII, tool-use constraints.
LLM-as-a-judge with a rubric aligned to user tasks, then human reviewer spot checks.
Evaluator prompt or Rubric:
You are a strict grader. Score 1–5 for: correctness, groundedness, actionability.
Return JSON: {"correctness":X,"groundedness":Y,"actionability":Z,"notes":"..."}
Expected output: a JSON object per sample that pipelines into dashboards and CI.
Calibrate judge scores to human labels weekly. Measure agreement, run holdout sets, and do pairwise preference tests before shipping.
Stage 3: Building Continuous Monitoring and Improvement Loops
Models drift after launch. Data distribution changes, providers update weights, and prompt chains evolve. Without continuous AI monitoring, quality and cost diverge from the business plan.
Automate canary and shadow tests on live traffic. Re-run nightly eval suites on top slices. Alert on:
Win-rate vs last stable, regression rate, and judge score deltas.
p95 latency, tool error rate, and token cost per successful task.
Safety violation rate and retrieval grounding gaps.
Stream traces to dashboards in Adaline, LangSmith, Arize Phoenix, or W&B. Gate releases in CI with thresholds tied to these KPIs.
Close the loop weekly: review slices, fix prompts by evaluation and iteration, fix tools, ship canaries, and auto-rollback on regressions.
Reforge’s evaluation-first workflow cut iteration cycles dramatically and supported hot-swap deployments. This is a production AI evaluation that compounds learning and ROI.
Remember, products are evolving as organisms via continuous iterations from user feedback.
Closing
LLM Evals is a skill that gets better and better every time you study users’ feedback. The feedback itself will allow you to write evals as rubrics. I believe that in the coming days, Evals will be all we need.

Writing good evals will ultimately be the key skill for any product managers, leaders, or builders.
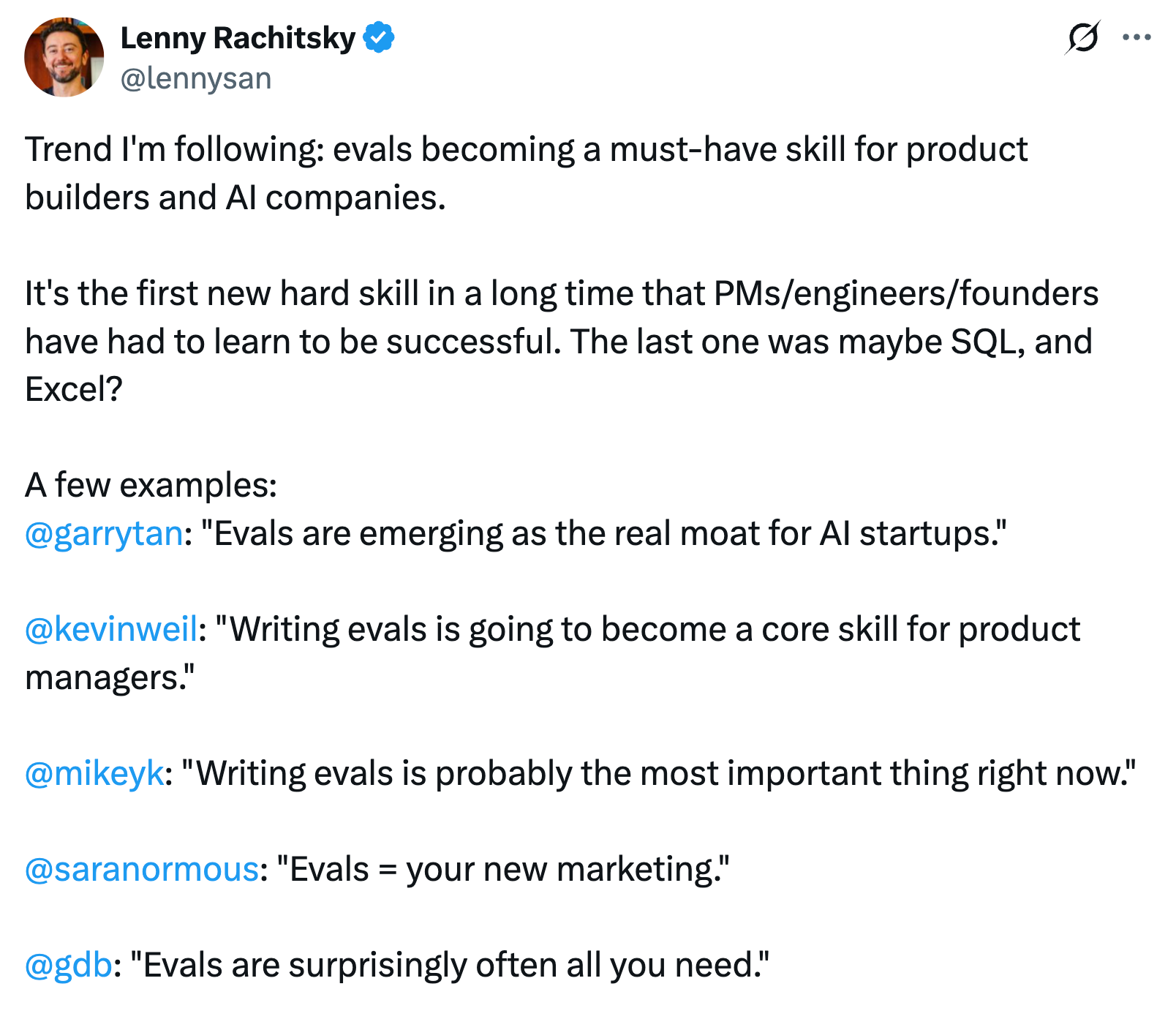
We are entering an eval-first era. Reinforcement learning now pushes models to near-perfect scores on fixed benchmarks, so only task-grounded tests reveal real quality.
Enterprises will invest heavily, creating new roles across domains. Dashboards matter only when tied to user pain, mapped through concrete failure modes. In lean teams, appoint one domain expert to judge quality. By describing what feels off, the right success criteria and useful evals emerge.