
The Long-Horizon AI Agents Ceiling Is A Product Problem
The planning ceiling is real, measurable, and not closing fast enough to be a roadmap. Five product moves that bypass it now, including the one that keeps the agent on its guardrails through long runs

TLDR: Long-horizon AI agents fail and fall short in measurable, predictable ways. And the failures are not closing fast enough to be a product strategy. This blog argues the planning ceiling is a product problem, not a model problem. It explains what the ceiling actually is and why “wait for the next model” is wrong. It also explains the five steps product leaders can take to ship reliable agents under the current ceiling. The fifth step, embeddings as working memory, is the one that keeps agents on their guardrails across runs that go hundreds of steps deep. Written for AI engineers, AI PMs, and product leaders building agentic products in 2026.

One decision sits at the center of agentic product work in 2026, and it rarely gets named out loud. The decision is how much of an agent’s output to trust without checking, and when, in the long run, that trust should be revoked.
Get this wrong in one direction, and nothing ships without human review, which kills the economics of the product.
Get it wrong in the other direction, and the agent drifts past its instructions deep into a run, with no one noticing until a customer ticket lands.
The reason this decision is hard is that the failure does not announce itself. Each individual step in an agent’s run looks fine when you read the trace: the tool calls return valid responses, the intermediate reasoning looks coherent, and nothing obvious appears broken.
The errors build up between steps, not inside any one of them. By the time the run finishes, the goal the agent started with has been quietly replaced by one that looks similar to the original. But it is not the same. There has been a slight drift.
That property is known as the planning ceiling. It is the horizon beyond which an agent cannot sustain coherent intent across steps, no matter how capable the underlying model is.
Let’s see the evidence. Look at how the strongest agents are actually performing today. METR’s most recent time-horizon reading measures how long an agent can work on its own before it fails. The strongest agent in their evaluation handles sixteen hours of work on a coin flip, and three hours of work reliably
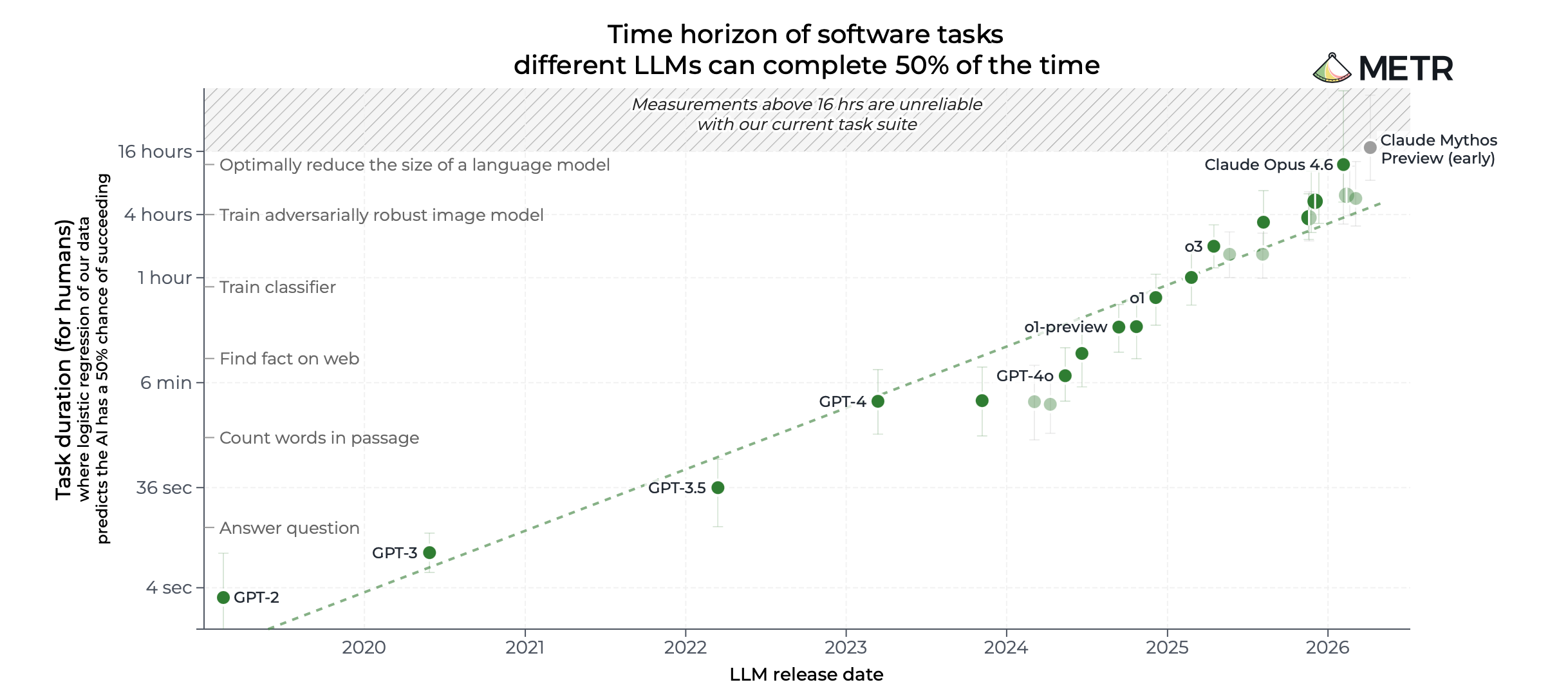
The five-times gap between those two figures is the whole problem to design around. A coin-flip ceiling is not a product you can ship. A three-hour reliable ceiling sometimes is, if the task fits inside it.
The PM job for agent products is now to figure out which ceiling their product sits under, and to design around the one they have. The planning ceiling for long-horizon AI agents is real, and it is happening in almost every small to large company. The truth is that it moves with product design, not with model releases.
What the Planning Ceiling Actually Is
Long-horizon planning failures in LLM agents are not vague, and the 2026 literature is specific about where they come from. In Why Reasoning Fails to Plan, the authors describe step-wise reasoning as a “greedy policy” that picks the locally best move at each step. The policy performs well over short horizons, but it breaks down as horizons grow. One of the reasons it happens is that the locally best move drifts away from the goal over time.
A second paper, The Long-Horizon Task Mirage, studies what changes inside the failure distribution as horizons grow.
The researchers find that subplanning errors and catastrophic forgetting take over as the run gets longer. The total error rate is not just higher; the shape of the errors is different, too.
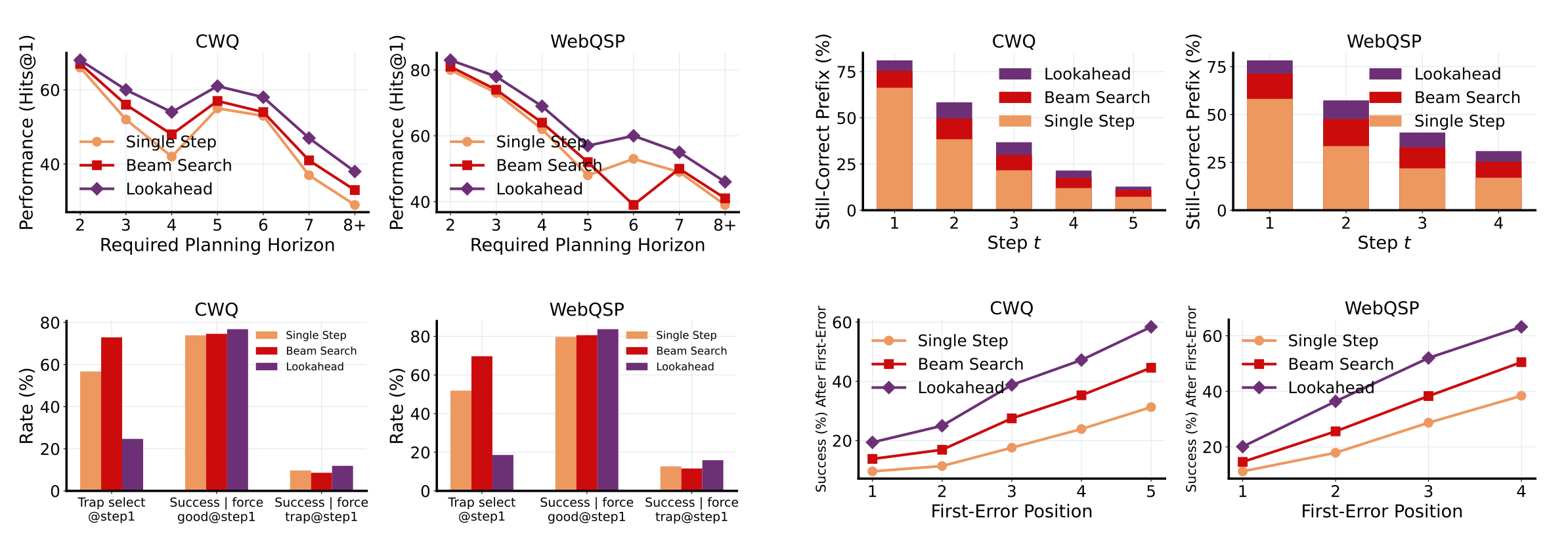
Three mechanical things go wrong:
Context dilution: As history grows, attention spreads thin. The Chroma team’s Context Rot study found that a 200K window can lose 30 to 50 percent of accuracy well before the window is full, and that structured input degrades faster than shuffled input does.
Goal drift: The agent gets pulled into the most recent tool output and loses the original objective. Multi-step plans tilt toward whatever just happened, not what was asked.
Compounding step error: Small per-step error rates multiply across dependent steps. A 2% error per step is a 33% failure rate over 20 dependent steps, and the failures are usually irreversible.
None of this is solved by adding more tokens to the context window. All three are about what the model attends to, not how much it can read.
Why “Wait for the Next Model” Is the Wrong Default
The METR doubling curve looks like a reason to wait for the next model, but it is not one. METR’s Time Horizon 1.1 update puts the doubling at 4.3 months, faster than the seven-month trend that held through 2025. Even at that pace, a model that fails today on a sixteen-hour task might succeed only in eight months, while a typical product cycle is twelve weeks long.
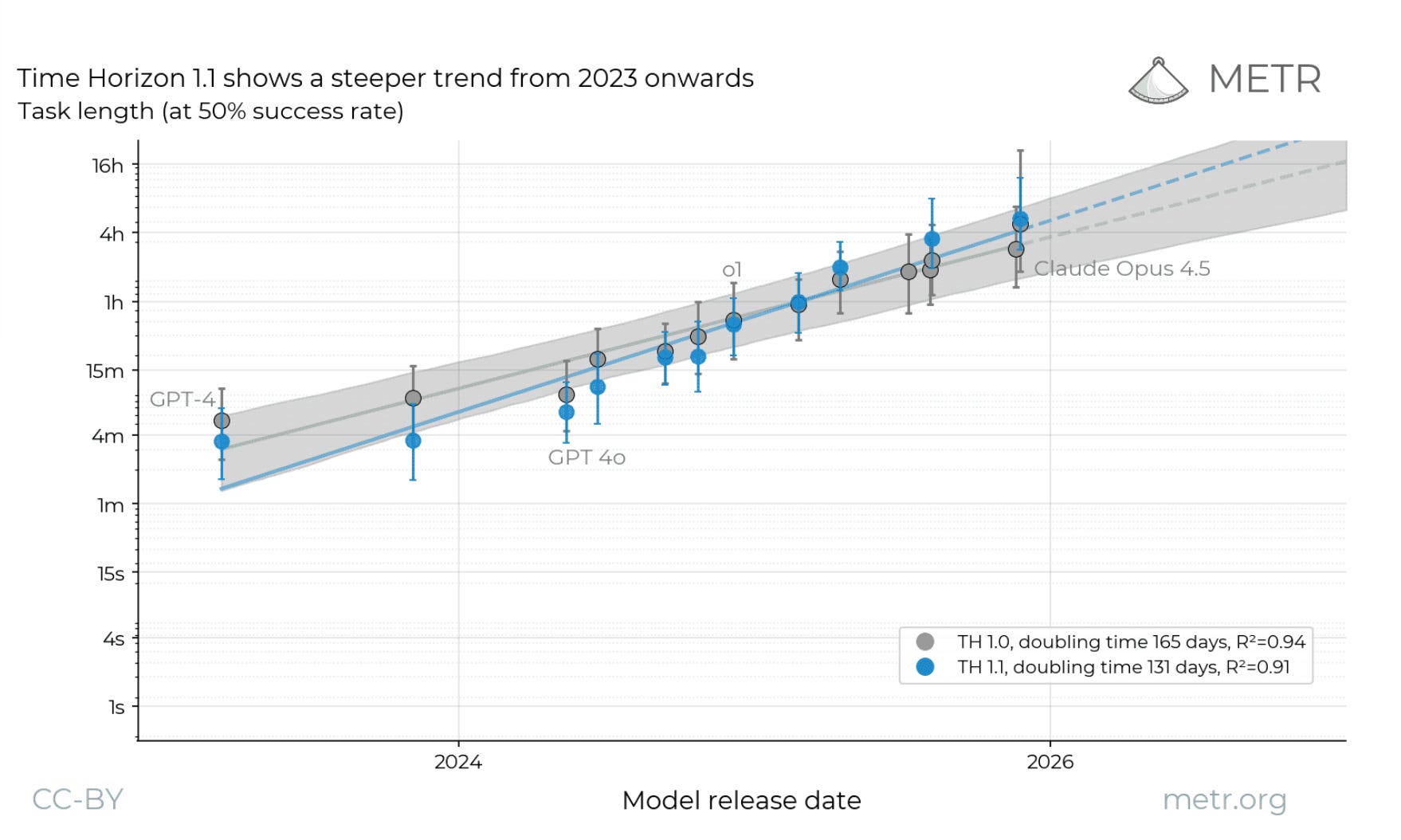
The model gets better over time, but the product has to ship on a deadline.
The deeper problem is that long-horizon failures are structural, not a question of model capacity. Anthropic’s engineering post on effective harnesses for long-running agents shows that even capable models lose continuity across session boundaries. This is a property of the harness and the memory model, not of the base weights.
Cognition’s annual review of Devin makes the same point from production, where roughly 60 percent of agent failures trace to the harness rather than the model.
Waiting buys a higher ceiling, not a working product.
Five Moves That Bypass the Ceiling Now
There are five places product leaders can act on today, without waiting for a model upgrade. The first four moves restructure the work itself, while the fifth restructures what the model sees on every turn.
That fifth move is the one that keeps the agent on its guardrails across long runs.
1. Scope the Task
Shrink the task until it fits under the current ceiling. A common path to failure today is treating the model as a senior engineer when it actually performs reliably as an intern with a clearly defined ticket.
A task that takes a human two hours can be reshaped into four thirty-minute sub-tasks. Moreover, the reshaped version is a fundamentally different product from the same task framed as one open-ended request.
Anthropic’s Scaling Managed Agents piece argues for the same split. It separates the brain that plans from the hands that execute, so each one operates at the horizon it actually handles well.
2. Checkpoint With Explicit Success Criteria
Break a long task into validated milestones, and treat each milestone as a contract. A checkpoint is not a status update. It is a state the agent serializes, a verifier the system runs against that state, and a recovery point the agent can resume from if the next phase fails.
Recent research formalizes this approach. The agent compresses progress at fixed intervals and re-reads from structured storage, instead of relying on context continuity.
Checkpoints are also the only way to ship long-running agents on a budget, because they cap the damage from a failed run to the last good state.
3. Recoverable State
Design the system to resume and replay, and treat partial success as a result worth keeping. The default agent system treats a failed run as binary: it either completed or needs to restart.
The cheaper design captures three things at the moment of failure: the last good checkpoint, the failure trace, and the cost spent so far. The agent then resumes from the checkpoint, with the failure passed in as context.
This is also what makes incident triage easier to manage, and it is how Cognition’s Devin team learned to recover long runs in 2025.
4. Embeddings as Working Memory
Pin the fixed guardrails and instructions at the top of the context, and retrieve everything else on demand. This is the move that keeps the agent on its rules across long runs, even when the run goes hundreds of steps deep.
The main reason lies in the Chroma data. Long context degrades attention unevenly, which means a system prompt written on day one will stop binding the agent by step 200 unless it lives in a persistent prefix. Our own earlier piece on why LLMs are getting dumber as context grows walks through the mechanism in more depth.
Everything else, including prior plans, tool outputs, and decisions, gets embedded and pulled in per turn, based on what the current step actually needs.
The product implications are real:
What to embed: Prior tool outputs, intermediate plans, decisions, summaries of completed checkpoints.
What not to embed: The guardrails themselves. Those go in the persistent prefix, not the retrieval store. Treating guardrails as retrievable content is how product teams accidentally let them drift out of context.
What memory needs: Eviction rules, freshness rules, and a permission model for what the agent can recall about whom. We have argued elsewhere that agent memory is a product surface, not an infrastructure detail.
This is how an instruction written on day one still applies to the agent on day 90, across thousands of runs, without filling up context or fine-tuning.
5. Human Handoff as a Designed Feature
Knowing when to escalate is half the work, and building the handoff that follows is the other half. A good handoff packet carries an intent summary, the information the agent extracted, the actions it attempted, and its confidence in the next step. Tune the agent for months and the handoff for a week, and you lose more on the handoff than you ever lose on the model.
A Decision Frame for Picking Moves
The five moves are not equally appropriate for every product. Pick by task value times reversibility:
High value, low reversibility: Tasks where a mistake is both costly and hard to undo, like financial transactions, irreversible writes, or regulated actions. Default to scope and human handoff, which keep the agent’s work small and stop it from acting on its own whenever its confidence drops.
High value, high reversibility: Tasks that matter to the business but can be rolled back, like long research, code generation, or content drafts. Default to checkpoint and recoverable state, so a long run can resume from the last good state instead of starting over each time something fails.
Low value, low reversibility: Tasks where each action is small, but the agent repeats it thousands of times without anyone watching, like notifications, side effects, or automated outreach. Default to embeddings as working memory and tight guardrails, so the agent stays on its rules even when no one is checking each run.
Low value, high reversibility: Tasks that are easy to fix and not critical, like drafts, suggestions, or low-stakes automation. Default to scope, and keep the task small. Anything heavier is not worth the engineering cost.
The five moves work in combination, not in isolation. A serious agent product runs scope plus checkpoints plus recoverable state plus embeddings-as-memory plus handoff. The mix gets tuned to the value-reversibility quadrant that the product sits in.
The PM Job Has Changed Shape
The PM job for agentic products has changed shape over the last year. It used to be “describe what good looks like and brief the engineering team.” For long-horizon AI agents, the job is now “define a task small enough to complete reliably, and measure the boundary where it stops being reliable.”
The model keeps changing, while the product is the part that you can keep steady long enough to ship.
The teams that successfully ship agents in 2026 will not be the ones that catch the next model release first. They will be the ones who designed the work to fit under the current ceiling. They kept the guardrails persistent across long runs. They treated the handoff as a product feature, not a bug.
The ceiling moves with product design, not with model releases, and that is the call to make.