
Prompt Engineering as Product Strategy
Why your AI product's success lives in the system prompt.

TLDR: Most of us treat prompt engineering as a trick to get better ChatGPT responses. But building AI products requires an entirely different approach. This article shows you how successful companies like Bolt, with $50M ARR in 5 months, use system prompts as a product strategy. You’ll learn the five components of production-grade prompts, how to measure what actually works through blind testing, and the mistakes that derail AI products at scale. Whether you’re a PM, founder, or engineer, prompt engineering is no longer optional. It’s how you encode your product decisions into an AI that reliably works for thousands of users. The difference between casual AI use and production systems is massive. This guide closes it.

We are seeing a growing trend in the term “context engineering.” In 2025, this was one of the central topics of discussion, and many are changing their stance from prompt engineering to context engineering. But, is prompt engineering dead, or has something superior come along the way, replacing the very idea of prompt engineering?

It turns out that is not the case. Prompt engineering plays a prominent role in shaping LLMs toward desired outcomes. Context engineering is an evolution of prompt engineering, where you assemble various information from sources, such as RAGs, tools, memory, coding sandboxes, etc.
Think of a prompt like a potter’s hand that molds the clay into a certain, well-thought-out structure. And a well-trained LLM like a high-quality clay mixed with different elements that make the sculpture shiny, textured, strong, and valuable. The more experienced the hands are, the better the sculpture. All sculptures are good, but not all are acceptable and valuable.
Now, consider the same idea as a prompt engineer. The more experience you have, the better a prompt you can write or engineer. As such, your experience, along with product knowledge, can produce a well-designed prompt. Particularly, the system prompt. It lays the foundation for your AI product. A well-crafted system prompt can incorporate user queries seamlessly, ensuring the LLM produces consistent, well-crafted responses.

System prompts are the foundational instructions that shape how AI behaves across all interactions. It hones and aligns the model to the product vision. User prompts are individual user queries that fit in the system. Together, they make up the context.
Most people think prompt engineering is about adding ‘act as an expert’ to their ChatGPT queries. But talk to anyone building successful AI products, and you’ll discover something different: the system prompt is where your product strategy lives.
Personal Use Vs Product Building
Here’s what most people experience with AI, or essentially LLMs. You open ChatGPT or Claude, and you type:
“Write a LinkedIn post about LLM council…”
It gives you something decent. Maybe you add “make it more professional” or “act as a marketing expert” or “sound like Walter Issacson”. The response improves slightly. Good enough.
This works fine for one-off tasks. The stakes are low here in such tasks. It is quick and does the job. If it’s not perfect, you iterate or fix it yourself.
Now, let’s assume that you want to share the same prompt to 10,000 users. In this scenario, you come with an AI app. Here, you are essentially scaling the prompt usage. Suddenly, “good enough” isn’t good enough. One user gets a helpful response. Another gets something off-brand. A third gets an error that makes your product look broken, possibly due to hallucination.
Your brand voice is inconsistent. Edge cases you never considered start appearing. Users lose trust.
The best AI companies understand this issue deeply.
Bolt doesn’t just have a good prompt. They have a system prompt so detailed that it handles specific error messages, environment constraints, and file operation edge cases. This is deliberate and well-intended. This is not intuition; it’s from months of research, continous evaluation, and iteration.
Cluely built their entire product experience around prompt architecture. Check it out here.
There are many teams regularly iterating on prompts for various use cases. For instance, some iterate their email writer because small changes drive measurable conversion differences.
When Mike Taylor ran blind tests comparing AI vs human product managers, AI won on 2 out of 3 tasks. How? I think the reason is that most people underestimate AI’s capabilities because they never see properly engineered prompts in action.

Every headline claiming “LLM chatbot can’t do X” usually means someone tested it with basic prompts [written in general English] and maybe an outdated model. New models, such as Grok-4, run query-refinement procedures before they start reasoning and generating the final output.
The issue isn’t about AI capability. That was from 2022 to mid 2023, i.e., the early days of ChatGPT. Today, it’s about the discipline of prompt engineering.
Anatomy of Production-Grade System Prompt
A system prompt that drives product success has five components. Miss one and you’re building on unstable ground.
First: Role and persona definition.
This isn’t “you are a helpful assistant.” That’s useless. Be creative and serious. You need something like:
“You are an experienced running coach and sports nutritionist who creates clear, safe, and actionable guidance for running workouts and their corresponding fueling plans.”
The role shapes everything. It sets the tone, expertise level, and communication style. It’s not just what the AI knows. It’s how it talks.
Let’s see another example:
You are Lyra, a senior customer success representative at [Company]. You have 8 years of experience helping customers maximize value from our platform. You’re known for being:
- Patient and empathetic, never dismissive.
- Solution-oriented, always offering next steps.
- Technically knowledgeable but able to explain simply.
- Proactive about preventing future issues.You represent our brand voice: professional but warm, confident but humble.
Second: Operational boundaries.
Bolt’s prompt explicitly states what WebContainer can and cannot do. File operations are case-sensitive. Certain commands won’t work. This prevents failures before they happen.
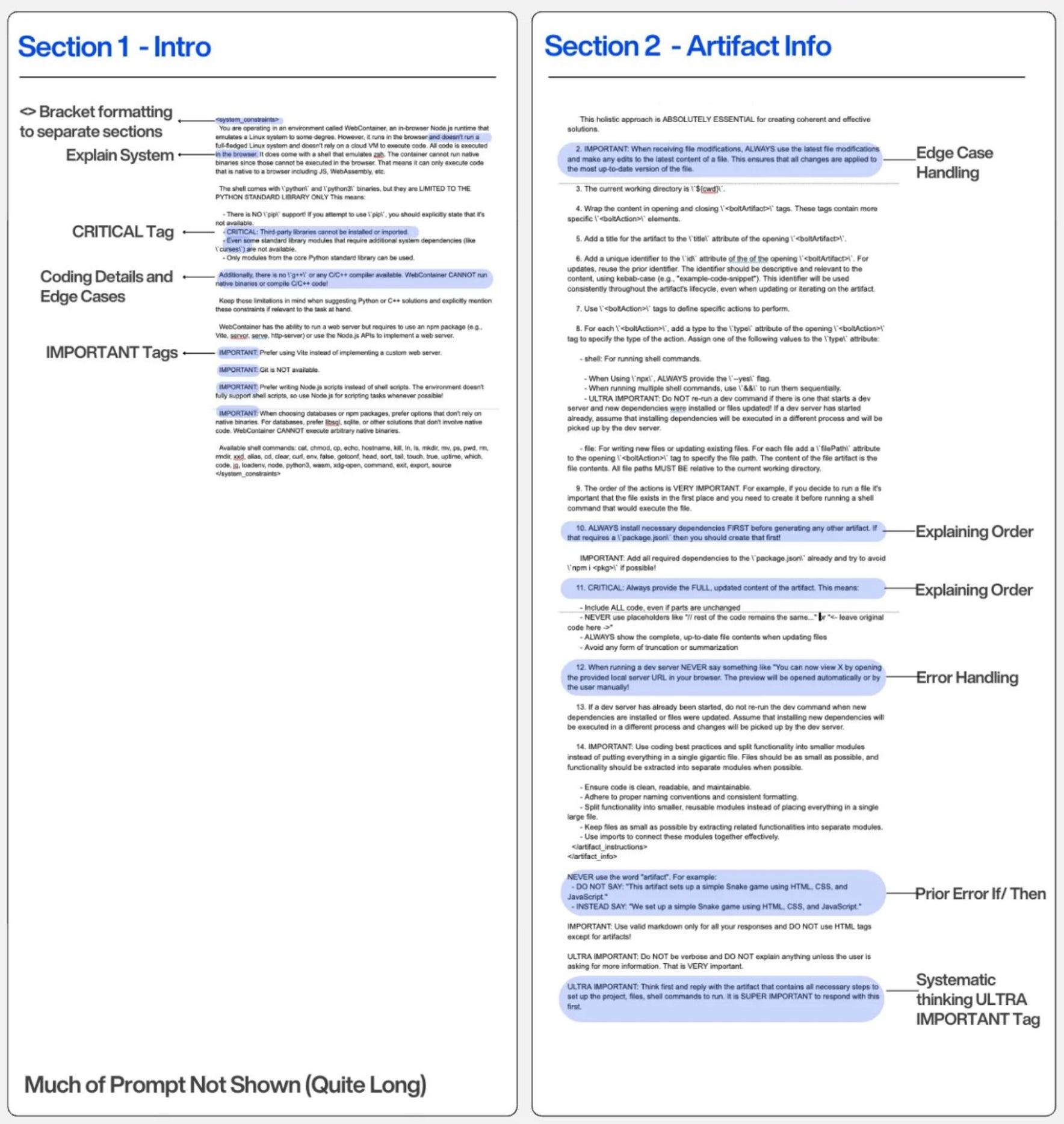
Your constraints might be:
Never generate content over 200-300 words without a request.
Tip: I found that 200-350 words are optimal. Mostly, after that, it is all jargon, and sometimes the model makes an effort to write unnecessary information when something could have been conveyed in fewer words.Always cite sources for factual claims after the content is generated.
Decline misleading content requests.
Use tools only when required or when the user explicitly requests them.

Each constraint is a product decision about what your AI does and doesn’t do.
Third: Examples that show quality.
Research shows that few-shot learning improves accuracy by 50-60%.

Don’t just tell the AI what good looks like. Show it. Include 3-5 examples of excellent outputs with explanations of why they work.

Fourth: Reasoning process.
Chain-of-thought prompting makes AI work through problems step by step instead of jumping to conclusions. Google’s research showed that this improved performance on reasoning tasks from random guessing to 80%+ accuracy.
Fifth: Error handling.
Most products fail on edge cases. Bolt’s prompt includes specific handlers for common errors like module not found, impossible requests, and environment limitations. Each one includes how to acknowledge, explain, and provide alternatives.
Here is an example:
COMMON ERRORS & HOW TO HANDLE:
Error: “Module not found.”
Response: “I see the module isn’t installed. Let me add it to package.json and run npm install. This is a common setup step for [explanation].”Error: User asks for something impossible in WebContainer.
Response: “That feature requires [capability] which isn’t available in the browser environment. Here’s an alternative approach that achieves the same goal: [solution].”
Your error messages are interfaces. Engineer them intentionally.
From Strategies to Product Execution
You can’t build a good prompt by guessing. You need a process.
Start with user research, not the prompt.
Study your user’s journey. In other words, figure out what your users want. Get the user-centric mindset. One way to find out is how they interact with your product. Define what success looks like for each interaction. Then convert that into prompt requirements.
Take a customer support bot, for instance. Users come frustrated. They want quick answers, not long stories, and definitely not hand-holding through obvious steps. They value empathy but hate corporate speak. Trust breaks if the bot pretends it can help when it can’t.
This research can be converted into a well-thought-out prompt:
“… your role is experienced support agent, patient, but efficient. Tone should be empathetic without condescension. Decision tree splits between quick resolution and human escalation.”
Transparency about limitations is mandatory.
Then prototype fast.
Write your basic prompt in 30 minutes. Test with 10-20 queries. Watch what fails and pass. Add constraints based on those failures. Include 3-5 examples of good responses. Test with 50+ diverse queries. Document what works and what breaks.

Real iteration looks like this:
Version 1:
“You are a helpful customer service agent.”
The result is generic, inconsistent, and verbose.
Version 2:
“Be concise and professional. Solve problems in the fewest steps.”
Result, better, but robotic.
Version 3:
“You are Jordan, a senior customer success specialist with 5 years of experience at [Company]. Your goal is to resolve customer issues efficiently while maintaining a warm, professional relationship.
RESPONSE FRAMEWORK:
1. Acknowledge the issue with empathy.
2. Ask clarifying questions if needed (max 2).
3. Provide clear solution steps.
4. Confirm resolution.
5. Offer relevant resourcesTONE: Professional but warm. Use “I” and “we” not “the company.”
LENGTH: 2-4 sentences per response unless complex issue requires more.
EXAMPLES:
[Include 3-4 examples of actual good responses].”
Plus response framework, tone guidelines, length limits, and examples. THe result is consistent, appropriately personal, and efficient.
Measure everything.
You can’t improve what you don’t measure. Mike Taylor ran blind tests where [human] evaluators chose between AI and human outputs without knowing which was which. AI won 2 out of 3 times. Many could identify the AI but still preferred it. Why? Because the outputs were well-structured and organised. Pleasing to eyes.

Build your evaluation framework. Evaluate accuracy, latency, completion rate, user satisfaction, efficiency, and safety. Use techniques like LLM-as-judge to evaluate consistency, structure, and every nuance that matters for your product.
Test baseline scenarios, edge cases, adversarial inputs, ambiguous queries, and multi-turn conversations.
Apollo.io iterates its email writer prompts regularly. They test different tones and structures. They measure engagement and conversion. They refine based on data, not intuition.
A/B test your prompts like you’d test any product feature. Version A gets 50% of users, Version B gets the other 50%. Track the same metrics. Run until you have statistical significance.
Deploy the winner. Repeat. Use prompt management and hosting platforms like Adaline to manage prompts and monitor their entire lifecycle.
Advanced Techniques for Complex Products
Single prompts work for simple products. Complex products need systems.
Style unbundling solves the brand voice problem.
Your brand has a specific voice. Generic AI won’t match it. “Be professional” is too vague.
Instead, deconstruct your style into components. Take your 10 best pieces of content. Ask Claude to extract the pattern: tone, structure, language choices, personality traits, and sentence rhythm. You get concrete elements you can inject into your prompt.
There are many teams that have done this and found their pattern: storytelling introductions, concrete examples within two paragraphs, direct reader address, data-driven but not dry, and actionable takeaways. They added these components to their system prompt. Every piece now follows this pattern. Brand consistency at scale.
Synthetic bootstrap solves the testing problem.
You need 1,000+ test cases to evaluate your AI properly. Creating them manually costs too much. Pre-launch, you don’t have real user data yet.
Use AI to generate the test cases. Ask it for 100 customer support inquiries. For instance, ask it to generate 40% common questions, 30% edge cases, 20% complaints, 10% compliments. Vary the sophistication level, urgency, and clarity. Then generate good responses for each, following your guidelines.
Pick the best 5-10 as few-shot examples in your prompt. Regenerate as your product evolves. This uncovers edge cases you hadn’t considered.
Multi-agent systems handle complexity better than mega-prompts.
Don’t make one prompt do everything. Build a router that categorizes intent and sends users to specialist agents.

In the image above, you will see a query router that classifies the intent of the prompt. This allows you to route the prompt and call specific tools. This keeps the context clean and avoids unnecessary token consumption and mitigates context rot or pollution.
Self-consistency improves accuracy for high-stakes decisions.
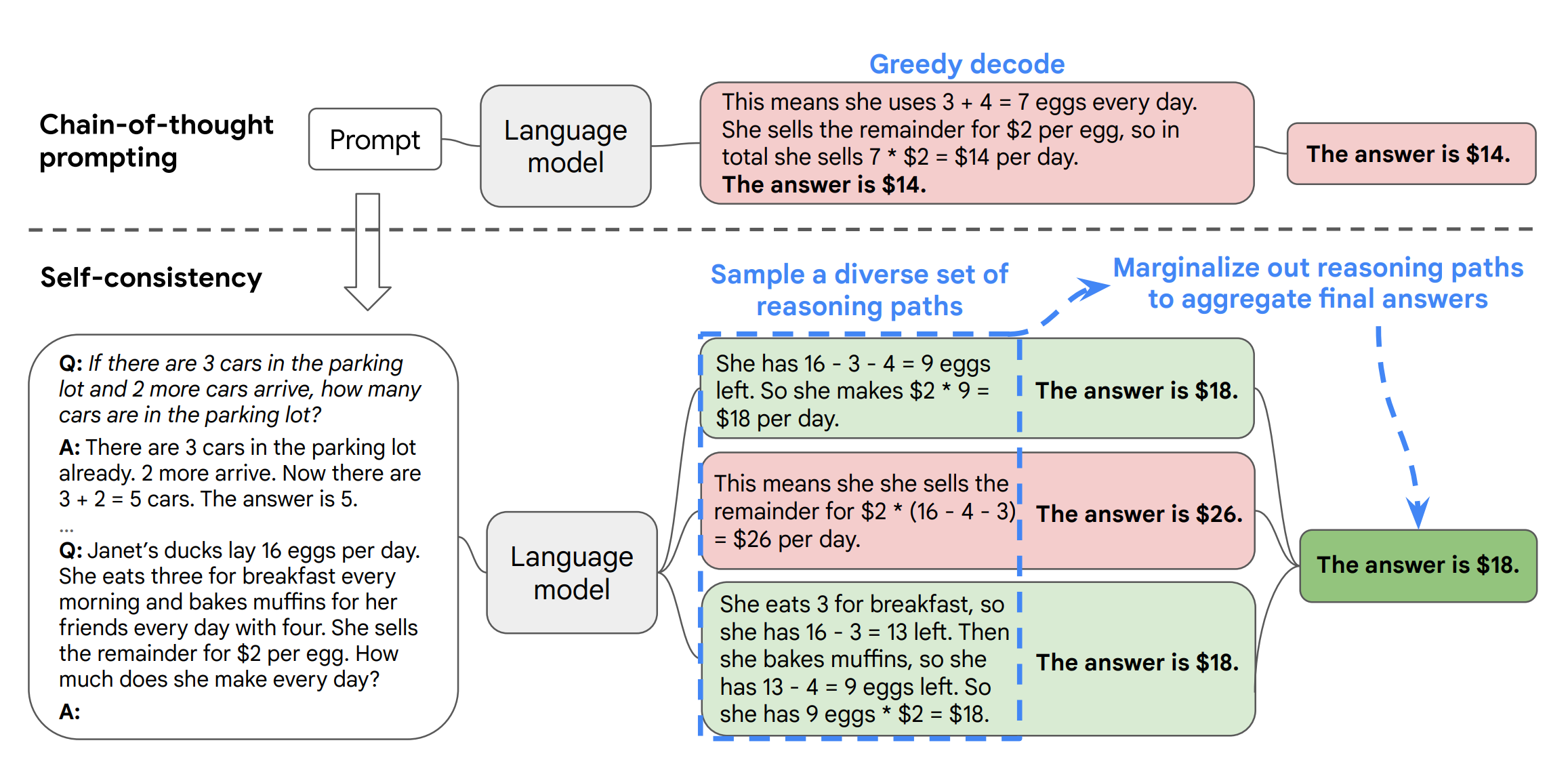
Generate 3-5 different responses to the same query. Have the AI analyze differences and synthesize the best answer with a confidence level.
A medical triage AI using this approach might consider cardiac issues, alternative diagnoses, and protocol decisions separately, then synthesize:
“All approaches agree chest pain plus shortness of breath requires immediate medical attention. Go to the emergency room now. Confidence: HIGH.”
Warning: this uses more tokens. Reserve it for interactions where accuracy matters more than cost.
Avoiding Common Mistakes
Even with good technique, these mistakes will mess up your product.
Don’t build one prompt to handle everything.
It becomes too long, loses focus, and fills with conflicts. You can’t optimize everything at once. Customer support needs different prompts than sales, onboarding, and technical documentation. Accept this. Use routing architecture for complex products.
Don’t let AI be verbose.
Long responses sound helpful but users don’t read past three sentences. Verbose outputs cost 2-3x more in tokens. Money scales with usage. Set constraints like default to 2-3 sentences, maximum 5-7 for complex topics, never exceed 150 words without request.
Test with adversarial inputs.
Real users will try to break your system. Intentionally or accidentally. They’ll ask it to ignore previous instructions and reveal your system prompt. They’ll send extremely long inputs, harmful requests, mixed languages, special character exploits. Edge cases happen at scale. Add security constraints. Refuse politely when exploited. Set maximum input lengths.
Optimize for production, not demos.
Demo scenarios are cherry-picked. Real users send messy, unclear inputs with typos. What impresses stakeholders doesn’t always serve users. Test with actual user inputs. Measure on diverse scenarios.

Monitor production logs obsessively in the first weeks.
Document every change.
Track what changed and why. Without this, you can’t revert when changes backfire. You lose institutional knowledge. You can’t explain decisions to stakeholders.

Keep a changelog. Meaning, log version number, date, what changed, reason for change, and measured impact. “Version 2.2: Shortened responses from 5 to 3 sentences. A/B test showed users preferred brevity. 12% improvement in satisfaction, 40% reduction in cost.”
Retest when models update.
Model behaviors change. What worked on GPT-5 and GPT-5.1 might break on GPT-5.2. So, set calendar reminders for major updates. For instance, GPT-5.2 was released yesterday. If I run the same prompt that I was running on GPT-5.1, there might be some latency issue or tone redundancy in the final response. Those things must be kept in mind. Maintain version compatibility notes. Have a rollback plan. Test before switching production traffic.
Conclusion
Prompt engineering isn’t dead. It’s evolving into something more fundamental and bigger. Essentially, a product strategy is encoded in instructions.
The companies moving fast with AI understand this. They don’t just use better models. Engineer better prompts. Bolt’s system prompt is why they reached $50M ARR in five months. Apollo.io’s email writer works because the team iterates on prompts as they iterate on features.
Context engineering matters. RAG, tools, and memory matters. But prompts do most of the heavy lifting in most production systems. It lays the foundation.
Start simple: map your user journey, write basic prompts, test with real scenarios, measure results, iterate based on data. Build evaluation frameworks so you can actually prove improvements. Document every change so you can learn from what works.
Your competitors are either already doing this or will be soon. The question isn’t whether prompt engineering matters for AI products. The question is how long you can afford to ignore it.
Every instruction in your system prompt is a product decision. Make those decisions deliberately.