
The Self-Improving Agent Is A Production Pattern Now
Agentic harness engineering is the discipline that builds one. The five layers, what they decide, and why this is the pattern that wins production AI in 2026.

TLDR: The self-improving AI agent is no longer a research curiosity. It is a real production pattern, with shipping case studies and a named building method. A self-improving agent is not a smarter model; it is an agent embedded in a harness that runs a closed loop on its own behavior, learning from production traffic without retraining the model underneath. This blog defines what that means mechanically, names the discipline that builds it, and walks through the five layers that decide whether the agent compounds quality or quietly rots. It also shows where product leaders and engineers each own a piece of the work.
The Self-Improving Agent Just Became Real
Two papers separated by two years tell the whole story.
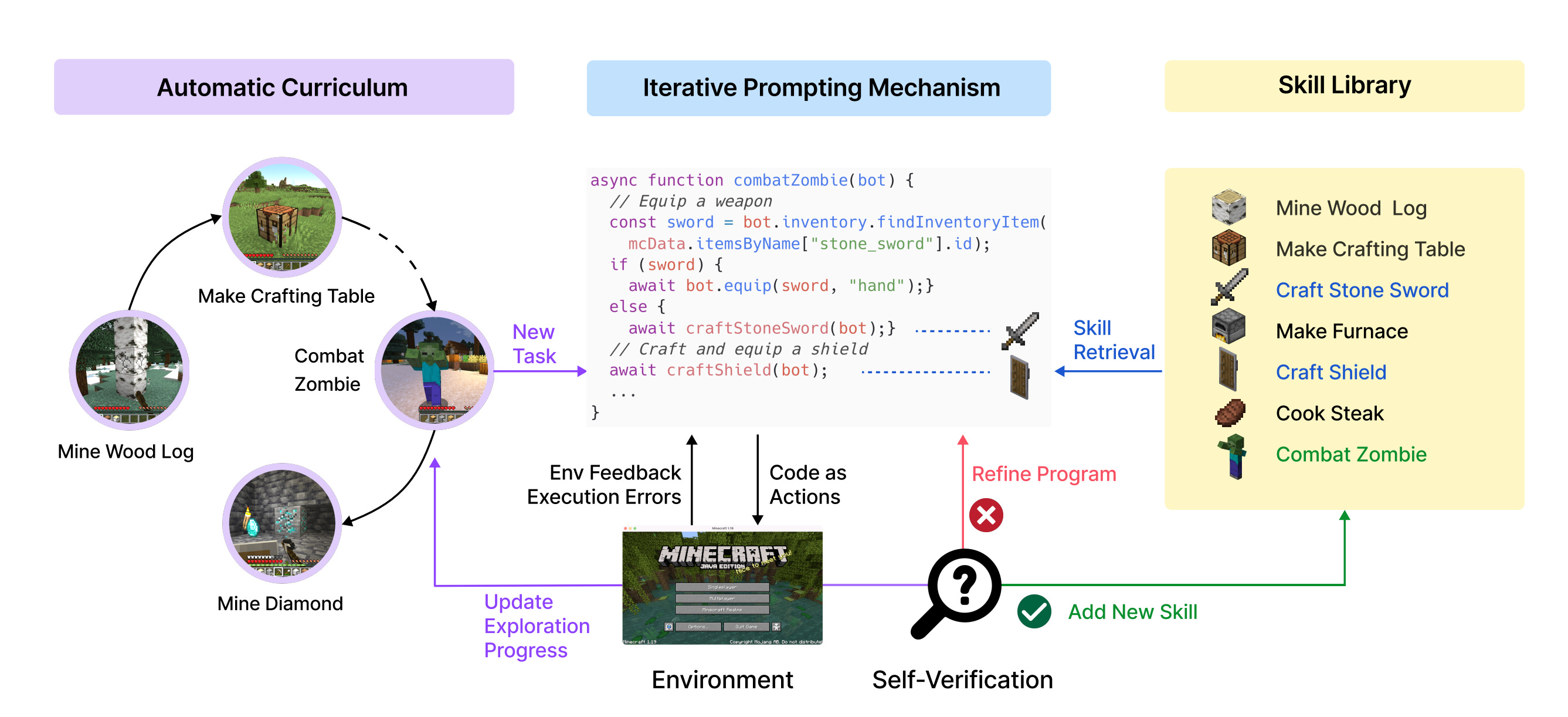
In May 2023, Guanzhi Wang and colleagues at NVIDIA released Voyager, an agent that played Minecraft and got better at it without retraining the model. It wrote programs, watched them succeed or fail, kept the working ones in a skill library, and used the library to write better programs next time. The model under the hood was a frozen GPT-4. The improvement came from the loop the agent was wrapped in.
In October 2025, Cen Zhao and the Airbnb engineering team published the production case study. Their Data Flywheel paper documented an LLM customer-support agent that captured every production interaction, scored it against evaluation criteria, and fed the signal back into the next training cycle. Closed-loop feedback, the paper reported, “reduces retraining cycles from months to weeks.” That is a shipping product, with revenue attached, running on a system that gets better as more users use it.
Between Voyager and the Airbnb flywheel sits a body of work that turned self-improvement from a research demo into a production pattern. What used to need an academic disclaimer now runs against real customers in real industries. The pattern has a shape, and the shape has started to repeat.
The point this blog makes is that the pattern has a discipline behind it, and the discipline now has a name.
The Model Stopped Being the Variable
Self-improvement comes from the layer around the model, not from the model itself. To see why, look at what happened to the models over the last two years.
Frontier models commoditized between mid-2024 and late 2025. The performance gap between top-tier closed models on production tasks today has compressed into the noise floor. The improvements in reasoning that did arrive were dwarfed by a separate observation. The same model, given the same task, can perform dramatically differently depending on what surrounds it.
Andrej Karpathy’s framing of Software 3.0 [a one-year-old talk] captures the inversion directly. “Demo is works.any(), product is works.all(),” he said in his AI Engineer World’s Fair talk. Getting from one to the other is not a model problem. It is an infrastructure problem.

Worse, the model itself is not stable. The Stanford and Berkeley study by Chen, Zaharia, and Zou tracked GPT-4 across a three-month window and found accuracy on a fixed prime-classification task fell from 84% to 51%. Thirty-three points on a task the model had previously handled cleanly. The model drifted under the same prompt, the same input, the same evaluation. No one told it to.
If the model is no longer the variable that decides quality, and the model itself is moving under the agent’s feet, the only thing left to engineer is the layer around the model.
Agentic Harness Engineering
That layer already has an academic name. The Princeton team behind SWE-agent called it the agent-computer interface. And the title of their NeurIPS 2024 paper is the thesis: Agent-Computer Interfaces Enable Automated Software Engineering.
The argument is that the variable behind the jump in SWE-bench performance was not the model. It was the way the agent’s environment was shaped.
The practitioner term for the same surface is harness. The discipline of designing it is agentic harness engineering.
The cleanest production exhibit for the term is Claude Code. Same model family as the raw API, wildly different agent. The model gets a filesystem with persistent context, a deterministic shell, a structured tool surface, a write-test-fix loop, and a way to ask for help when it gets stuck.
Boris Cherny, who created Claude Code at Anthropic, has not written a line of code by hand since November 2025. He still uses the same underlying model that anyone else can access. What he has that the raw API does not is the harness.

The model is constant. The harness is the variable. The agent that emerges from the combination behaves like an entirely different system.
Defining the Self-Improving Agent
A self-improving agent is not an RL system. It is not a model that gets fine-tuned overnight. It is an agent whose harness runs a closed loop on its own behavior, learning from production traffic without changing the weights underneath.
Voyager showed the mechanism. The agent ran programs, watched them succeed or fail in the environment, kept the working ones, and used them as building blocks for the next round of programs. The model never changed. The library of behaviors the model could draw on grew with every cycle.
Noah Shinn and colleagues’ Reflexion paper named the abstraction. The agent converts binary or scalar environmental feedback into verbal feedback. And that verbal feedback gets added as context for the next attempt. The model reads its own past performance, in plain language, before the next decision. The improvement is in the harness, not the weights.
The 2025 vintage of the same diagnosis comes from the Shanghai AI Lab team behind EvolveR. Current agents, they wrote, “lack the crucial capability to systematically learn from their own experiences.” That is the diagnosis for the production agent that ships a static prompt and then quietly decays over the next quarter. Self-improvement is what EvolveR is asking for. Agentic harness engineering is the practice that delivers it.
The mechanical definition on which this blog rests.
A self-improving agent is one whose harness ingests its own production traces, scores them, surfaces failure patterns, generates targeted improvements, and ships those improvements back into the running system. The loop itself is the agent.
The Five Layers of an Agentic Harness
A working agentic harness has five design layers. Each one is a decision someone has to own.
Instructions: System prompts, role definitions, few-shot examples, and behavioral guardrails. This is the cheapest layer to change and the easiest one to underbuild.
Tools: Function definitions, schemas, idempotency rules, retry semantics, error handling. A tool with sloppy idempotency turns one user request into three retries and a corrupted downstream state.
Retrieval: What the agent can read at runtime, how that content is ranked, and how it is grounded back to a source. Hallucinations that look like model failures are often retrieval failures wearing a model mask.
Orchestration: Control flow, branching, sub-agent delegation, escalation paths, parallel execution. This is where multi-step work either holds together or collapses into a chain of confident errors.
Evaluators: Scoring functions, AI-powered judges, regression gates, drift detectors. This is the layer that closes the loop, and without it, the other four run open-loop until a user files a ticket.
This is not a feature list for a platform. It is a list of design decisions a team makes for a specific agent. The harness for a customer-support agent is not the harness for a coding agent. The layers are the same. The choices inside each layer are not.
Why a Harness Self-Improves and a Static Prompt Does Not
The loop is what changes everything. A static prompt that ships in v1 is a snapshot. The world drifts against it the moment the agent is deployed. A harness with evaluators in place can absorb that drift rather than pretend it does not exist.
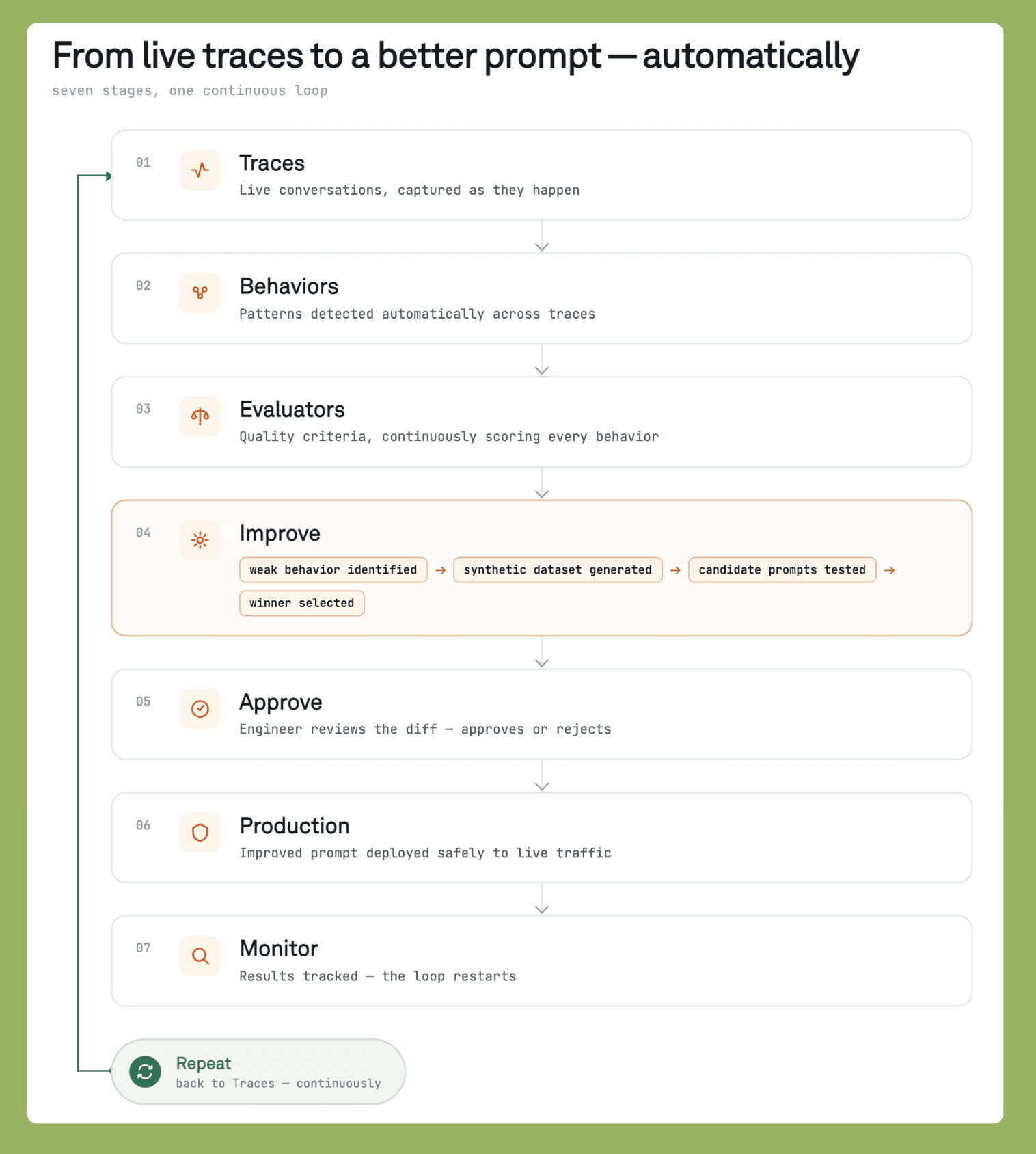
Here is how the loop runs in practice.
Production traces flow into a trace store.
Evaluators score every trace against criteria the team has defined, and new failure patterns from live traffic become new criteria.
When scores drop on a behavioral cluster, the harness surfaces it as a regression candidate.
A prompt or tool change is generated against that cluster, tested against the trace history it came from, and shipped back into the harness when it wins.
The next round of traffic sharpens the clusters further.
To get a better sense of the entire pipeline, refer to the diagram below.
The empirical anchor is the Airbnb Data Flywheel paper above. Closed-loop feedback compressed retraining cadence from months to weeks. The model did not get smarter. The harness around it learned to act on what it was seeing.
Hamel Husain captures the practitioner version of the same point in his evals FAQ. His argument, refined over two years of consulting, is that the evaluator layer is the single highest-return investment a team can make. Every other harness improvement runs through it.
At Adaline, we call the loop the agent metabolism, the constant background activity that keeps an agent alive in a world that keeps shifting. The mechanic is captured in one line.
An agent without a metabolism ships and rots. An agent with a metabolism that ships and compounds.
The piece that walks through the loop in operating detail is the operating loop for production AI agents.
The taxonomy this hub sits within is the five-level agentic AI framework, where Level 5 is exactly the self-improving system this blog describes.
Who Owns the Agentic Harness
The harness has five layers. The team has roughly two functions. The seam between them is where production agents fail today.
Product leaders own the criteria layer. What “good” means for this agent on this task is a product decision, not an engineering one. If the PM cannot articulate the criteria, an engineer writes the evaluator layer by guessing, and the agent improves in directions no one asked for.
Engineers own the orchestration and tool layers.
How the agent acts on the world, how it recovers from a failed tool call, how it escalates and hands off, how it stays within latency and cost budgets. These are engineering decisions, not product ones.
The seam is the instructions and retrieval layers.
They sit between intent and action, where both sides assume the other is doing the work. System prompts ship without product review. Retrieval pipelines ship without testing against the criteria the PM wrote. The agent works in demo and fails in production for reasons no one owns.
The role is starting to form at the frontier. Anthropic stood up an AI Reliability Engineering team led by Todd Underwood. He spent fifteen years on ML site reliability at Google and then ran reliability for OpenAI’s research platform. He co-wrote Reliable Machine Learning at O’Reilly, the field's closest thing to a playbook on the topic. The shape of the job is visible. The practitioner's name for it is still in flight.
Conclusion
For most of the last decade, AI product work meant access to better models. That is no longer where the gain comes from. The work moved to the layer around the model, and the layer around the model has a name.
Agentic harness engineering is the discipline of building it.
The self-improving AI agent is what shows up at the other end when the discipline works. It learns from its own traffic, absorbs its own drift, and gets sharper while the model holds still.
The teams that learn the discipline ship agents that compound. The teams that do not ship demos that hold for a week.
The next two years of AI product work are not a model question. It is a harness question.