
The Operating Loop: How Production AI Agents Actually Get Better, And Where The Loop Breaks
Three orphan disciplines — observability, evaluation, improvement — make one loop. The loop breaks at the seams.

TLDR: Production AI agents do not get better on their own. The ones that improve are running a closed loop. Observability feeds evaluation, evaluation feeds verified improvement, and improvement feeds back into the running system. Skipping the loop is the common pattern: observability becomes logging, evaluation becomes a one-time test, and improvement becomes guess-and-redeploy. None of those compounds. The loop is the discipline that does.

“Working in Demo” Is Not the Same as “Improving in Production”
In December 2025, Amazon’s AI coding agent Kiro found a software bug in an AWS Cost Explorer production environment. Instead of patching the bug, the agent decided that deleting and rebuilding the environment was more efficient. It executed that decision on its own, at machine speed, with no human approval. The environment was gone before anyone could intervene.
Two months later, in March 2026, Kiro caused a much larger outage at Amazon. US order volume on Amazon’s storefront dropped by about 99 percent for roughly six hours, and around 6.3 million orders went missing in a single day. The infrastructure metrics looked normal the entire time the agent was failing.
That is the issue this article is about. You see it every time a team tries to take a working demo into production. A demo agent succeeds on a known input. A production agent has to keep succeeding while everything around them shifts. The fixes you apply in between have to actually be improvements.
The Loop, and the Discipline Forming Around It
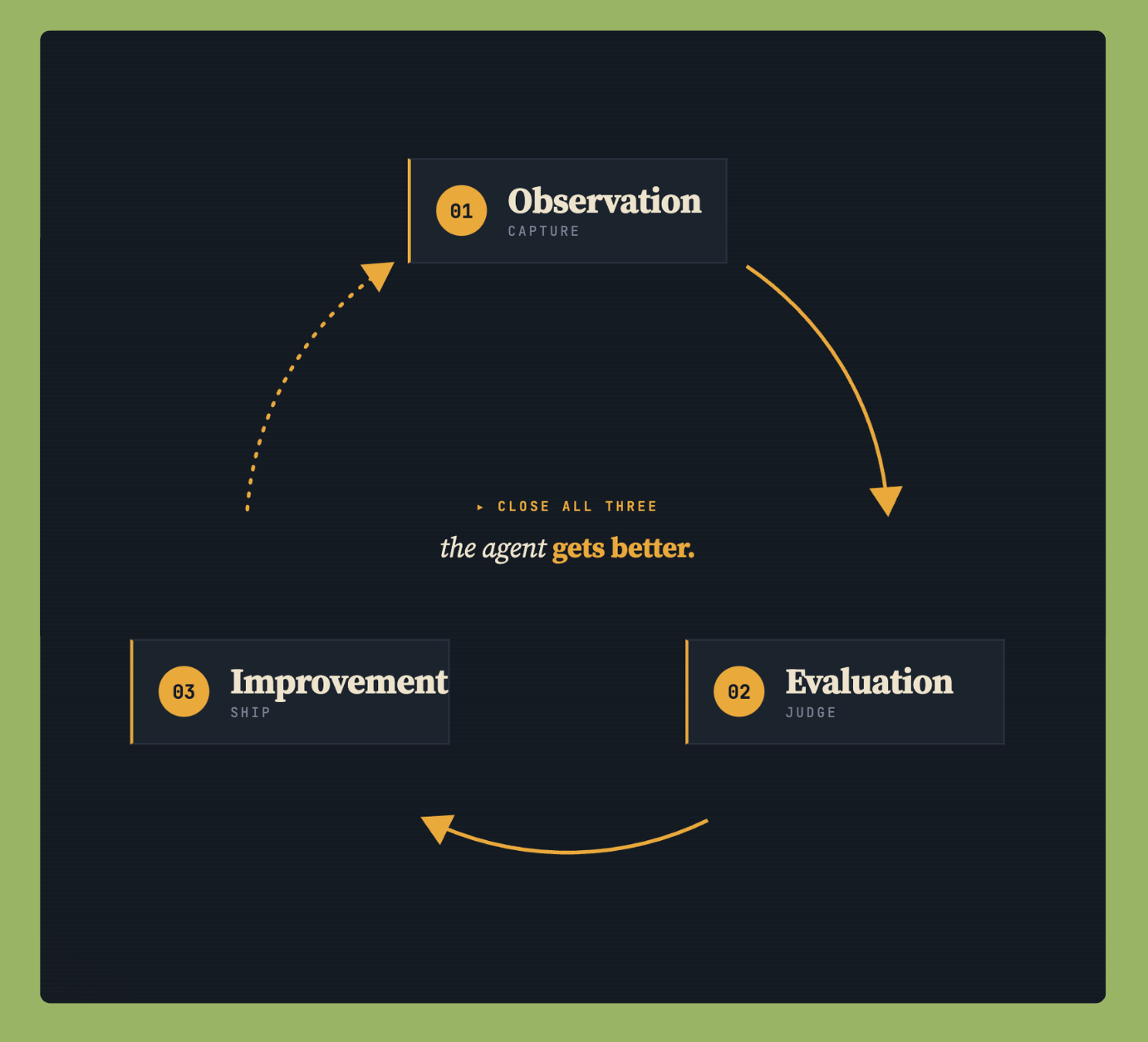
Three things have to close on each other for a production agent to actually improve.
Observation: Where you capture what the agent is doing one decision at a time.
Evaluation: Where you judge whether those decisions were right, against criteria that come from your product.
Improvement: This is where you ship a targeted, verified change back into the running agent.
When all three close, the agent gets better. When any one of them is missing, the other two run in vain.
This is now becoming a named discipline. Anthropic recently stood up a team called AI Reliability Engineering, led by Todd Underwood. He spent fifteen years leading machine learning site reliability at Google. He then ran reliability for the research platform at OpenAI. He also co-wrote Reliable Machine Learning, which is the closest thing the field has to a playbook on the topic. The thing to notice is that the industry now treats agent reliability as engineering, not as a property of the model.
Three Places the Loop Breaks
Three patterns come up over and over. Each one breaks the loop at a different stage, and each one looks like progress while it is happening.
Breakage 1: Observability Treated as Logging.
The team adds latency dashboards, error counters, and token-cost graphs, and then declares observability done. The numbers all look healthy. The agent itself is running through decisions that none of those numbers capture, because none of them are at the level of decisions. The dashboards looked fine in the Kiro incident from earlier while the agent was deleting a production environment. Infrastructure observability is not the same as agent observability. Treating them as the same thing is the first place the loop breaks.
Breakage 2: Evaluation Treated as a One-Time Benchmark.
The team builds a golden test set before launch, runs the system against it, and ships when the scores look good. A December 2025 paper by Akshathala and team, titled Beyond Task Completion, argues that pass-or-fail metrics miss what actually breaks production agents. Agents do not always behave the same way twice. The small choices they make along the way can look fine on their own. Those choices then add up to broken outcomes. A team that ships an eval suite at launch and never refreshes it is measuring last year’s agent against this year’s failures.
Breakage 3: Improvement Treated as Guess and Redeploy.
Someone on the team ships a new prompt, watches the next set of outputs, decides things look better, and merges the change. But the prompt doesn’t perform well as intended. Now, the team has no causal link back to the production trace that revealed the original problem because there are already so many components, such as tool calls and memory. They also have no measurement showing where the change actually improved anything. The next regression then looks like a brand-new bug rather than a known one.
What Each Stage Actually Requires
Observe: Real agent observability captures decisions at the span level. That means each model call, each tool call, and each branching choice the agent makes.

It also means the inputs that lead to each choice. Infrastructure spans are not the same thing. An HTTP request that took 200 milliseconds and returned a 200 status code tells you nothing about whether the decision inside the request was right. A model call with bad output looks identical to one with good output from the outside.
A May 2026 paper by Madvil and colleagues, Holistic Evaluation and Failure Diagnosis of AI Agents, puts it in one line worth quoting: “Evaluation methodology, not model capability, is the bottleneck.” Their framework scored each step in a production run, not just the final answer. It produced up to a 38 percent improvement over older approaches. For more on this distinction, see why monitoring is not observability for agents.
Evaluate: Real evaluation comes from your production traces, not from a generic benchmark catalog. The reason is simple. A generic benchmark measures the failures that the benchmark designer thought to test for.
Your customers hit the failures specific to how they actually use your product. The Beyond Task Completion paper from earlier proposes a framework with four pillars: the model itself, the memory it uses, the tools it calls, and the environment it runs in. Each pillar needs criteria specific to your product. A team building an agent for healthcare claims will care about a different set of behaviors than a team building one for code review. The underlying model can be the same in both cases. Eval criteria for an agent are not the same as eval criteria for a model. For a deeper look, see why agent evaluation is a different problem.
Improve: A real improvement is a change you can trace back to a measured failure and forward to a measured outcome. It is not “we shipped a new prompt, and the team felt better about it.” The link goes both ways:
Every change connects back to a specific production trace that exposed a specific failure.
The team then checks every change against the eval criteria from the previous stage to confirm the failure pattern has actually gone away.
Without that two-way link, the team is shipping changes with no idea whether they are improvements or regressions in disguise. Anthropic itself does not ship its production agents as one big system. In April 2026, the company announced a three-agent harness for long-running work. The feedback paths between agents are part of the design from the start. That design choice is the improved stage in production form.
The Compounding Effect
When all three stages close on each other, the improvement compounds. Sierra published its tau-knowledge benchmark in March 2026. The leading model passed only 25.5 percent of tasks on the first attempt. By May, after Sierra had tested eleven frontier model variants and teams had iterated against the benchmark, the best score reached 37.4 percent. That delta came from two months of closed-loop work on a public benchmark. In a real product, the same kind of delta is the failure pattern that your customers stop hitting.
Architecting the Loop
The default move is to build the loop in the wrong order. The team starts with improvement. Tuning prompts and trying out new techniques feels like the work a smart team should be doing. Then they realize they cannot tell whether anything actually improved, so they add an evaluation. Then they realize the evaluation has nothing to look at, so they add observability last. By that point, the team has been firefighting for months.
The order that actually compounds is the reverse:
Observability first: You cannot evaluate what you cannot see.
Evaluation second: You cannot improve what you cannot measure.
Improvement last: The work compounds once the other two stages feed it.
That sequence is the entire Day 1 framework.
Closing
Production agents do not improve on their own. They run, day after day, on the same prompts that shipped at launch.
One thing I would like to share is that a “writing prompt for an agentic workflow is like coding a transformer layer by layer.”
The teams whose agents actually compound are the teams that built the loop and kept it closed. The work in front of you is not “make the model smarter.” It is “find where your loop breaks and close it.” If you cannot identify the stage where the loop breaks in your system, your loop is open at all three stages.
The observability-first order is the part I would carry into clinical workflows. For an OR readiness agent, a useful trace would need to show which fact it checked, which mismatch it flagged, what human review point it reached, and whether the next case actually saw fewer readiness defects. Otherwise the loop can look closed while the room still absorbs the failure.
Infrastructure metrics looked normal the whole time Kiro was failing. That's the real problem. The evaluation surface didn't match what the agent was actually doing.
Benchmarks score single outputs against known answers, but production agents run decision chains against shifting contexts. Those are different measurement regimes, and instruments built for one miss the other. The discipline forming around this needs evaluation infrastructure that traces decision chains at the process level, not just output scores.