
What Are Agentic LLMs? A Comprehensive Technical Guide
A practical guide to agentic LLMs, including how they work, common use cases, production risks, and what teams should evaluate before adopting them.


OpenAI's Deep Research agent represents a major leap in AI capabilities. Unlike traditional language models that generate single responses, Deep Research autonomously conducts multi-step research tasks. It searches the web, analyzes information, executes code, and produces comprehensive reports with citations. This demonstrates what agentic LLMs can accomplish when given agency to pursue goals independently.
Understanding how agentic systems work matters for product leaders and technical teams. These AI agents can transform knowledge-intensive workflows. They handle complex tasks that previously required human expertise and significant time investment.

In an agentic workflow, a human submits a query through an interface. The LLM then engages with the environment through iterative cycles. It clarifies requirements, searches files, writes code, runs tests, and refines outputs until tasks are completed successfully. This persistent, goal-directed behavior distinguishes agents from traditional AI systems.
This article covers five essential areas:
Fundamental concepts that define agentic LLMs and their architectural components
Training methodologies that enable autonomous capabilities through reinforcement learning
Tool integration frameworks for real-world API interactions
Evaluation methods for measuring agent performance and safety
Strategic implementation guidance for organizational deployment
What is an Agentic LLM?
Traditional language models function as sophisticated text predictors. They receive a prompt and generate a single response. Agentic LLMs represent a fundamental evolution beyond this passive approach.

These systems operate as autonomous AI agents. They can plan multi-step solutions, maintain context across extended interactions, and actively use external tools to accomplish complex tasks.
From Passive to Active AI
The distinction lies in persistent goal-directed behavior. Standard LLMs produce one output and stop. Agentic systems continue working until they complete their objectives.
Consider a research task. A traditional LLM might provide a summary based on training data. An agentic LLM searches the web, reads multiple sources, synthesizes findings, and produces a comprehensive report with citations.
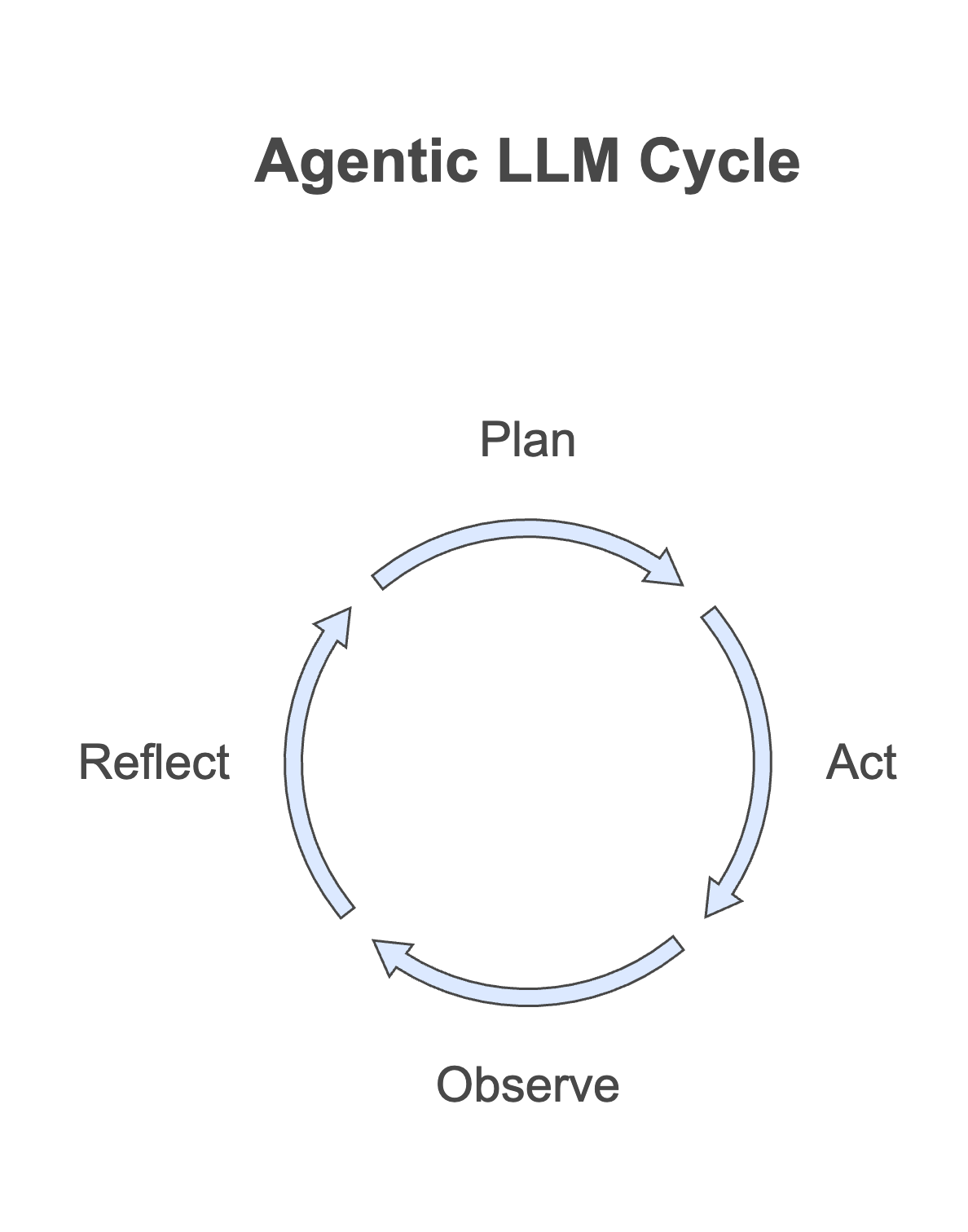
This shift requires wrapping the core language model in an orchestration framework. The framework manages the continuous cycle of planning, action, observation, and reflection.
Architectural Pillars
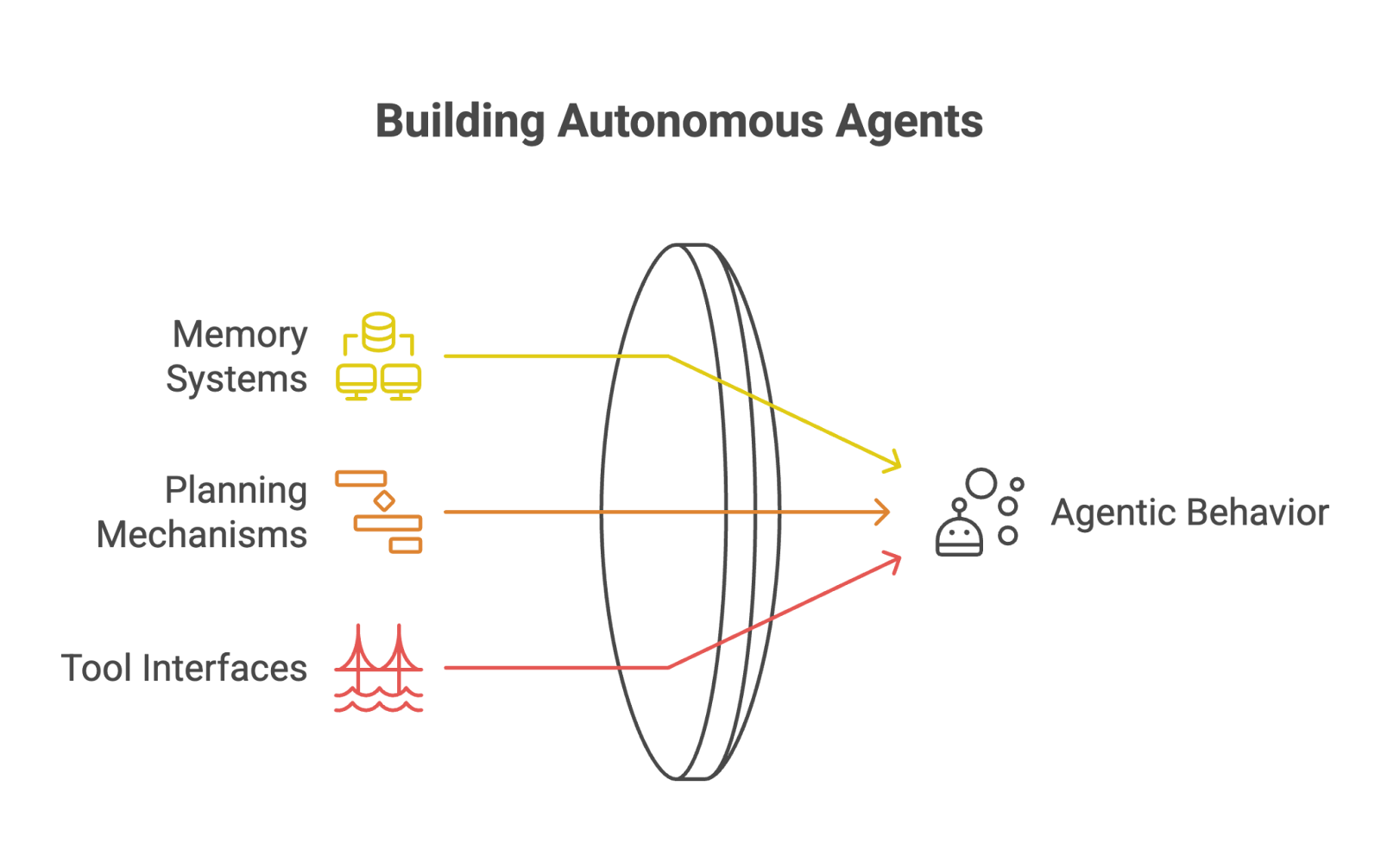
Three core components enable agentic behavior:
Memory systems that persist information beyond context windows
Planning mechanisms that break complex tasks into manageable steps
Tool interfaces that connect models to external resources
Memory comes in multiple forms. Short-term memory maintains conversation context. Long-term memory stores facts and experiences across sessions. Working memory holds intermediate results during task execution.
But, planning can be implicit or explicit. Implicit planning means the model decides each next step iteratively. Explicit planning involves formulating a complete multi-step strategy before execution.

Tool interfaces expand capabilities dramatically. Models can access calculators for precise arithmetic. They can query search engines for current information. They can execute code for complex computations.
Agency Paradigms
Reactive agents respond directly to stimuli. They map inputs to actions without internal deliberation. This approach works for simple, well-defined tasks.
Deliberative agents maintain internal models of their environment. They reason about consequences before acting. They can adjust plans based on new information or failed attempts.

Most production agentic systems use deliberative architectures. They employ chain-of-thought reasoning to think through problems step-by-step. This enables handling complex, multi-faceted challenges that require careful consideration and planning.
The combination of persistent memory, strategic planning, and tool access transforms language models from text generators into capable autonomous assistants.
Training Methodologies for Autonomous AI Agent Capabilities
Building agentic LLMs requires a sophisticated multi-stage training approach. The process transforms basic language models into autonomous systems capable of goal-directed behavior. Reinforcement learning integration represents the critical component that enables true agency.
Multi-Stage Training Pipeline
The training begins with standard pre-training on massive text corpora. Models learn fundamental language patterns and world knowledge. This foundation provides the reasoning capabilities needed for complex tasks.
Instruction tuning follows pre-training. Models learn to follow human commands through supervised fine-tuning on demonstration data. High-quality prompt-response pairs teach desired behaviors and response formats.
The final alignment phase shapes goal-directed behavior. Multiple approaches exist:
Constitutional AI uses AI feedback guided by explicit principles
RLHF leverages human preferences to train reward models
Direct Preference Optimization streamlines the preference learning process
Each method addresses the fundamental challenge of moving beyond language prediction to outcome optimization.
Reinforcement Learning Approaches

RLHF transforms the training objective from text prediction to goal achievement. The process involves three steps: collecting human preference data, training reward models, and optimizing policies using algorithms like PPO.

RLAIF replaces human feedback with AI-generated preferences. Models evaluate their own outputs against constitutional principles. This approach scales more efficiently than human annotation while maintaining alignment quality.

DPO eliminates the need for explicit reward model training. It directly optimizes model outputs to match preferences through a clever mathematical reformulation. This simplifies the training pipeline while achieving comparable results.
Agency-Specific Training Data
Agentic models require specialized datasets beyond standard text:

These datasets teach models when to use tools, how to format requests, and how to integrate results into ongoing tasks. Quality curation remains essential since poor demonstrations can teach inefficient or incorrect behaviors.
The combination of progressive training stages and specialized data creates models that can autonomously pursue goals while remaining aligned with human values and intentions.
How do AI agents use tools?
Tool integration occurs at two distinct phases in agentic LLM development. Train-time integration uses simulated environments to teach models how to use tools. Test-time integration enables real-world API interactions. OpenAI's Deep Research ChatGPT agent exemplifies sophisticated tool orchestration in production systems.
Tool Grounding During Training vs. Inference
Training phase tool use relies on controlled simulations. Models practice with mock APIs and synthetic environments. This approach allows safe exploration of tool usage patterns without external dependencies or costs.

WebGPT pioneered this methodology by training models on browsing demonstrations. The system learned navigation patterns through supervised imitation before reinforcement learning refinement. Similar approaches work for code execution and database queries.
Runtime tool integration presents different challenges. Models must handle real API latencies, errors, and unexpected responses. OpenAI's Deep Research manages these complexities through robust error handling and adaptive planning strategies.
The training-to-inference gap requires careful bridge-building. Models trained on perfect simulations must adapt to imperfect real-world conditions.
Multi-Modal Integrations and API Orchestration
Modern agentic systems integrate diverse tool categories:
Information retrieval: Web search and document access
Computation: Code execution and mathematical calculations
Communication: Email and messaging interfaces
Storage: Database and file system interactions
Deep Research demonstrates comprehensive integration. It searches the web for current information. It executes Python code for data analysis. It synthesizes findings into detailed reports with proper citations.
The orchestration layer manages tool selection and sequencing. Models output structured commands that the framework interprets and executes. Results feed back into the model’s context for continued processing.
Runtime Decision Logic and Action Management
The perception-action cycle forms the core of agentic operation. Models observe their environment, plan actions, execute tools, and evaluate results. This loop continues until task completion.
Deep Research implements sophisticated planning mechanisms. It creates research plans for user approval. It adapts strategies based on search results. It backtracks when initial approaches prove unfruitful.
Error handling remains crucial for reliable operation. Systems must gracefully handle tool failures, network timeouts, and unexpected responses. Fallback strategies ensure continued progress despite individual tool failures.
The framework also manages computational resources. It limits tool usage to prevent infinite loops. It optimizes API calls to balance thoroughness with efficiency.
How to evaluate AI agents?
Evaluating agentic AI or agentic LLMs requires moving beyond traditional language model metrics. These systems must be assessed on their ability to complete complex, multi-step tasks autonomously. Deep Research's performance on challenging benchmarks demonstrates the potential of well-designed agentic systems.
Task Success Metrics and Efficiency Measurements
Primary evaluation focuses on task completion rates. Did the agent achieve the desired outcome? This binary success metric provides the clearest performance indicator.
Efficiency metrics add crucial context to success rates:
Step count: Number of actions required to complete tasks
Tool usage: Frequency and appropriateness of API calls
Time to completion: Duration from start to finish
Resource consumption: Computational costs per task
Deep Research achieved 26.6% accuracy on Humanity's Last Exam, a significant improvement over previous models. This benchmark tests expert-level knowledge across diverse domains. The results validate sophisticated reasoning and information synthesis capabilities.
Consistency measurements reveal model reliability. Running identical tasks multiple times exposes variance in agent behavior. Reliable systems produce similar outcomes across repeated trials.
Specialized Benchmark Environments

WebArena creates realistic web interaction scenarios. Agents must navigate websites, fill forms, and extract information. Tasks span e-commerce, forums, and content management systems. Success requires understanding web page structure and completing multi-step workflows.

SWE-Bench evaluates coding capabilities through real software engineering challenges. Agents must read issue descriptions, examine codebases, implement fixes, and pass unit tests. This benchmark tests programming skills alongside problem-solving abilities.
These environments provide controlled testing conditions while maintaining real-world complexity. They enable fair comparisons between different agentic approaches.
Safety, Alignment, and Robustness Assessment

Safety evaluation examines harmful output generation and refusal behaviors. Models should decline dangerous requests while remaining helpful for legitimate tasks. Adversarial testing exposes potential misuse vulnerabilities.
Hallucination assessment becomes critical for agentic systems. Deep Research significantly reduces factual errors compared to standard models. Citation verification ensures claims link to legitimate sources.
Alignment evaluation measures adherence to user intent. Does the agent pursue the intended goal? Does it respect implicit constraints and values? These assessments often require human judgment to evaluate nuanced behaviors.
Robustness testing introduces variations in task formulation and environmental conditions. Reliable agents maintain performance despite minor changes in input phrasing or tool availability.
Evaluating AI Agents in 2025

OpenAI's Deep Research represents a new wave of AI agents designed to navigate complex information landscapes. Deep Research is different from earlier systems. It doesn't just respond to prompts. Instead, it searches the web by itself. It finds relevant facts and puts them together into clear answers. This tool stands out because of its persistence. It …
Strategic Implementation Guide for Product Leaders
Implementing agentic LLMs requires strategic planning beyond technical deployment. Organizations must identify optimal use cases, plan resources effectively, and manage change thoughtfully. Practical deployment considerations determine whether these powerful systems deliver meaningful business value.
Use Case Identification and Prioritization
Start with knowledge-intensive processes that have clear success metrics. Research synthesis represents an ideal initial target. Teams spend significant time gathering information from multiple sources. Agentic systems can automate this workflow while maintaining quality standards.
Competitive analysis offers another high-value opportunity. Agents can monitor competitor activities, synthesize market intelligence, and generate actionable insights. Documentation generation provides measurable time savings with immediate user feedback.
Prioritization framework for agentic implementation:

ROI Framework and Resource Planning
Develop tiered implementation strategies that balance capabilities with costs. Reserve expensive operations for high-value tasks. Use simpler implementations for routine work.
Cost considerations include direct expenses and indirect benefits:
Direct costs: API usage, computing resources, platform fees
Indirect benefits: Time savings, quality improvements, employee satisfaction
Opportunity costs: Alternative investment options, delayed implementation risks
Build comprehensive business cases that capture both quantitative savings and qualitative improvements. Time-to-value metrics help justify initial investments.
Organizational Readiness and Change Management
Form cross-functional teams combining domain expertise with technical implementation skills. Include governance specialists to address compliance and risk concerns. This diverse perspective ensures comprehensive planning.
Create structured feedback loops between users and development teams. Regular input sessions help identify improvement opportunities and address user concerns promptly.
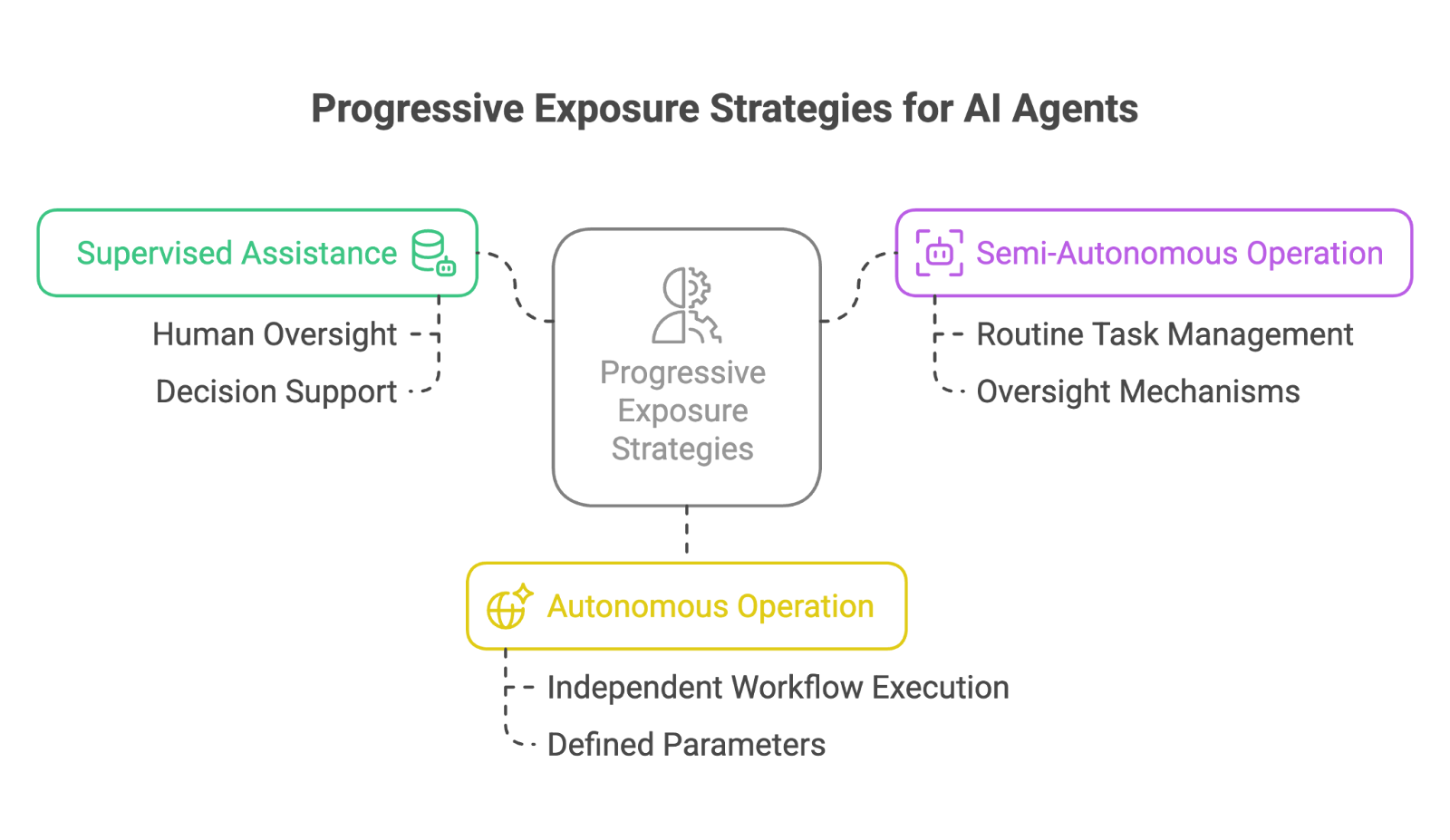
Implement progressive exposure strategies:
Supervised assistance: Agents support human decision-making
Semi-autonomous operation: Agents handle routine tasks with oversight
Autonomous operation: Agents work independently on defined workflows
This gradual approach builds user confidence while identifying potential issues before full deployment.
Conclusion
Agentic LLMs represent a fundamental shift from passive text generation to autonomous task execution. These systems combine memory, planning, and tool integration to tackle complex, multi-step challenges. Unlike traditional models that produce single responses, agentic systems persist until they complete their objectives.

The transformation requires sophisticated training methodologies. Multi-stage pipelines progress from basic language understanding to goal-directed behavior. Reinforcement learning techniques enable models to optimize for outcomes rather than just text prediction.
Product leaders must understand these capabilities to identify implementation opportunities. Key implementation considerations include:
Starting with knowledge-intensive workflows that have clear success metrics
Developing tiered approaches that balance capability with cost
Building cross-functional teams for effective change management
Establishing progressive exposure strategies from supervised to autonomous operation
Proper evaluation frameworks measure task success, efficiency, and safety. Specialized benchmarks like WebArena and SWE-Bench reveal how well agents handle real-world scenarios.
The strategic advantage lies in recognizing where autonomous capabilities can transform existing workflows. Organizations that thoughtfully implement these systems will gain significant competitive advantages in knowledge work and decision-making processes.
Start by evaluating your current workflows to identify where agentic capabilities could deliver immediate value.