
What PMs Need to Know About Transformers
A small essay on why on transformers are irreplaceable.


Today I wanted to write something more technical and basic. Something that is at the core of all the products, assuming you are using AI or LLM to conduct your research, develop products, or for prototyping.
I want to write about the transformers. The heart of any modern-day AI or LLM.
The transformers have been around for about 8 years now. The initial research and paper was published in 2017, titled “Attention is all you need” by Vaswani A and his team. In that paper, they proposed a new paradigm for processing an input sequence that used the scaled dot product. This is called scaled dot product attention.
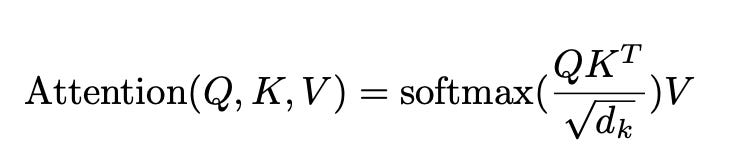
Here, the model forms three learned views of the same input. Each copy signifies the following:
Query: What am I looking for?
Key: What information do I have?
Value: What's the actual content?
Now, to find out which value or word in the input sequence is more valuable, you compute the dot product of Q and K. This gives the attention score. The attention score is then divided by √dₖ to stabilize gradients, which prevents the attention score from getting too big. That’s the scaling factor.
And to get the probability distribution that sums to 1, the softmax function is used. This tells which word in the sequence has more importance, focus, or attention.
The final result is used to take a weighted sum of V. This is important because the attention score, including the calculated probability, is now applied to the actual content or information.
Understanding this mechanism can help us write better prompts. You should structure the prompts to be clear about what you're asking for (the query) and provide relevant context (the keys), so the model can better focus on the important information (values) in your input.
Now, the attention mechanism is at the core of all transformers.
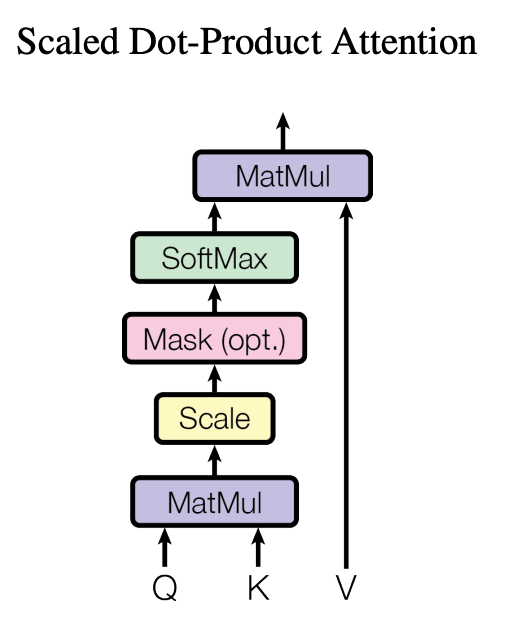
The advantage of this simple approach is that it is easier to scale. To do that, you just need to layer scaled-dot product attention in parallel.
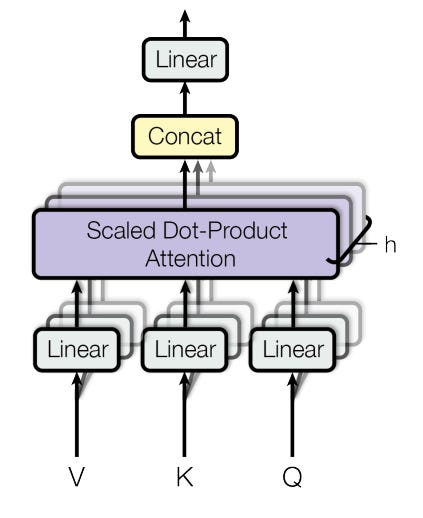
This way, you get a multi-head attention mechanism.
The multi-head attention allows parallel processing of the input or prompt. Each head will focus on a different aspect of the prompt. This allows for the extraction of more information at the nuance level for better clarity and results.
The final result is concatenated and processed further.
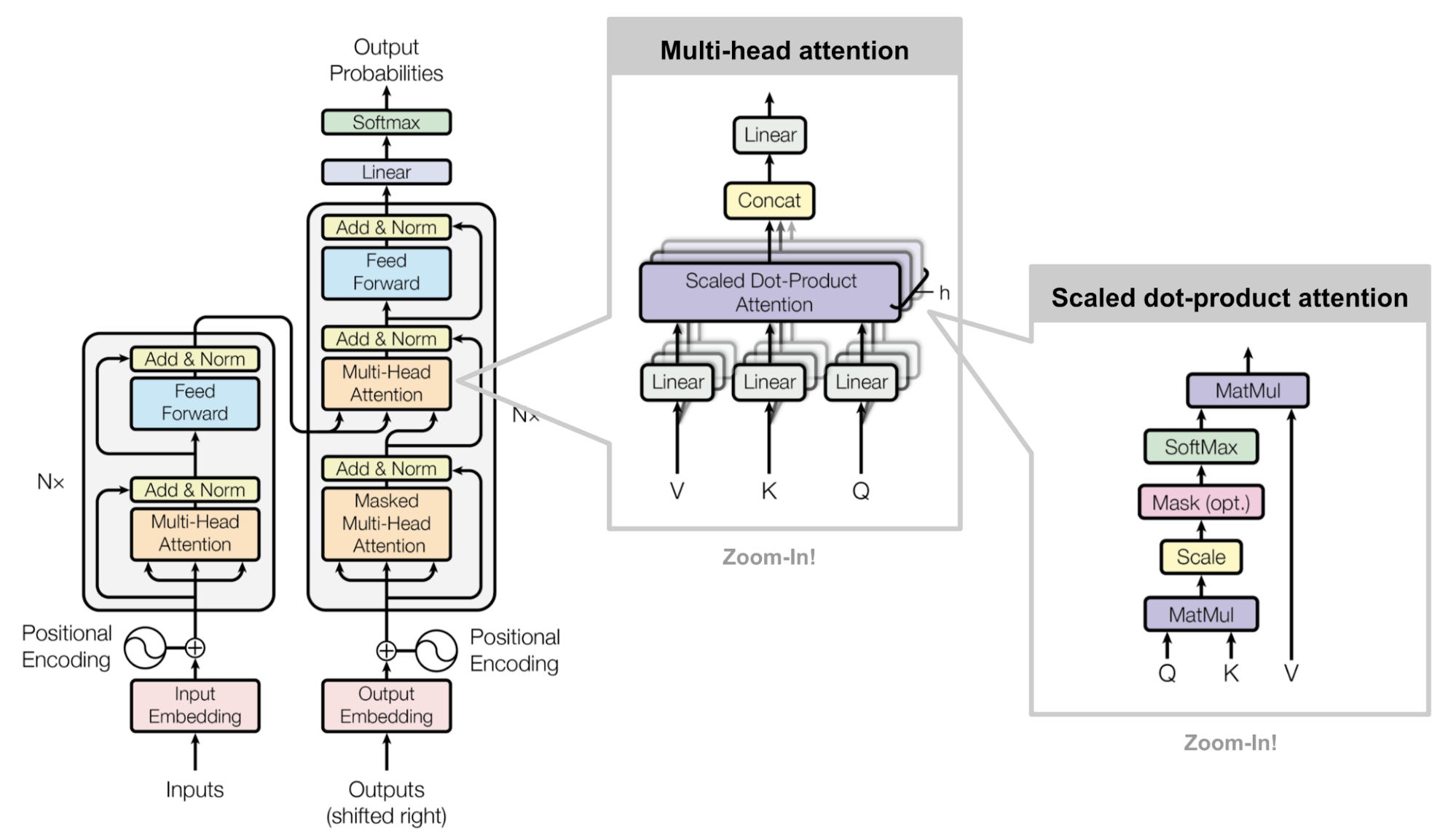
The attention mechanism is the reason why modern AI can understand context so well.
3 Reasons Why Transformers Won
The transformers are widely adopted at the product level. One way to see it is that the transformers act as a brain, and the UI or API is a package that caters to the users.
Almost every major lab has built its LLMs and products over the transformer architecture.
OpenAI: GPT-4o, GPT-4.1, GPT-4.5, GPT-o4-mini, GPT-o3, GPT-o3-mini, GPT-o1
Google DeepMind: Gemini (Ultra, Pro, Flash, Nano, 2.0, 2.5 Pro, 2.0 Flash-Lite), Gemma (1B-27B), PaLM (Pathways Language Model)
Meta: Llama 3.1 (405B), Llama 2
Anthropic: Claude 3.5 Sonnet, Claude 3.7 Sonnet
xAI: Grok-1, Grok-2, Grok-3
Mistral AI: Mistral Large 2, Mixtral 8x22B, Mistral 7B
Alibaba: Qwen 3, Qwen 2.5-Max
DeepSeek: DeepSeek R1, DeepSeek-V3, DeepSeek-V2.5
But why?
Here are some reasons why:
Parallelism
Global context
Scales well
Parallelism
Before transformers, RNNs operated one token at a time from first to last, which prevented them from being parallelized on GPUs. Transformers eliminated this bottleneck by processing entire sequences simultaneously rather than in a serialized manner, enabling them to take full advantage of GPU power during both training and inference.
This parallel processing significantly reduces training time by processing data concurrently across multiple GPUs, making it scalable to the number of available devices.
The 2017 breakthrough allowed researchers to train massive models efficiently, breaking free from the sequential constraints that limited earlier architectures.
Global context
At each layer, tokens are contextualized within the scope of the entire context window through parallel multi-head attention. This allows key tokens to be amplified and less important ones to be diminished.
Unlike RNNs that struggle with long-range dependencies due to sequential processing, attention mechanisms can examine entire sequences simultaneously and make decisions about relationships between distant parts. This enables models to capture long-range dependencies, analyze both local and global contexts simultaneously, and resolve ambiguities by attending to informative parts regardless of distance.
Multi-head attention provides multiple “views” of the sequence, giving transformers superior contextual understanding compared to architectures limited by vanishing gradients.
Scales well
Transformers scale well. You easily increase the number of heads, embedding dimension, and whatnot. Essentially, the size of the transformer in both the width and depth.
The research reveals that transformer performance follows predictable power-law relationships with model size, dataset size, and compute budget. Larger models are significantly more sample-efficient, reaching the same performance levels with fewer optimization steps and using fewer data points than smaller models.
Larger models also show emergent capabilities. Meaning, new capabilities and qualities emerge as the models are scaled up.
This is the reason why today all the labs are aiming to scale the transformer by also incorporating methods from Reinforcement Learning.
Because labs were constantly competing and crushing benchmarks, transformers became widely acceptable and efficient to modify. Meaning all you need to do is tweak a bit and change any one component. Maybe add a Mixture of Experts with fewer and denser experts or more and shallower experts.
One differentiating example that I could think of is GPT-oss and Qwen3. The former has wider architecture as it uses a larger embedding dimension than the latter. While the latter has deeper architecture, as it uses more transformer blocks than the former.
From Chat to Agents
When ChatGPT was launched on 30 November 2022, it was a simple language model that would take the input, process it, and give the output. It was fancy, though.
People started using it to write blogs, generate stories, and even code. Although none of them were perfect but this gave a direction for LLM research and development to move forward. That is, provide a UI over a powerful LLM and give it to the users, and let them use it in whatever way.
ChatGPT was based on GPT-3.5 turbo, which was finetuned to follow instructions or, essentially, instruction-tuning techniques like RLHF and sophisticated training techniques. The prior models were just text completion models that only generated text from the users’ input. But GPT-3.5 turbo was a conversational model that answered your questions.
Most of the models that were released after that were doing the same thing but better. The idea was to scale these models so that more data can be compressed. More data means more knowledge, which equals more intelligence.
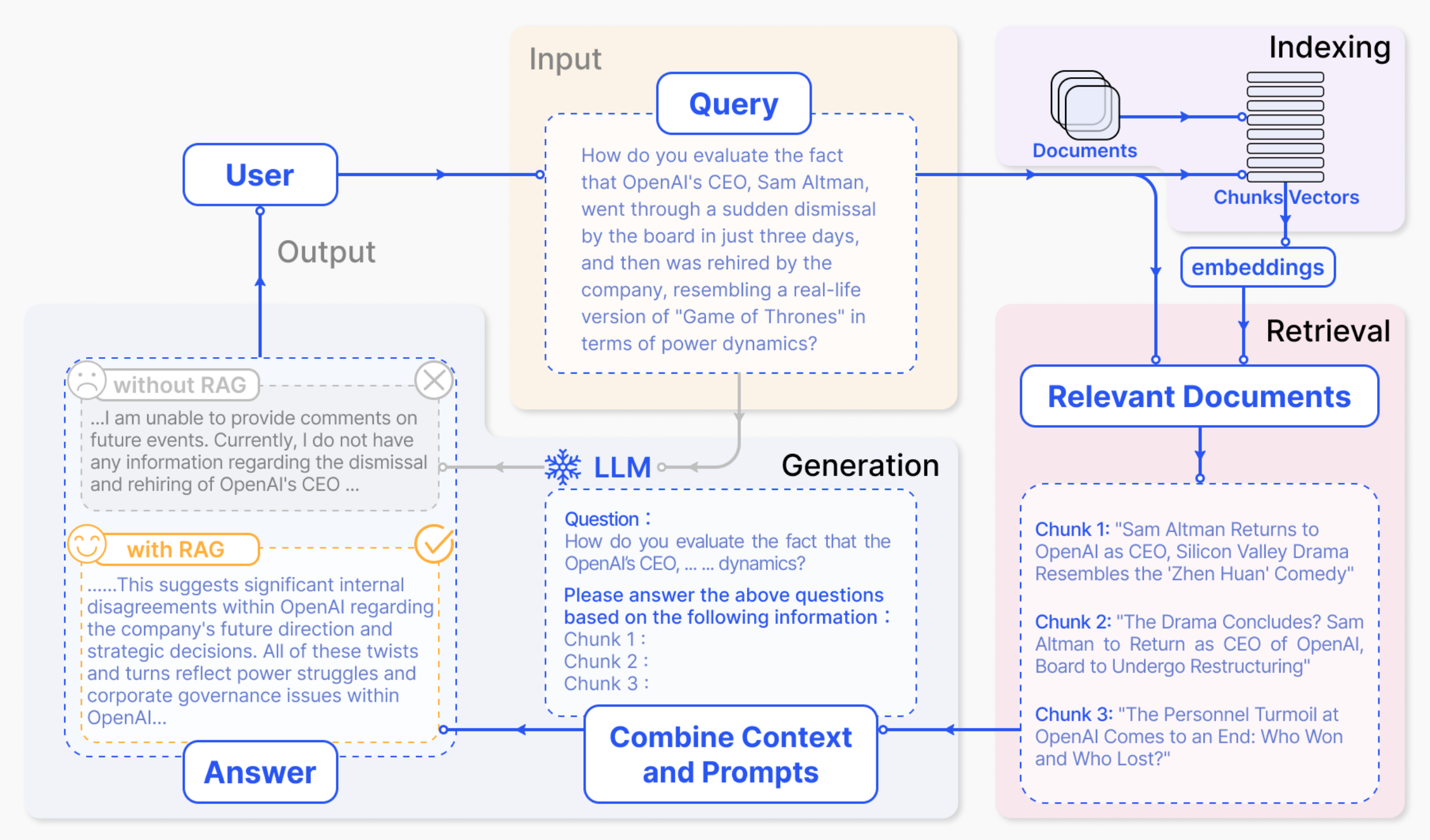
Methods like RAGs were introduced to retrieve data from the knowledge databases to reduce the model’s hallucinations and make it more grounded and factual. And these models started doing well on various benchmarks. But still, they were not as capable as human intelligence in solving hard math problems. Something was missing, and that was reasoning. They still couldn’t produce output with proper thinking, planning, and acting in the environment.
In September 2024, OpenAI publicly launched its “o1” model. This model uses test-time compute to think longer by generating multiple chains of thought reasoning during inference. Although the model took much longer to provide the response, it started doing well on complex math problems.
The first quarter of 2025 was the year of reasoning models, and by the third quarter, agentic capabilities started to make headlines. This is where multiple agents work in parallel to get the job done.

This turned out to be a major tool that developers and product builders are using on a regular basis. Whenever a prompt is given to the model creates an iterative loop to think, plan, reflect, and act until it derives the correct response.
What Are Agentic LLMs? A Comprehensive Technical Guide

OpenAI's Deep Research agent represents a major leap in AI capabilities. Unlike traditional language models that generate single responses, Deep Research autonomously conducts multi-step research tasks. It searches the web, analyzes information, executes code, and produces comprehensive reports with citations. This demonstrates what agentic LLMs can acc…
Cost, Latency, Context
Early LLM-based products and workflows were largely prone to hallucination. To mitigate that, RAGs were used. Here, the LLMs were provided with an external database to retrieve information from. These databases are used to store information as vectors. Pinecone is one of the great examples. RAGs were cheap, and they would retrieve most of the information. They were efficient for a lot of enterprise-level workloads, chatbots, coding assistants, etc.
Then, a tool-using agent came to the scene around 2023-2024. Based on the prompt, the LLM would output a structured JSON response or function to fetch information or perform an action.
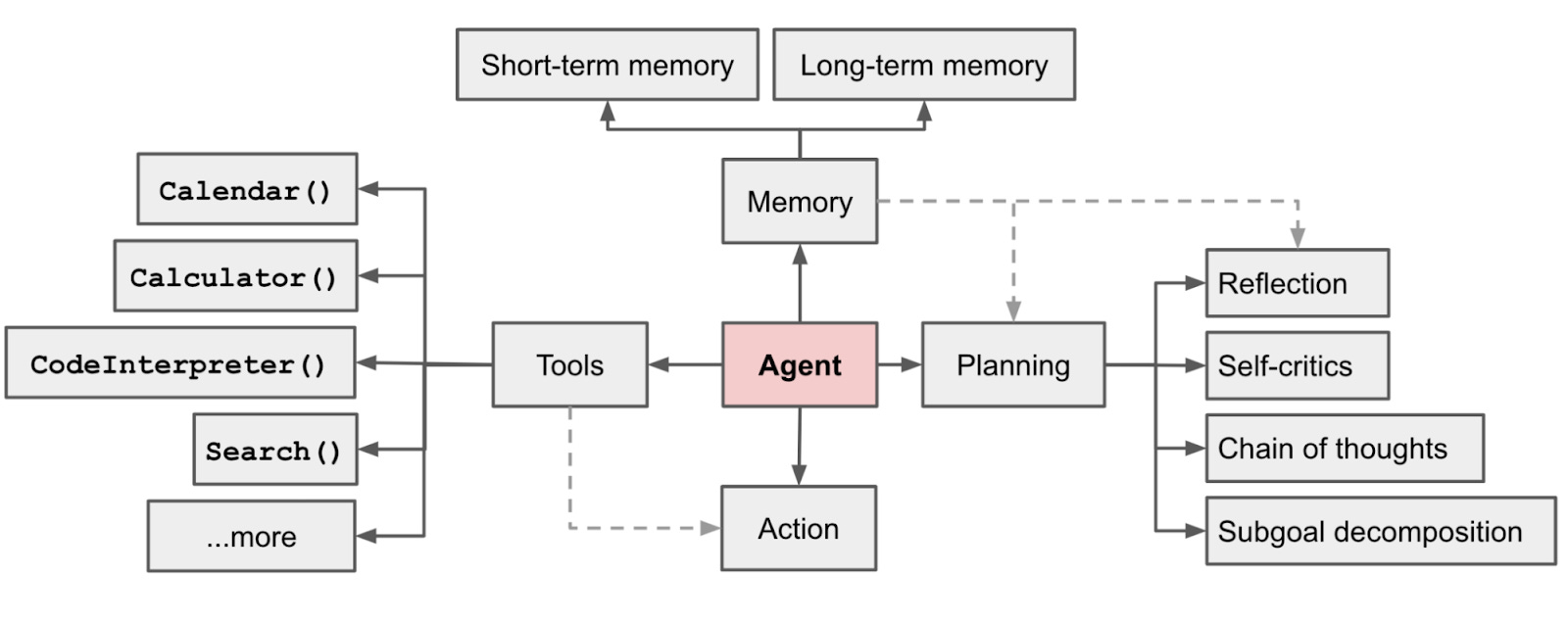
This workflow enabled LLM to be an assistant.
We now have reasoning models that use tools to handle a lot of complex tasks.
But such innovation comes at a heavy cost. The inference time has increased because the model now generates tokens for thinking, tool-calling, planning, reflection, and finally the output. The cost of running these agentic models has risen.
There are major changes that have been made to the architecture to reduce the training and inference costs as much as possible. For example, instead of using a multihead attention mechanism, group query attention (GQA) is used.
In GQA, the query information is grouped together. This reduces memory usage and makes the transformers more efficient without compromising much on the performance.
Other notable architectural improvements are:
Rotary Positional Embeddings (RoPE): RoPE ditched the old sinusoidal position encodings. Instead, it weaves position data directly into the attention mechanism itself. This breakthrough lets transformers process massive context windows, sometimes millions of tokens, with much better accuracy than before.
Pre-Layer Normalization and RMSNorm: Moving normalization to the front of each layer changed everything for deep models. Pre-LN keeps training stable even when models hit trillion-parameter scales. It stops gradients from exploding or vanishing as networks get deeper.
Grouped-Query and Slim Attention: These attention variants split up query processing for better efficiency. They cut down the quadratic scaling problem that plagued standard attention. Memory usage drops significantly, crucial for massive models like GPT-4 and Gemini.
FlashAttention: This optimization works at the hardware level, using GPU shared memory smarter. It eliminates redundant data shuffling during attention computation. The result? Long sequences train and run efficiently without needing more hardware.
Mixture-of-Experts (MoE): Modern transformers route different tokens to specialized expert networks. Only a few experts activate per token, not the whole model. This approach scales up capacity while keeping compute costs reasonable.
Efficient Data Packing and Minimal Padding: Current models pack sequences dynamically to avoid wasted computation from padding. They handle multiple documents in batches without the old inefficiencies. Every token gets processed meaningfully.
Residual Connections & Deep Scaling: Deep residual paths ensure gradients flow smoothly through hundreds of layers. This stability enables much wider and deeper architectures. Better representations emerge from these expanded models.
What’s Next: Hybrids, Longer Horizons, and On-Device
The next step is a hybrid design. Teams are pairing transformers with state space models for steadier long-range memory. Mixture-of-Experts stays central because it adds capacity without scaling every token. New routing ideas, like a chain of experts, push tokens through multiple specialists in sequence. The goal stays the same. Plan longer. Think deeper. Spend less.
Context windows will keep growing. A million tokens is useful, but it is not free. Cost and latency rise with length. Use a hybrid memory plan. Let RAGs carry most knowledge. Save long context for contracts, support threads, or large codebases that truly need a full view. Summarize often. Keep episodic notes in the session. Keep semantic facts in a store.
On-device is next for privacy and speed. Smaller, quantized models will run on laptops and phones. They answer questions easily locally and work offline. Hard steps escalate to a larger teacher in the cloud.
Plan for both paths. Ship a split pipeline. Measure where tokens, time, and errors pile up. Fix the bottleneck that moves your product metric.