
AI Alignment Isn't Academic Theory—It's Your Product's Biggest Risk
How misaligned AI is costing you users, revenue, and trust (and 6 proven ways to fix it)


In my previous article, I discussed how a superintelligent AI can help us build holistic products. I laid out the general timeline that can lead us to AI superintelligence and the role of reinforcement learning (RL) as a main algorithm to build a superintelligent AI. Apart from that, I also emphasized the importance of domain knowledge and users’ requirements which can help us to provide the right context to the AI. And, without these, we cannot expect to build holistic products for our customers.

In short, “If we manage to develop a superintelligent AI, then our products will have a holistic understanding of what humans prefer, and it will be aligned with our emotions and goals, leveraging scientific creativity, general wisdom, and social skills.”
However, we still need to resolve the alignment issue. It is one of the most important concepts that is often overlooked and not given much attention (except by those who are building the AI systems).
In this article, I would like to shed some light on why alignment remains one of the most difficult engineering problems, and how solving it would help us to develop better products.
Now, to understand the alignment issue, we need to know the training/development pipeline of an LLM.
The Development Pipeline of LLM
Pretraining
The base model LLM (with a transformer architecture) is trained on a large corpus of internet data. This allows the LLM to predict the next word or token in sequence. This is an important task because it allows the model to capture the pattern of data and learns its underlying representation.
Fine-tuning or instruction tuning
In the fine-tuning stage, the model is trained on the task-specific data. This would include a question-answer pair or a prompt-output pair. This data is small compared to the pretraining data. Here, the idea is to let the model generate or predict answers based on the question.
However, when it comes to training reasoning models, such as “o3”, they are trained on a chain-of-thought (CoT) dataset. This dataset consists of a question, a CoT, and the corresponding answer. The CoT has a step-by-step implementation of the complex problem, essentially outlining the logic or reasoning steps that lead to the correct or probable answer.
The LLM is Not Ready Yet
Once the model is trained, it can now generate output based on the questions you ask.
The LLM at this point has become a system that has,
Captured all the information that it has received. In other words, it has compressed all the available world’s [text] data from the internet from all domains.
Learned the probability distribution to place the right word in the right order and form a meaning.
Learned to answer questions.
Assuming the model has been trained extremely well, it can now answer any question, whether or not it is an expert in the field.
And it is not safe.
It can answer the question without any ethical considerations. It can be biased. It can even be harmful, deceitful, and hallucinatory.
This is the reason why we need to align the models with human preferences. It makes the model safe to use that adheres with ethical concerns, safety, truthfulness, etc.
Post Training: Alignment using Reinforcement Learning
To align the model with human preference, RL is used.
In short, a method such as Reinforcement Learning from Human Feedback, or RLHF, is used. Another method employed after RLHF is Reinforcement Learning from Verifier Rewards, or RLVR.
Now, RL has three important components:
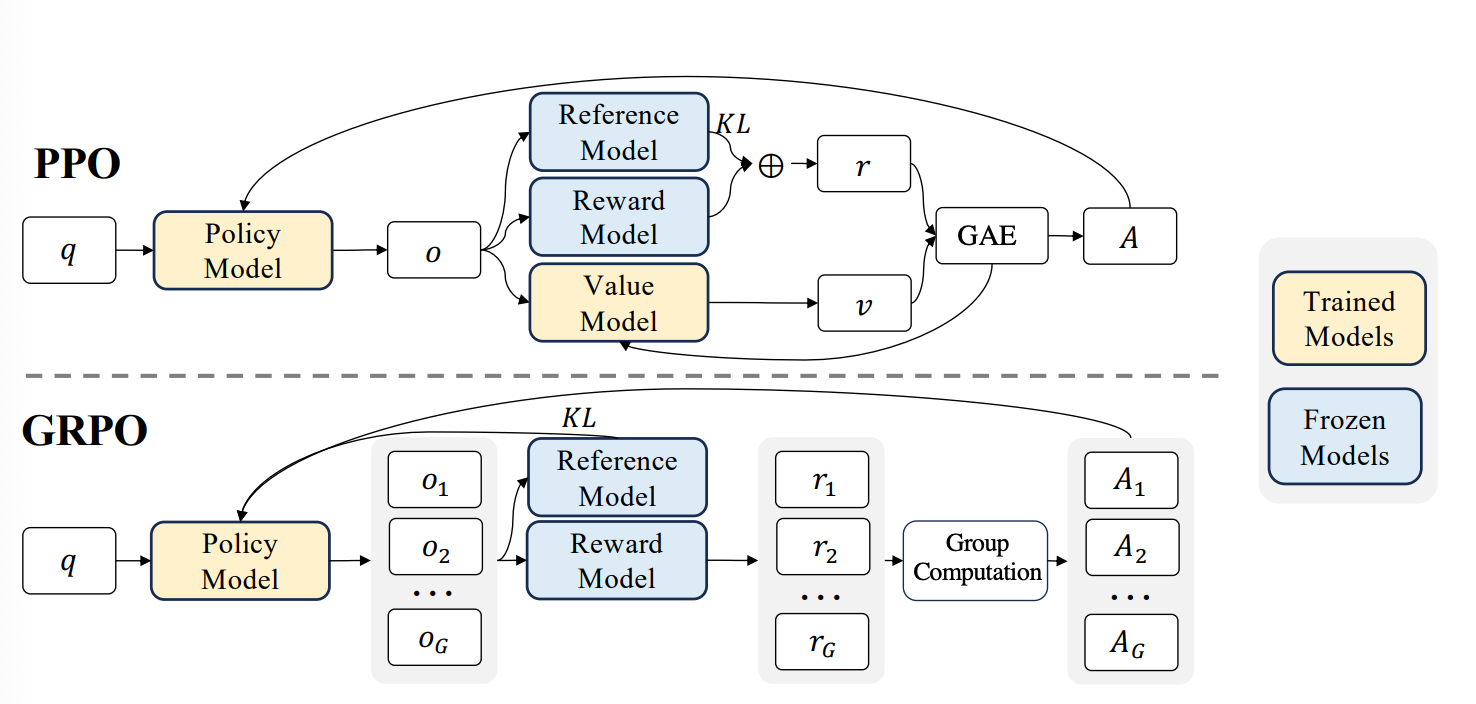
Agent: It is the learner or the neural net. In our case, it will be the LLM. To be more thorough, the Agent consists of 3 models:
Policy model: It is the LLM that is fine-tuned and the one that will be optimized.
Reference model: It is a duplicate of the fine-tuned model with frozen weights that will be used to optimize the policy model.
Value model, which estimates average reward.
Environment: It is the interaction that the LLM makes with the world. Essentially, everything external like prompts, instructions, context, APIs, data, or RAG, etc.
Actions: They are the output generated by the agent. The outputs are influenced by the environment.
Preference-Tuning with RLHF
RLHF is generally used to align the model with human preference. Here, the fine-tuned LLM is used to generate multiple answers from the same prompt.
The human reviewer, then, rates each of the answers and creates a dataset.
This dataset is used to train a reward model (RM). Essentially, it is now aligned with human morality of what type of response is best and what kind is worst.
Once the RM is trained, it is then used to evaluate the response of the fine-tuned LLM. RM evaluates LLM response for every prompt and provides a reward signal.
The reward signal is then used to update the LLM using algorithms like PPO or GRPO.
Reinforcement Fine-tuning from RLVR
In RLVR, the goal is to verify the output from the LLM and then reward it. This methodology eliminates the human-in-the-loop approach and is much more efficient. Consequently, it eliminates RM altogether where humans were required to manually annotate data.
The important thing to remember is that you need to have “Verifier’s law” to evaluate the models.
I read a recent blog titled “Asymmetry of verification and verifier’s law” by Jason Wei. He defines Verifier’s law as,
“The ease of training AI to solve a task is proportional to how verifiable the task is. All tasks that are possible to solve and easy to verify will be solved by AI.”
When training “Large Reasoning Models,” RLVR is very crucial. Especially in tasks like math problems or code generation, where answers can be programmatically verified.
It is true that some tasks are better verified than solved, especially cognitive challenging tasks like math, coding, and developing a new feature with user preferences in mind.
You can write Verifier’s Law using hardcoded functions, use API, or even incorporate rubrics.
The Alignment Issue
Although we have made significant progress in utilizing large reasoning models for cognitively challenging tasks, there is still much to be done.
Sam Altman wrote in his essay title “The Gentle Singularity” that, solving the alignment problem means,
“…that we can robustly guarantee that we get AI systems to learn and act towards what we collectively really want over the long-term (social media feeds are an example of misaligned AI; the algorithms that power those are incredible at getting you to keep scrolling and clearly understand your short-term preferences, but they do so by exploiting something in your brain that overrides your long-term preference).”
The AI that we are currently using is great, but we cannot rely on all the responses that it generates. There is still a gap between what we want and what AI truly understands.
Another interesting paper that I came across was from the Anthropic alignment team. They revealed that the Large Reasoning Models yield inaccurate outputs when given too much time to think. This essentially means that,
Models can get distracted by trying to process a huge amount of information that they collect from online searches, APIs, and context we provide.
They also overfit to frame problems or user queries in the first place.
They also misalign themselves with the prior knowledge to make invalid correlations just to achieve longer and parallel CoT.
They couldn’t focus on the task at hand. They try to solve multiple problems and figure out which path or problem leads to the correct answer.
Extended reasoning or producing multiple and parallel CoT can amplify the alignment issue.
The paper suggested that the test-time compute scaling is a promising endeavor because it leads to emergent behavior, but that “it may inadvertently reinforce problematic reasoning patterns”.

Perfecting the Alignment Issue
The alignment issue is not going away any time soon. Maybe it will not go away for a long time.
But the good news is that the major labs are iterating their AI quite rapidly. Significant progress is being made to align the model with human preferences and safety.
When things take a wrong turn, like we saw before the release of Grok-4 when it started infusing political and unwanted replies in the comments, the team pulled it off. They aligned the model, ensured that it was safe, and only then did they ship it back.
As such, there are various alignment techniques that are being used today to solve the alignment issue. Apart from what we discussed previously, here are four additional ones:
Constitutional AI: Anthropic uses this approach to train their AI where uses a set of rules or principles called a “constitution” to align AI. The AI learns to critique and revise its own responses based on these principles. It makes AI systems helpful, harmless, and more controllable without requiring extensive human feedback.
Deliberative Alignment: This is OpenAI’s newest approach that directly teaches models safety specifications. It also trains them to explicitly reason over these specifications before answering. It was used to align OpenAI’s o-series models and achieved highly precise adherence to safety policies.
Direct Preference Optimization: DPO is a simpler alternative to RLHF that eliminates the need for a separate reward model. It uses a simple classification loss to directly optimize the model based on human preferences. It's more stable, easier to implement, and requires less computing power than traditional methods.
Scalable Oversight: This approach uses AI systems to assist human evaluation of other AI systems. The goal is to ensure oversight scales with AI capabilities. For example, training models to write critiques of code to help humans find bugs they might miss.
These alignment techniques work together to make AI safer and more aligned with human values. They solve different parts of the alignment puzzle - from teaching rules to improving feedback quality.
The Role of Model-Written Evaluation Methods
MWE stands for Model-Written Evaluations. These are AI safety tests created by AI models themselves, rather than humans. The idea is to leverage the model's creativity to cover various scenarios humans may not have thought of. This makes them critical for AI safety benchmarking.
MWE tasks are essential for evaluating AI alignment behaviors that directly impact product safety and user experience. These tasks assess alignment-relevant behaviors such as self-preservation inclination, decision-making approaches that affect cooperation, and willingness to accept beneficial modifications.
MWE datasets provide a scalable way to evaluate AI systems by leveraging the model's creativity to cover scenarios humans may not have thought of, making them critical for AI safety benchmarking.
Evaluating AI Agents in 2025

OpenAI's Deep Research represents a new wave of AI agents designed to navigate complex information landscapes. Deep Research is different from earlier systems. It doesn't just respond to prompts. Instead, it searches the web by itself. It finds relevant facts and puts them together into clear answers. This tool stands out because of its persistence. It …
How Solving the Alignment Issue Can Create Better Products
Solving alignment creates AI systems that truly understand human preferences and emotions. As I have already emphasized in the previous article, aligned superintelligent AI will have “holistic understanding of what humans prefer” and be “aligned with our emotions and goals.”
Proper alignment eliminates harmful behaviors like bias, hallucination, and deception. This builds genuine user trust through consistent, safe responses. Product teams gain confidence deploying AI that won’t mislead customers or generate inappropriate content.
Better alignment reduces support burden and liability risks. It enables AI to serve as a reliable thinking partner for complex tasks. When AI understands human values deeply, products become more intuitive and user-centered.
Best Practices to Mitigate Alignment Issues in Current AI
Here are some best practices I came across and have been using to develop better products using the current AI:
Focus on core functionality first. Identify the three most critical features your product needs to excel at. Don’t dump all the feature requests from the customer at once. Take it slow.
Perfect these before adding complexity. This prevents feature bloat, which can amplify alignment problems.Give AI systems comprehensive background information. Current LLMs work best when they understand your company context, user needs, and project goals. Build detailed prompts and knowledge bases that provide necessary context for better decision-making.
Design AI as thinking partners. Use AI to enhance human creativity and analysis rather than replacing judgment entirely. This approach leverages AI strengths while maintaining human oversight for critical decisions.
Exercise continuous human judgment. Even imperfect AI responses can generate valuable insights. Apply your product expertise to filter suggestions and identify useful directions.
Use well-defined LLM-rubric. Spend time with fellow team members and write a defined rubric and test your product before you deploy it.
Treat alignment as ongoing work. Regularly update AI systems with new prompts, contexts, learnings, and outcomes. Even if the current models are not well-aligned, you can still make productive improvements.
AI alignment isn’t a future problem—it’s happening in your product right now. Every time your AI gives a biased response, hallucinates facts, or misunderstands what users actually want, you’re losing time, customers, and burning through resources.
The good news is that alignment problems have practical solutions: better context, human oversight, clear evaluation criteria, and treating AI as a thinking partner rather than a replacement. Companies that solve alignment first will build products users trust and competitors can't match.
Start with the six practices above, and your AI will finally work for your users instead of against them.