GPT-5 Codex and Claude Code: The General Agents For Coding And Product Development
GPT-5 Codex and Claude Code are paving the way for user-aligned products


The adoption rate of agentic coding is rising every passing week. GPT-5 Codex and Claude Code are at the center of it all. Although Claude Code is much ahead of Codex, the latter is in the race to surpass Claude Code.
Up till last month, Claude Code was the most popular CLI-first coding tool that product leaders, AI, and software engineers were using quite profoundly. Because it integrates directly into their codebase. However, the release of GPT-5 Codex is beginning to change things.
Both Codex and CC offer fresh perspectives on agentic coding. CC, which is terminal-based, offers multi-agent orchestration with Claude Sonnet 4, Opus 4.1, and Haiku 3.5 as its models. Codex is available as CLI, IDE extension, and even with chat UI, along with seven GPT-5 models, of which 3 are trained and optimized for coding.

In this blog we will compare these two general agent tools and how they are paving ways to develop user-aligned products.
Understanding General Agents for Coding and Product Development
General coding agents behave like code-native teammates that read, plan, edit, run, and verify across repos, terminals, browsers, CI, and docs. Anthropic built Claude Code as a command-line first agent so developers can work in their terminal with tool access, MCP integrations, and repo-aware actions that produce commits and PRs.
The CLI design is targeted at real-world engineering workflows. Meaning, you don’t have to switch between chat UI and IDE to copy-paste the code.
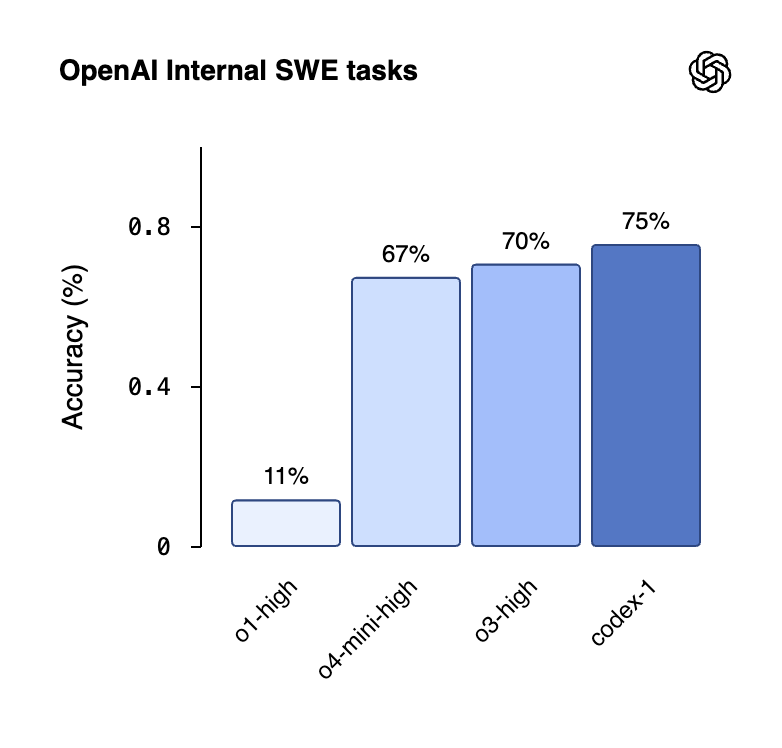
2025 is an inflection point because task success and session stamina improved on real codebases. GPT-5 Codex reports a 74.5% success rate on SWE-bench Verified and can work independently on large projects for multiple hours, which moves beyond autocomplete into sustained execution.
Latent Space’s coverage and other reports also point out these gains and describe longer end-to-end sessions that survive refactors.
Scope still matters.
Agents excel with clear objectives, constrained tool access, and measurable guardrails.
They fail when context is missing or tests are weak.
OpenAI’s Codex guide shows where value appears first: code understanding, refactors and migrations, test coverage lifts, and velocity improvements that keep engineers in flow.
Where do PMs see measurable value now?
Faster feedback to fix issues from issue clustering, to PRs with tests and summaries. This is because prompts are the interface to agents.
Reduced toil by offloading refactors, documentation, and repetitive scripts to an agent.
More consistent documentation through CLAUDE.md and AGENTS.md style playbooks that persist decisions. This is something that is very important. CLAUDE.md and AGENTS.md set the tone of what the product might look like. PM has a high-value role in setting up these memory and instruction files.
Auditable traces with command logs, diffs, and tutor-style explanations that improve reviews.
Market momentum supports this shift. Nathan Lambert, from Interconnects, argues that coding sits at the epicenter of AI progress, which aligns with the rise of agentic tooling inside terminals and CI.
Treat agents like junior engineers with a playbook and tests, and the gains become durable.
Key Components of Agentic Pipelines
What components make agents dependable?
I use a four-part pipeline that keeps work predictable under real engineering constraints. Context provides the right evidence at the right time. Tools give safe, auditable access. Memory preserves decisions across sessions. Evals turn feedback into tests that guide behavior.
Context is one of the important skills to hone the agent and align it with your requirements.
Curate repo maps, failing tests, logs, user sessions, constraints, and acceptance tests. Compress aggressively and iterate to combat context rot and reduce costs.
Tools. Prefer least-privilege access with Model Context Protocol servers rather than ad-hoc CLIs. MCP standardizes connections to systems like GitHub or Postgres and lets you scope permissions cleanly. Then reduces accidental data exposure in enterprise settings.
Memory. Persist product truths, coding conventions, evals, and prior decisions in CLAUDE.md or AGENTS.md. Anthropic’s best practices and internal write-ups show that quality improves when workflows and tools are documented in a single file that the agent reads first.
The same best practices are transferable to OpenAI’s Codex CLI as well. But you can also check out AGENTS.md to learn more about the Codex CLI.
Evals. Convert tickets and complaints into golden tests and rubrics.
Before you run an agent, assemble these inputs.
Top files and dependency map.
Failing tests and minimal repros.
Log slices and user quotes tied to issues.
Data schemas and constraints.
Use a minimal permission template.
Read-only source by default.
Scoped write to a feature branch.
No production network access by default.
Prefer cloud sandboxes for execution and isolation with traceable logs and diffs.
Track telemetry that proves reliability.
Pass rate on golden tests.
PR time to merge and review rounds.
Reverted commits and flaky test rate.
Token and latency budgets for each session.
Prompt success criteria checklists to close the loop.
This structure ships changes without chaos and builds trust with auditors and reviewers.
GPT-5 Codex vs Claude Code Comparison
Choose GPT-5 Codex when you want quick onboarding, web-first ergonomics, and long autonomous sessions that can power through complex refactors.
Choose Claude Code when you value terminal-native precision, MCP-based governance, and opinionated workflow hygiene that suits enterprise constraints.
Both are 2025 tools built for real engineering work, not demos.
Workflow fit. Codex runs in cloud containers with network disabled by default and provides end-to-end sessions that read code, open branches, and propose PRs. This keeps non-experts productive while experts oversee more in-depth changes.
Latent Space’s coverage and OpenAI’s system card describe these longer, PR-style sessions.
Claude Code lives in the terminal and expects explicit repo blueprints and scripted workflows. It leans on MCP servers to talk to internal systems with clear scopes, which suits regulated stacks and complex data estates. Anthropic’s posts and handout highlight repository guides, workflows, and MCP-first integration patterns.
Single agent or multi-agent. Start with a single agent for one narrow workflow and one clear metric. Codex often completes discovery, change, and PR in one run when the context is curated and tests are stable. Move to multi-agent orchestration when separation of concerns improves reliability and review. Claude Code pairs well with MCP to coordinate planner, implementer, tester, and reviewer roles through scripts and scoped tools. Gate each handoff with eval checks and minimal permissions for safe progress.
Security posture. Codex favors isolation by default. Cloud runs execute in OpenAI-hosted containers with strict sandboxing and disabled networking unless explicitly granted. This can reduce the blast radius during agent actions.
Claude Code guidance recommends MCP over raw CLIs for sensitive resources, improving auditability and permission hygiene.
Lifecycle impact. Codex shines across discovery, design, delivery, and hardening by pairing quick interactions with multi-hour autonomy. OpenAI’s internal guide documents wins in refactors, migrations, test coverage, and developer flow.
Claude Code shines when you want reproducible scripts, documented workflows, and terminal discipline that scales across teams. The result is fewer handoffs and clearer review artifacts.
Performance signals. Recent reports cite GPT-5 Codex at roughly 74.5% on the SWE-bench Verified, alongside multi-hour sessions that complete large refactorings. Treat these numbers as leading indicators. Your real KPI should be PR throughput, merged-without-revert rate, and defect escape counts.
Company examples. Anthropic’s teams automate repetitive flows with Claude Code while keeping humans on product decisions and risk calls.
OpenAI frames Codex within a broader productivity agenda and shows concrete improvements on internal engineering tasks.
Practical rubric for PMs.
Need the fastest pilot and broad contributor access? Choose Codex.
Need strict data boundaries and scripted pipelines? Choose Claude Code.
Measure outcomes with PR lead time, revert rate, and flaky test reduction, not benchmarks alone.
Prompting Best Practices to Align Products with User Needs
How do prompts keep behavior stable?
Prompts are interfaces that define how agents act and decide. I write them like specs with a clear role, objective, constraints, evidence, and success criteria.
This mirrors the guidance in Anthropic’s prompt engineering docs, which emphasize explicit instructions, grounded references, and evaluable outcomes so agent behavior remains predictable as requirements evolve.
I anchor the system with four durable assets that span repositories and sprints.
AGENTS.md captures mission, tools, data contracts, and safety rules so every run starts aligned. Task templates standardize inputs and outputs for backlog items. Rubrics translate product taste into checklists that agents can self-check. Context packs compress code, logs, and decisions to reduce drift over long sessions, which matches the compression patterns outlined in your context engineering guide.
Anthropic’s Claude Code best practices also show that maintaining a Claude.md file improves reliability by documenting the workflows the agent reads first.
Also, ensure the feedback loop is tight and measurable. Convert user feedback into tests, attach rubrics to PRs, and re-run agents until everything turns green.
Related: General-purpose coding agents need a specific evaluation framework to prove they are ready for your production environment. The full evaluation framework lives here: How To Evaluate Coding Agents In Production.

Closing
The general agentic coding tools are quickening things up. Whether it is product iteration, new feature release, quick deployment, or whatnot, Codex and CC are increasing productivity and helping enterprises ship faster.
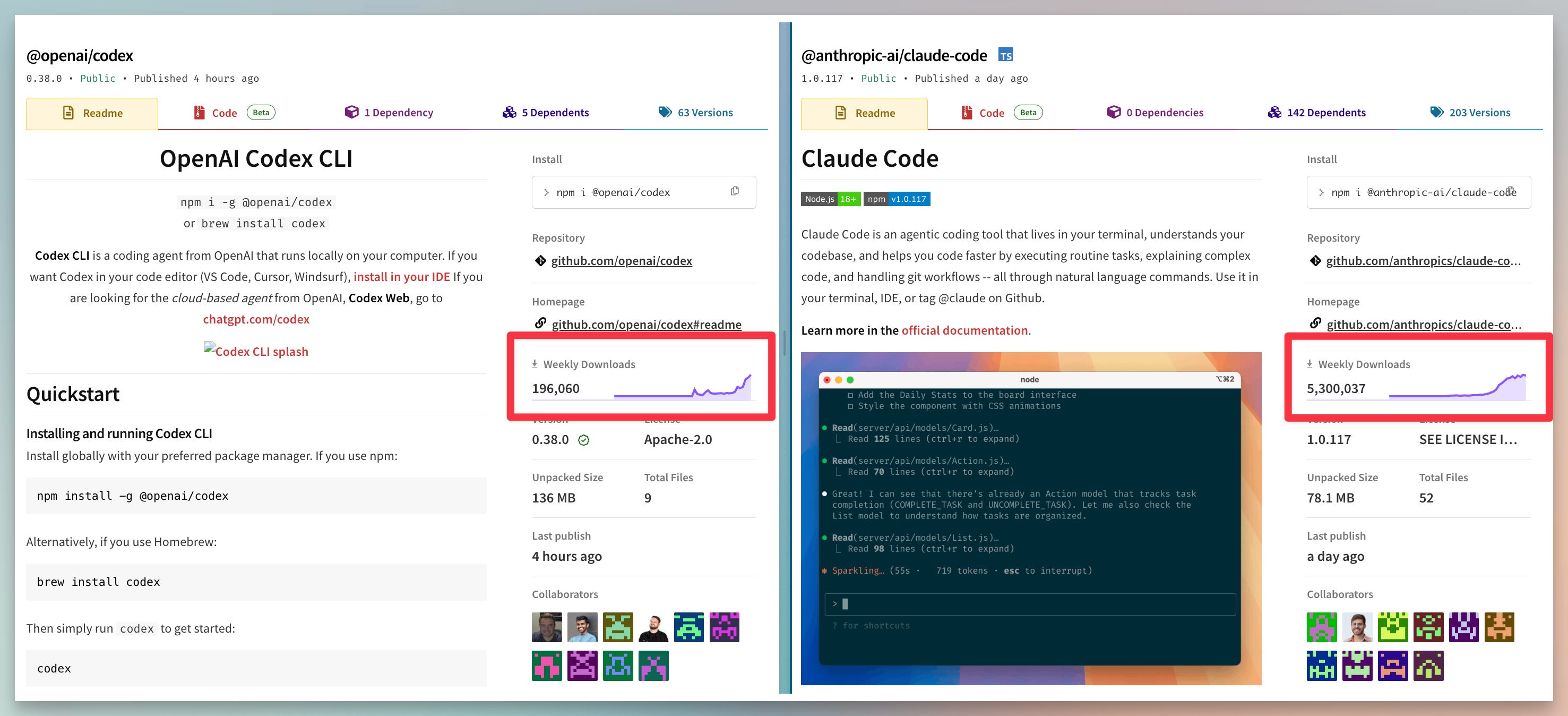
Of course, there are a lot of factors and elements that make an agentic tool more capable. These include providing evals to the context, establishing rubrics, prompting, etc. But overall, we are seeing a trend where lean startups and high-profile labs all have adopted agentic coding. And weekly downloads and adoption are increasing.