
Building AI Agents That Don't Break in Production
A reading guide for teams who have shipped a working prototype and are now discovering why production is different.

TLDR: Production AI agents fail in five predictable ways, and these failures don't arrive one at a time; they arrive simultaneously, compounding each other from the first week of real traffic. This piece is a reading guide, not a comprehensive technical breakdown. It maps each failure mode to the Labs pieces that address it directly, so teams who have already shipped can find the right diagnosis faster. If you are still building your first prototype, this is not the right starting point.

If you have been following the Labs newsletter for a while, you know I keep coming back to one idea: demos are not products, and the gap between them is wider than it looks from the inside.
This piece is my attempt to map that gap concretely, not as a list of best practices, but as a set of failure modes with a reading path attached.
There is a version of your agent that runs reliably in production. But it does not happen by default. There are four decisions that determine whether your agent holds up in production, and they are almost always left until after something breaks.
Production differs from staging in every dimension:
Real users with ambiguous inputs.
Context windows that accumulate noise over long sessions.
Tools that time out when interacting with live APIs.
No measurement infrastructure to tell you what changed when something goes wrong.
The agent who worked on your demo is not the same system that has to face all of this at once.
This guide maps the five failure modes that occur together. Each section names the failure and shows where it surfaces in production.
The Demo-to-Production Gap
In a demo, every variable is controlled. In production, every variable is live.
Carnegie Mellon benchmarks published in 2025 show that leading agents complete only 50% of multi-step tasks under production conditions. The same systems that look solid in staged evaluations.
Datadog’s 2026 State of AI Engineering report, based on telemetry from over 1,000 production deployments, found that 5% of all LLM call spans fail outright in live environments. That is not a benchmark edge case. That is the baseline you are building against.
The gap is predictable once you have seen it. If you want the full argument for why prototypes and products are different systems, that piece already exists. This guide starts where it ends.
Failure Mode 1: Context Rot
Of all five failure modes, I think context rot is the sneakiest. It does not announce itself. It does not throw an error.
Context rot occurs when an agent’s context window fills with stale, contradictory, or irrelevant information across a multi-turn session. Quality degrades, but the agent keeps responding. There is no error, no crash. The output just gets worse.
Chroma’s 2025 research tested 18 frontier models, including GPT-4.1, Claude Opus 4, and Gemini 2.5. They found that every single one degrades at every increment in input length, without exception. Degradation starts well before context limits are reached. Most counterintuitively, models perform better on shuffled haystacks than on logically coherent documents, meaning structured, multi-turn conversations accelerate degradation rather than containing it.

You will encounter this in long sessions, customer support flows, and any workflow where the agent holds state across turns. For the full diagnosis, read context rot in production. When the root cause is confirmed, the engineering response to why AI products break in production is covered.
Failure Mode 2: Tool Execution Unreliability
Tools fail silently. They return partial results, time out mid-call, or return outputs in formats the agent was not designed to handle. What the agent does next is the problem: it hallucinates a completion, enters a retry loop, or produces a confident-sounding response built on a null return.
Datadog’s production telemetry found that 60% of all LLM agent errors are due to exceeded rate limits. And the most common form of tool execution failure in production.
ReliabilityBench tested leading models under production-like stress conditions and found reliability drops exceeding 10 percentage points: Gemini 2.0 Flash fell from 96.88% reliability under ideal conditions to 84% under combined fault stress. Same model, same tasks, different operating conditions.
In my general understanding of how production debugging unfolds, tool failures are the first thing engineers blame the model for — and the last thing they trace back to the tool layer. Standard agent evals are designed to test the model’s reasoning. Very few test how the agent behaves when the tool returns something unexpected. For diagnosing and addressing this, read reliable tool-using agents in production. For the construction side, writing effective tool-calling functions is the companion piece.
Failure Mode 3: Evaluation Blindness
Evaluation blindness is shipping without a measurement infrastructure and discovering quality changes through user complaints rather than metrics. Every production change, be it a prompt edit, a model upgrade, or a new tool configuration, becomes a gamble.
Without evals, you cannot tell whether quality improved or degraded until the signal arrives from users, which is too late and too noisy to act on.
This is the hardest failure mode to recover from, and I will say that directly. Context rot and tool failures are visible once you know where to look. Evaluation blindness hides everything else.
Eugene Yan, who has spent years building production LLM evaluation systems, argues that evals are a scientific method practice, not a tooling problem. The framing matters: if you treat evals as a phase-two addition, you will always be running them on a system you cannot yet explain.
Research published in December 2025 found that 8 of 10 popular agent eval benchmarks have validity issues. For instance, a do-nothing agent passes 38% of tasks on the τ-bench airline benchmark. The standard tools for measuring quality are unreliable. That makes building your own measurement practice more urgent, not less.
For the framework, read the AI agent evaluation crisis and LLM evals as a product tool. The complete guide to AI agent evaluation covers the full implementation.
Failure Mode 4: Observability Gaps
When something goes wrong in a multi-step agent, the question is not whether you can see the failure. It is whether you can determine which step caused it. A wrong decision at step two produces a plausible-looking failure at step seven. Without trace-level visibility, you are debugging symptoms, not causes.
The distinction between monitoring and observability matters here. Monitoring tells you what happened. Observability tells you why — which tool call returned the bad output, whether the error was a reasoning failure or a bad input, how the agent’s confidence changed across steps.
MIT-led research published in April 2026 found that models trained with standard reinforcement learning become overconfident and poorly calibrated. Meaning you cannot distinguish a confident correct output from a confident hallucination without trace-level data.
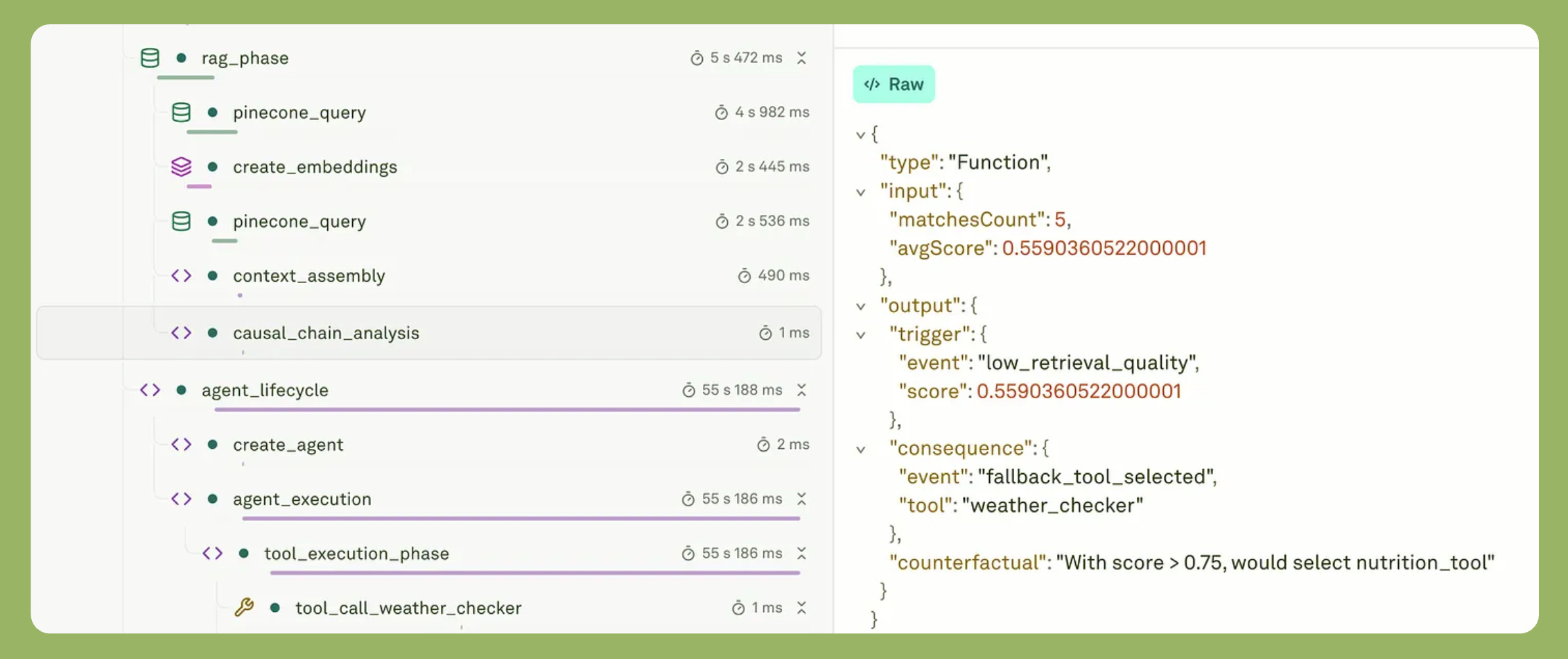
For the framework, read observability vs. monitoring for agentic AI. For how observability and evaluations connect in practice, AI observability and evaluations is the companion piece. The LLM observability and monitoring guide covers the implementation layer.
Failure Mode 5: Nondeterminism Without Design
Production agents behave differently on identical inputs, across sessions, across days. You either design around this or you don’t. The distinction matters: nondeterminism is not a bug. It becomes one when the product is not built to accommodate it. That is a product design failure, not a model failure.
I believe this is the framing that separates engineers who ship stable agents from those who spend weeks trying to make the model more consistent. The model will not get more consistent. The product needs to be designed for the model it already has.
NeurIPS 2025 research identified the mechanism precisely. The precision format used during inference — FP32, FP16, or BF16 — directly determines output variance, and most production inference runs on BF16, which introduces significant variance as a baseline condition.
More practically, Thinking Machines Lab found that the most common source of production nondeterminism is not temperature settings. It is a batch invariance failure, where inference servers dynamically adjust batch sizes based on load, so the same query can return different outputs depending on server traffic at the moment of the request.
A user who gets different answers to the same question on consecutive days does not think about inference precision. They think your product is unreliable. The product decisions that determine whether they are right must be made before you ship.
Read designing AI features for nondeterminism before you finalize UX.
The Compound Problem
So what makes production genuinely hard is not any one of these failures in isolation. These five failure modes do not arrive one at a time. They arrive simultaneously, on the same day, with real users already in the system.
Here is what the cascade looks like.
Context rot degrades the agent’s ability to use tools correctly, because the agent is already working from a context window that has lost signal.
Tool execution failures trigger retry logic that consumes context faster, which accelerates context rot further.
Without observability, you cannot see which problem is causing which symptom.
Without evaluation infrastructure, you cannot tell whether a fix for one failure mode broke something else.
Without nondeterminism-aware design, users experience all of it as random, unpredictable product behavior, not as five distinct technical problems that each have a solution.
A March 2025 study from UC Berkeley analyzed over 1,600 production agent traces across seven multi-agent frameworks and identified 14 distinct failure modes across three root cause categories. ChatDev, a widely cited open-source multi-agent system, achieved correctness as low as 25% on real tasks.
Research from March 2026 documents the same pattern from a different angle: GPT-4o achieves 61% pass@1 on retail agent tasks but drops to 25% pass@8 — a 36-point drop between first attempt and repeated attempts on the same system with identical inputs.
Multi-agent systems multiply every one of these problems. Each additional agent is another surface where context rot, tool failures, and observability gaps compound into each other. Read multi-agent systems and control planes when you are ready to think about coordination at that level.
Treating any of these as optional is not a sequencing decision. It is a bet that compound failures will be cheaper to fix under live traffic than to prevent. That bet loses consistently.
The Reading Sequence
The Labs pieces exist to go deep on each of these failure modes. So this is roughly how I would sequence the reading, depending on where you are in the production journey.
Read before you ship
Prototypes and products are different systems: Read this before you deploy. It names the exact decision points that separate a demo from something that holds up against real users, and it is the most useful thing to read before any of the failure mode pieces.
Designing AI features for nondeterminism: Read this before you finalize UX. The product decisions it covers cannot be retrofitted after users start experiencing inconsistency.
Read when you are debugging production failures
Context rot in production: Read this when quality is degrading across long sessions and you cannot explain why. Context rot almost always surfaces through user feedback first, not dashboards — because the instrumentation to catch it usually isn’t in place yet.
Why AI products break in production: Read this when context rot is confirmed and you need the engineering response.
Reliable tool-using agents in production: Read this when tool call failures are producing confident wrong answers and users cannot tell the difference.
Observability vs. monitoring for agentic AI: Read this when you can see that something went wrong but cannot determine which step in the chain caused it.
Read when you are building evaluation and scaling infrastructure
The AI agent evaluation crisis: Read this first if you have no evaluation infrastructure. It explains why agent evaluation is structurally different from model evaluation — a difference that usually surfaces live, with real users, at the worst possible moment.
LLM evals as a product tool: Read this when you need to bring non-technical stakeholders into the evaluation conversation.
Multi-agent systems and control planes: Read this when you are moving from a single agent to a coordinated system, and every failure mode above suddenly multiplies.
Closing
After reading through the research and listening to engineers describe their production breakdowns, the pattern that stands out is not technical. The agents that hold up in production were not built on better models or bigger budgets. They were built by people who decided earlier that production readiness was part of the design, not a phase that follows it.
The single biggest predictor is not the framework you chose or the model you are running. It is about building the discipline to measure what the system is doing before users tell you it is broken.
The failure modes are predictable, the patterns are documented, and the path is clear. Skipping it because the demo works is the most expensive decision in this entire process. It never pays off.
Curious what the most common failure mode you see is for AI agents breaking in production — is it usually tool call errors, context drift, or something harder to predict?
The compound cascade section is the part that separates this from every other "agents in production" post. Most teams debug these five failure modes sequentially. Fix context rot, then fix tool reliability, then add evals, then add observability. That sequencing is itself a failure mode because fixing one in isolation changes the behaviour of the others.
Context rot is the clearest example. You add a summarisation step to compress the context window. Quality recovers. But summarisation changes what the tool layer receives as input, which changes tool behaviour, which shifts what your evals are actually measuring, which means your evaluation baseline is now stale. You fixed one problem and silently invalidated your ability to detect three others. Most teams discover this around week four when the metrics look fine and the users are complaining.
The 38% do-nothing agent stat deserves more attention than a footnote. If an agent that takes no action passes 38% of a benchmark, the benchmark is measuring the correlation between inaction and favourable starting conditions, not capability. Every team running evals against public benchmarks should run the null agent test against their own suite before trusting the numbers.
The nondeterminism framing is the line I'd put in front of every product leader reading this. "The model will not get more consistent. The product needs to be designed for the model it already has." That sentence resolves about six months of engineering arguments in most organisations.