
Reliable Tool-Using AI Agents In Production: MCP, State, Retries, Timeouts, and Recovery
A practical guide to designing agent runtimes that can call tools safely, recover from failure, and stay observable in production.

TLDR: Getting an agent to call a tool is the easy part. The hard part is what happens when that tool hangs, partially succeeds, or mutates external state in a way the model cannot recover from on its own. This article covers five runtime mechanisms that determine whether a tool-using agent survives production. You will learn how to classify tool risk by state type, how to retry safely using idempotency keys, how to set timeouts per tool rather than per system, and where to place approval gates before irreversible writes. Also, how to design recovery into the workflow before the first failure occurs. If you are building or evaluating an agentic system, the reliability gap is not in the model. It is in the runtime layer around it.

Tool Calling Is Not the Hard Part
The hard part is not getting an agent to call a tool. Every agent that reaches a demo can do that. The hard part is what happens next, i.e., when a tool hangs, returns partial results, mutates state, or leaves the workflow in a condition the model cannot resolve on its own.
Tool calling is what moves agents from answering questions to taking actions. MCP sets the standard for how those tools are exposed and invoked. But neither addresses what production demands: a runtime that survives tools that fail partway, time out, or create side effects that a retry makes worse.
OpenAI’s sandbox documentation separates orchestration from execution because the two layers have different problems. Anthropic’s managed-agents essay frames the same split between the “brain” and the “hands.” Both point at the same fact: the model gets you to the first successful tool call; the runtime decides whether the workflow survives everything after it.
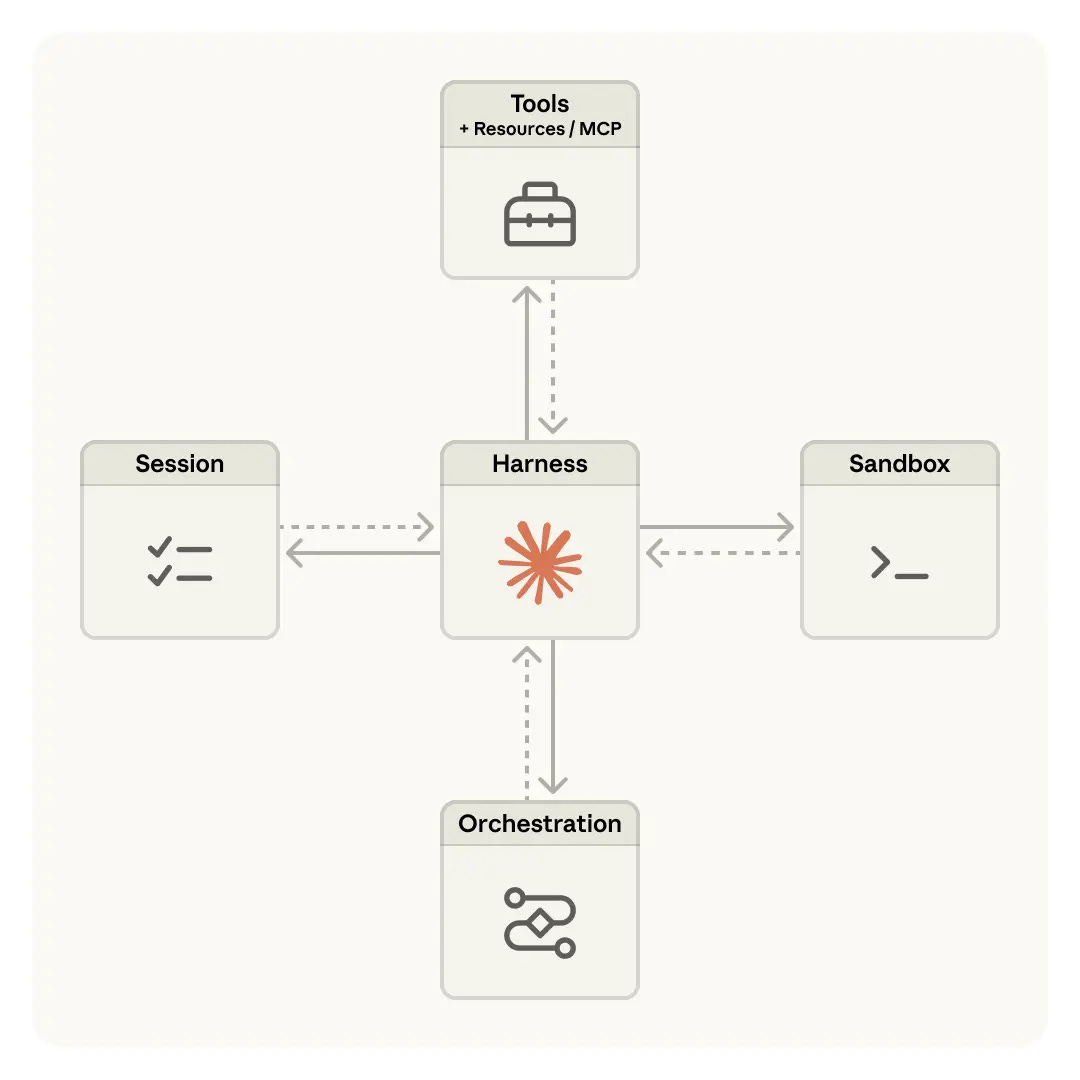
This article covers five things that determine reliability for agentic LLMs in production: state type, retries, timeouts, approvals, and recovery. None are model problems. All are runtime problems.
What Changes When an Agent Uses Tools in Production
A one-shot tool call is simple by design. The agent queries an API, gets a result, and generates a response. Failure resets to zero without damage.
Production workflows are built differently. Once an agent calls tools across a multi-step sequence, it touches mutable systems. For instance,
A call at step three changes the state that step four reads.
A timeout at step five leaves the system in a condition that the model cannot sort out on its own.
A partial failure at step seven may have already sent the email, updated the record, or triggered an external job that cannot be canceled.
OpenAI’s sandbox guide treats execution as a stateful workspace with persistence and tool artifacts.
Anthropic’s managed-agents writeup makes the same point: longer-lived work needs structured execution surfaces, not raw chat continuity.
What breaks in production-ready agentic systems are the boundaries around the tools, like:
What happens when a write fails halfway,
When context breaks in production corrupts a later step,
When nondeterministic failures pile up across a workflow built only for the happy path.
Runtime design handles all of these. Model fluency does not.
MCP Sets the Interface; the Runtime Owns the Rest

The MCP Product Playbook describes MCP as a standard interface between models and tool providers. That is exactly what the MCP specification does:
It defines how tools are exposed, described, and invoked.
It handles discovery, schema, and transport.
It does not handle what happens when a tool times out, when a write is retried in an unsafe way, or when the model must decide if a failed call means the action ran.
Standard access is the first step and not a guarantee of safe execution. The runtime still owns permissions, retry logic, timeout rules, approval gates, artifact storage, and recovery paths.
The tool-calling functions layer defines how tools are described to the model. The product control plane governs how they run and how state is tracked across steps. Prompt management controls what the model sees; the runtime controls what it does.
Both OpenAI and Anthropic treat standard access and safe execution as separate layers. Conflating them is how production reliability becomes an afterthought.
Stateful vs. Stateless Tools
Not every tool carries the same risk. The line that matters most in production is not what a tool can do — it is what a tool changes.
Stateless tools read or compute without touching anything outside the agent’s context. A web search, a CRM record lookup, a file read, or a database query all fit here. If they fail, retry them freely. The cost is latency, nothing more.
Stateful tools write to the world outside the agent. Sending an email, updating a CRM record, merging a pull request, creating an invoice, publishing content, etc. These all change the external state in a way that reads never do. Once execution begins, a failure does not undo what has already run. The email may already be sent. The invoice may already exist.
This is the line the tool orchestration layer must hold. Different tools require different handling, such as retry rules, idempotency requirements, and fallback paths. Sub-agents that each own a distinct tool set make this boundary clear, rather than running all actions through one loop with no risk distinction.
The problem is the gap between tools you can retry freely and tools you cannot.
Retries and Timeouts Are Workflow Decisions, Not Infra Defaults
Retries look like infrastructure. In practice, they are workflow decisions with consequences that users see.
For stateless tools, retry logic is simple: if the call fails, try again with backoff and jitter. AWS’s Builders’ Library guidance on timeouts and retries applies directly. For stateful tools, the question is harder.
Was the action done before the failure, or not?
A network timeout after a write does not tell you whether the write went through. Retrying without a guard could run the same action twice.
Stripe’s idempotency model handles this with idempotency keys with a unique ID on each request, so that retrying returns the same result instead of creating a duplicate.
AWS’s guidance on making retries safe applies the same idea to distributed APIs. The pattern transfers directly: attach a unique operation ID to each stateful call, and let the downstream system deduplicate on that key.
Idempotency handles the retry problem. But retries only trigger when the system knows a call failed. Timeouts introduce a harder case: the call ended, but you do not know whether it succeeded. One timeout setting across all tools is not a policy; it is a default that creates failure modes the agent was not built to handle. The right cutoff depends entirely on what normal looks like for that tool:
A fast-read API should cut off after 2 seconds.
A code sandbox may need twenty.
A document pipeline may need two minutes.
Each tool needs its own timeout, matched to its own normal runtime.
Four rules apply across both:
Retry reads freely; use idempotency keys for all stateful writes. Meaning: attach a unique operation ID so the downstream system can deduplicate rather than run it twice.
Track four outcomes: success, explicit failure, timeout, and unknown. Treat unknown as requiring review, not the same as failure.
Decide before launch which failures auto-retry, which escalate, and which stop the run.
Surface retry counts in your traces, because a tool that always works on the third attempt is a sign that AI products are breaking in production before users notice.
Adaline’s Deploy overview and CI/CD integration connect here: pipelines that test agent behavior across environments need to know which tools are retry-prone before those patterns hit real traffic.
Recovery Requires Checkpoints, Artifacts, and a Clear Next Step
Retry logic prevents some failures from worsening. It does not cover the case where the workflow must stop, save its state, and either resume or hand off.
OpenAI’s sandbox model treats stateful workspaces as a core design element: the runtime holds files, outputs, and mid-step results so a failed run does not restart from scratch. Anthropic’s managed-agents essay makes the same point: execution surfaces must support checkpoint-and-resume rather than using raw chat context to rebuild what happened.
Recovery is not an error handler. It is a design decision made before the first run. The right checkpoint places depend on which steps are costly to re-run and which are hard to undo. Persistent state across steps lets the system pick up at the right point without redoing completed writes.
The choice between re-plan and hand-off matters. Review loops in coding agents show this clearly: some failures mean the plan needs to change; others mean the run should stop and surface its state to a human. Knowing which applies before the run starts is what keeps a failure recoverable. Deploying your prompt ties this to runtime snapshots, diffs, and rollback history.
Approvals Belong at High-Risk State Transitions
Not every tool call needs a human in the loop. But some should never run without one.
Google ADK’s human-input documentation treats human input as a workflow step for decision checks and permissions, not a safety net added after the fact. Approval gates are workflow boundaries, not general AI safety measures.
The tools that need approval share one trait: they create state changes that are hard to undo. Sending a customer email, merging a pull request, publishing content, creating an invoice, or deleting a record all belong here. Permissions and handoffs between agents, or between an agent and a human, are first-class concerns.
Sub-agents that handle delegated tasks need approval rules set before the task starts, not at runtime. Behavioral constraints in AI PRDs make the same point: failure limits and approval rules must be in the spec before a feature ships, not left as undefined behavior.
Observability Makes Reliability Measurable

Retries, timeouts, checkpoints, and approval gates are mechanisms. Without visibility into what actually ran, in what order, with what inputs and outputs, those mechanisms operate on guesswork.
Observability vs monitoring for agentic systems is not the same problem as watching a stateless API. A stateless API either responded or it did not. A tool-using agent has a multi-step trace in which any step can fail, retry, time out, partially succeed, or pause for approval. The final output tells you almost nothing about what happened in the middle.
What needs to be visible are every tool call, its inputs and outputs, retry counts, timeout events, approval triggers, state changes, and the recovery path taken. That trace is not debugging overhead. It is the layer that turns retry rules and timeout settings into something you can measure and improve.
LLM observability at the production level includes distributed tracing, per-request visibility, and anomaly detection. AI agent evaluation connects pre-launch testing to production monitoring. Essentially, behaviors you test before release need to be tracked after it, because real traffic finds edge cases no test suite fully covers.
Reliable Tool-Using Agents Are Built at the Runtime Layer
Every agent that reaches a demo can call the tools. What separates a solid system from a fragile one is what happens after that first call. Can the runtime classify tool risk, retry safely, hold per-tool timeouts, preserve state through failure, gate irreversible writes, and keep the full trace visible?
PromptOps, Iterate, Deploy, and the full Adaline platform connect to exactly this: reliability is not a feature you add once the agent works. It is the layer you design first and build the agent on top of.
Every agent demo I've seen nails the happy path in under five minutes. The other 95% of the engineering work is exactly what this article covers and nobody wants to fund it because it doesn't demo well.
"We need idempotency keys on stateful tool calls" doesn't get budget approved. "Watch the agent book a flight" does. Then the agent books the flight twice and suddenly the runtime layer has a budget.
The gap between demo-ready and production-ready is entirely made of the boring stuff in this piece. Retries, timeouts, recovery paths. The things that only matter when they're missing.