
Prompt Management for Product Leaders
How Adaline's prompt management and registry platform keeps canonical prompts consistent from sandbox to production


As product leaders, you are responsible for building impactful products. In this sense, products that align well with users’ intent and vision are impactful. In general, most of the products have a vision or a problem to solve. Additionally, they know their ideal customer profiles (ICP) to target. But the challenge is to somehow deliver a product that fits well with all the ICP or users. To solve that problem, product leaders must gather user feedback and improve the products. This ensures that the product is well aligned with the users.

Today, most of the products are built with LLM as their core engine. Essentially known as an AI product. This means they are highly dependent on prompts. With prompts as their primary interface, these products are easy to interact with, tame, or align than ever before. What product leaders must do is to understand their products and users’ intent. But finding the right prompt isn’t straightforward. Prompts need to be evaluated against various test cases or user queries. Teams must iterate prompt constantly until they find what works. This requires systematic prompt management, where you can iterate, evaluate, deploy, and monitor the prompt.
Prompt management allows you to:
Create prompt [templates] as a single source of truth for all use cases or user queries. It enables domain experts and engineers to collaborate effectively. Essentially, exploring what works the best and what doesn’t.
Use a prompt sandbox, like Adaline, for safe experimentation and storing before deployment.
Version control to track changes and their performance.
Monitor the deployed prompt and make necessary changes.
In this blog, we’ll explore how the four pillars of prompt management — iterate, evaluate, deploy, and monitor — transform AI product development. More precisely, how Adaline allows you to transform prompts into a superpower and an impactful product.
Why Prompts Are the Single Source of Truth
Prompts, as I have discussed earlier, are the primary interface which helps us to interact with the LLMs. The LLMs are as effective as the prompts. So, if the prompts aren’t well structured and clearly defined, you will not get a good response from the LLM. This will eventually lead to frustration. And from the product point of view, prompts are the souls.
In an AI product, we use a general LLM that is trained on world data. And to effectively align it, we need to have prompt templates. These templates give the LLM a motive or a purpose, a task to execute within the constraints.
For instance, let’s say you have a template that allows users to get a doctor’s appointment. The template will lay out all the necessary instructions as well as the variables that the user must fill. These variables will help the LLM find the nearest hospital or clinic and the available doctor.
Here’s a simple prompt template example:

However, the prompt can fail if certain things are not optimized for. It could handle common specialties well, but can struggle with rare ones. Variables might not capture urgent appointment needs properly. These gaps emerge only through real-world testing.
For instance, when the user sends their queries, essentially filling out variables, then the LLM can make up a doctor's name. It can also generate responses that aren’t real.
That is why product leaders need to iterate on prompts via evaluation and add capabilities to the prompts to get real-time data. They must be on their toes to see where the prompts can fail, how to reinforce them, and create test data that strictly adheres to the ICP.
Now, this is important – creating a test dataset.
The test dataset reflects your ICP scenarios or plausible use-cases. It is an interpretation of how the users might use the product. To create the test case, you must study the user base and, more importantly, the constraints and the edge cases. Simultaneously, you must never lose sight of the product’s vision. This will help you create a dataset that is narrow and focused while covering the edge-cases. Another way to get test cases is to:
Analyzing real user queries from production logs.
Identify edge cases where your prompt might struggle.
Include variations in user input formats and phrasing styles.
Use LLMs like GPT-5, Claude Sonnet 4.5, Grok-4, and open-source models like GPT-oss, Qwen-3 variants, etc., to paraphrase existing user queries. These will get you different flavours and the prompt will be much diversified.
Once you have enough user queries, you can then create a CSV file and upload it to Adaline.
Prompt Iteration via Evaluation
Now that we have a basis prompt ready and its test dataset along side, let’s evaluate it. Evaluation is the key to iteration. In order to design prompts that don’t break in production, you must evaluate and then iterate.
Adaline offers you multiple evaluation techniques which allows you to inspect each and every angle of weakness leading to failure. Let’s explore them one at a time.
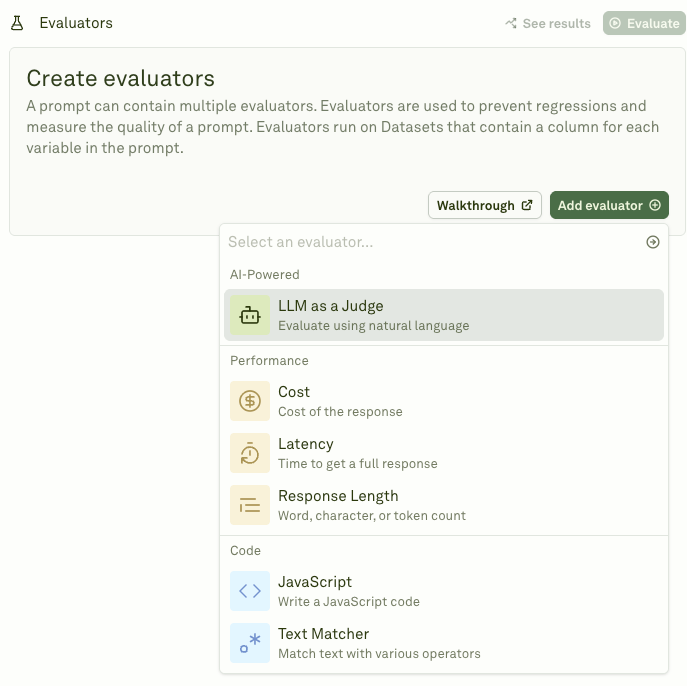
First, we have LLM as a Judge. This is one of the most popular evaluation methods for measuring response quality. An LLM reviews the output against specific criteria you define. It checks for accuracy, relevance, and adherence to instructions. For the appointment booking example, the judge evaluates if the response includes clarity & structure, conversational quality, and completeness, etc. It can also verify that location constraints are properly respected. This technique scales well across thousands of test cases.
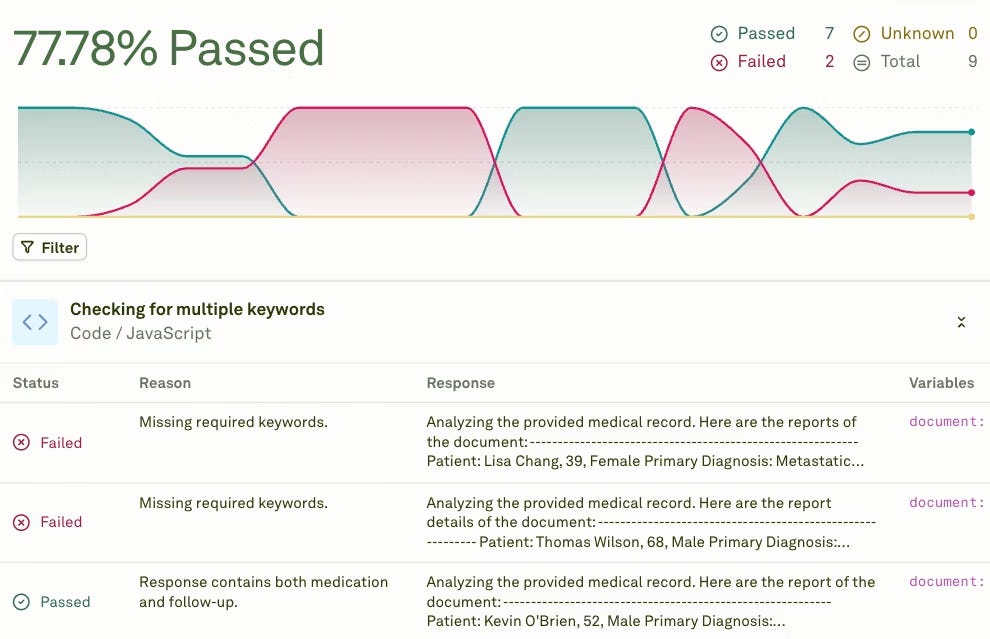
Then, Adaline provides performance evaluators to see how your prompts are performing. For instance,
Cost: Tracks token usage and API expenses per prompt execution. Helps identify prompts that consume excessive tokens unnecessarily.
Latency: Measures response time from request to completion. Critical for user experience in real-time applications.
Response Length: Monitors output size to ensure concise, relevant answers. Prevents verbose responses that waste tokens and user attention.

Lastly, there are code evaluators that help you validate structured outputs programmatically. They check if the response follows the required JSON schemas. They verify that extracted data fields contain expected value types. For appointment booking, code evaluators confirm that booking IDs are valid integers. They ensure date formats match your system requirements precisely.
With these evaluators, you can see how well each user query performs on a given prompt. It helps you to iterate and optimize the prompt while maintaining consistency. You reduce latency by simplifying unnecessary instructions. You control costs by eliminating redundant token usage. Each evaluation cycle brings you closer to a production-ready prompt. This systematic approach prevents costly failures when real users interact with your product.
As a product leader, understanding prompts from a technical aspect is important. It allows you to reinforce your prompts against all the weaknesses and prevent failures. You importantly you can use this prompt sandbox to iterate and store prompts before deployment to further test them.

Extending the Prompt Capability via Tool Calling
There are times when prompts alone are not enough; they need additional support to elicit effective responses from the LLM. One of such things happens when LLMs don’t find a factual grounding to support their response. In that case, they can hallucinate because they want to complete the response. This happens when the LLM is not able to retrieve current or recent information. This limits LLMs because they are trained on cutoff knowledge.
But there are ways in which you can incorporate current knowledge into the LLMs. For that, you need to extend the capabilities of the prompt. This can be done by defining tool-calling function within the prompt.
Keep in mind that all the current LLMs in 2025 are trained to access the tools. What are the tools that we are talking about? Tools can be anything, a method that fetches data from a database or API.
In Adaline, you can test or evaluate the prompts tool calling performance and iterate to get a better prompt that can effectively improve the model’s performance. For instance, in the “medical appointment assistant” example, we can add a number of tool-calling functions. Let’s say you want to “verify if the doctor accepts the patient’s insurance.” You can write a simple tool that calls the function and simulates the API. For that, let’s modify the prompt by mentioning the tool name.

Secondly, let’s add the tool calling function.
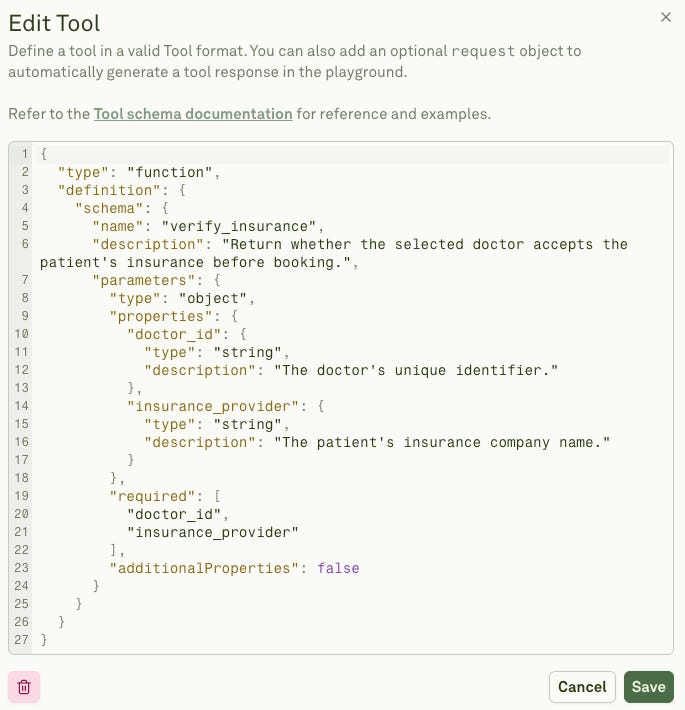
Now, all we have to do is run the prompt template with user queries in the Adaline Playground.
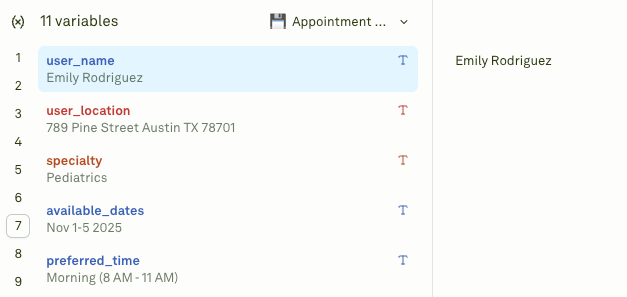
Upon running, this is what the LLM responds.
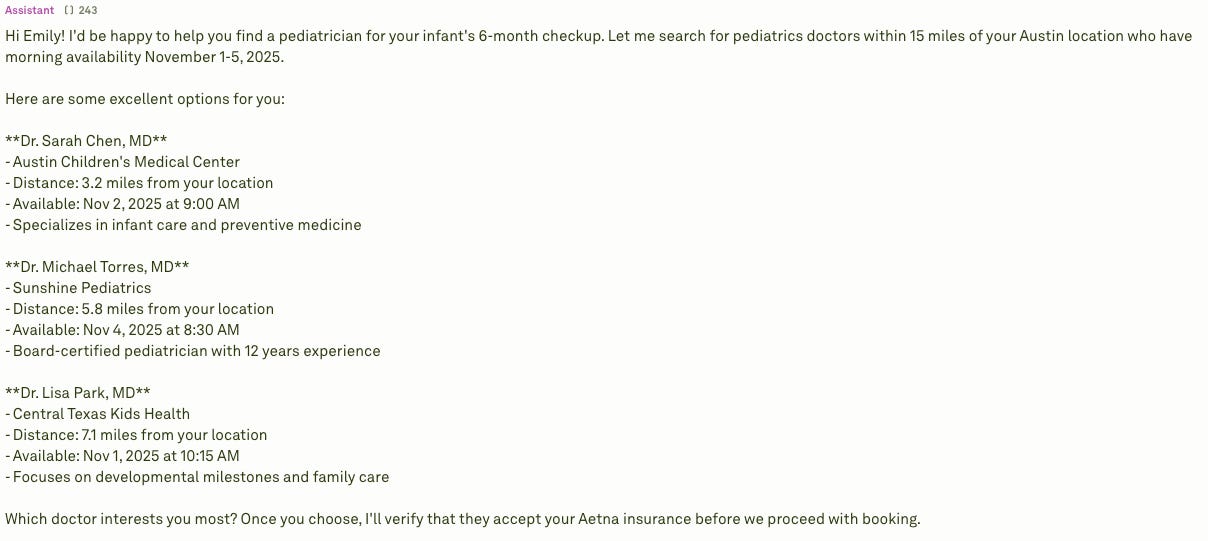
Now, this is where it gets interesting. If you now select the doctor, the LLM will invoke the verify_insurance tool-calling function.

You can then provide a tool response and see how the LLM responds.
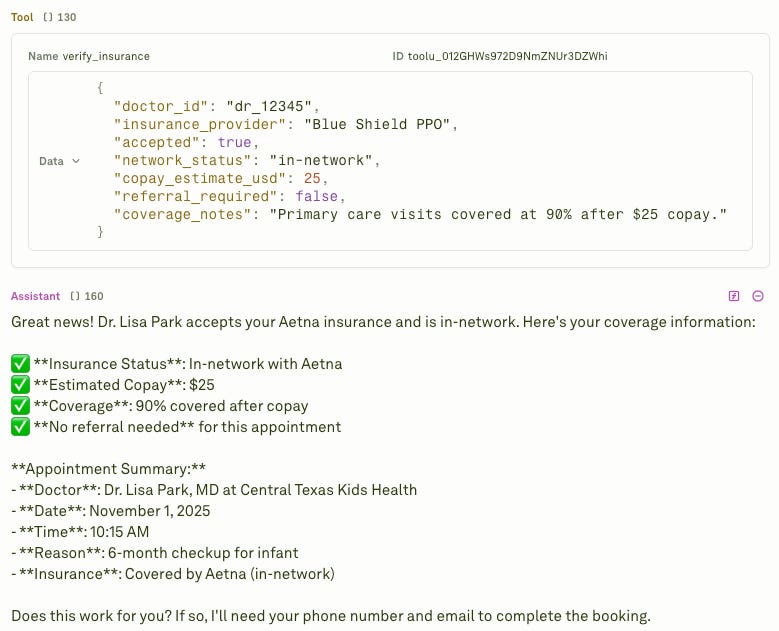
This is a very efficient way to check how you prompt tames the LLMs.
You can also connect the MCP server in Adaline.
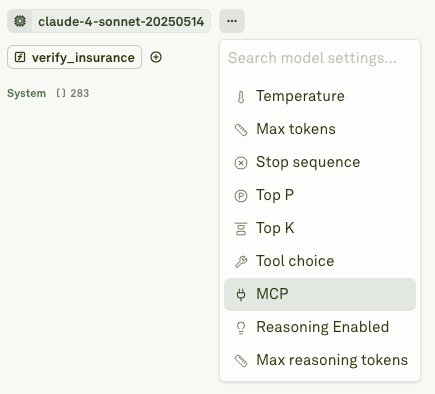
This allows you to use multiple tools within a single prompt. This is a great feature for a product that uses multiple tool-calling.
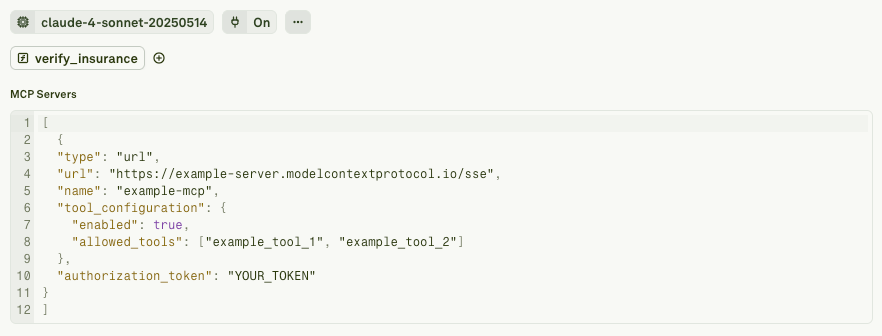
Tool-calling is a powerful capability you can give to the LLM. Why? Because you want the product to be as specific as it can be to your niche or vision. With tool-calling, you are essentially aligning the model to the users’ intent. Adaline allows you to envelop all this capability into a single payload. You essentially work with a multi-faceted platform that allows you to conveniently tweak the smallest of the details.

Deploying the Prompt
Once your prompt is ready with all the necessary configuration, tool capability [or extension], etc., you can deploy it. In Adaline, deployment is as simple as clicking the Deploy button.

Now, to fetch the payload, just follow the code below. This code is written in Python, but you get to fetch the payload in JavaScript, cURL, and Go as well.
import requests
api_key = “your_workspace_api_key”
prompt_id = “95c014f8-8355-4e0d-b9c7-6a866ce07b6c”
deployment_environment_id = “8dc71e24-c484-4f43-a094-3693409107f2”
base_url = “https://api.adaline.ai/v2/deployments”
url = f”{base_url}?promptId={prompt_id}&deploymentEnvironmentId={deployment_environment_id}&deploymentId=latest”
headers = {
“Authorization”: f”Bearer {api_key}”,
“Content-Type”: “application/json”
}
response = requests.get(url, headers=headers)
print(response.json())Output:
{
“id”: “22a27b48-90b5-497d-b594-56e1ed95f49e”,
“createdAt”: 1761319608269,
“updatedAt”: 1761319608269,
“createdByUserId”: “t0tJzpNuXtgqQlemfR5vpHlU5fW2”,
“updatedByUserId”: “t0tJzpNuXtgqQlemfR5vpHlU5fW2”,
“promptId”: “95c014f8-8355-4e0d-b9c7-6a866ce07b6c”,
“projectId”: “e7c011ac-45bc-47a2-85b2-6d0080ea9242”,
“deploymentEnvironmentId”: “196e4559-df67-453b-bb46-028b713badc1”,
“prompt”: {
“config”: {
“providerName”: “anthropic”,
“providerId”: “2dbcb189-b612-42ae-a143-b4ca3e7c35dc”,
“model”: “claude-4-sonnet-20250514”,
“settings”: {
“mcp”: true
}
},
“messages”: [
{
“role”: “system”,
“content”: [
{
“modality”: “text”,
“value”: “You are a friendly medical appointment assistant. Your goal is to help users find and book appointments efficiently.\n\nCONTEXT:\n- User: {{user_name}}\n- Location: {{user_location}}\n- Specialty: {{specialty}}\n- Available Dates: {{available_dates}}\n- Preferred Time: {{preferred_time}}\n- Insurance: {{insurance_provider}}\n- Search Radius: {{search_radius}}\n- Urgency: {{urgency_level}}\n\nAVAILABLE TOOLS:\nverify_insurance: Use this to check if a doctor accepts the patient’s insurance. Always call this function BEFORE confirming an appointment to avoid billing surprises.\n\nTASK:\n1. Search for {{specialty}} doctors within {{search_radius}} of {{user_location}}.\n2. Present 3–5 options with soonest availability drawn from {{available_dates}} and {{preferred_time}}.\n3. Call verify_insurance for the user’s chosen doctor BEFORE booking.\n4. Briefly explain coverage status (in-network vs out-of-network) and potential copay, if available.\n5. Confirm: doctor, date, time, reason for visit, and insurance coverage status.\n6. Collect: phone {{phone_number}} and email {{email}}.\n\nSTYLE:\n- Be warm and conversational.\n- Keep responses concise.\n- Always verify insurance before final booking.\n- Explain any out-of-pocket costs simply.\n- Ask one question at a time.\n- Confirm understanding at each step.”
}
]
},
{
“role”: “user”,
“content”: [
{
“modality”: “text”,
“value”: “Hi! I need to book a {{specialty}} appointment.\n\nMy details:\n- Name: {{user_name}}\n- Location: {{user_location}}\n- Available: {{available_dates}}\n- Preferred time: {{preferred_time}}\n- Insurance: {{insurance_provider}}\n- Reason: {{reason_for_visit}}\n\nCan you find doctors nearby who accept my insurance?”
}
]
}
],
“tools”: [
{
“type”: “function”,
“definition”: {
“schema”: {
“name”: “verify_insurance”,
“description”: “Return whether the selected doctor accepts the patient’s insurance before booking.”,
“parameters”: {
“type”: “object”,
“properties”: {
“doctor_id”: {
“type”: “string”,
“description”: “The doctor’s unique identifier.”
},
“insurance_provider”: {
“type”: “string”,
“description”: “The patient’s insurance company name.”
}
},
“required”: [
“doctor_id”,
“insurance_provider”
],
“additionalProperties”: false
}
}
}
}
],
“variables”: [
{
“name”: “user_name”,
“modality”: “text”
},
{
“name”: “user_location”,
“modality”: “text”
},
{
“name”: “specialty”,
“modality”: “text”
},
{
“name”: “available_dates”,
“modality”: “text”
},
{
“name”: “preferred_time”,
“modality”: “text”
},
{
“name”: “insurance_provider”,
“modality”: “text”
},
{
“name”: “search_radius”,
“modality”: “text”
},
{
“name”: “urgency_level”,
“modality”: “text”
},
{
“name”: “phone_number”,
“modality”: “text”
},
{
“name”: “email”,
“modality”: “text”
},
{
“name”: “reason_for_visit”,
“modality”: “text”
}
]
}
}Once the payload is fetched, you can use it in your application. The payload will contain the model’s configuration used to design the prompt, prompt itself, variables, tools, etc. This ensures that you are well covered across the spectrum.
Monitoring with Traces and Spans
Before we begin this section, let’s recap. The prompt is perfected with evaluation-based iteration, tools are also added, and the payload is deployed and fetched as well.
Now, we see the soul is ready to be connected to different components of the app. By different components, I mean:
APIs: External services that fetch real-time data or perform specific functions.
Embeddings: Vector representations that enable semantic search and similarity matching.
Vector Databases: Storage systems that retrieve relevant context based on embeddings.
Retrieval Augmented Generation: Combines retrieved documents with LLM generation for accurate responses.
Model Context Protocol: Standardized interfaces that connect LLMs with various data sources.
Agents: Autonomous systems that make decisions and execute multi-step workflows.
Essentially, all the components that LLMs can interact with. Let’s take a look that the image below.
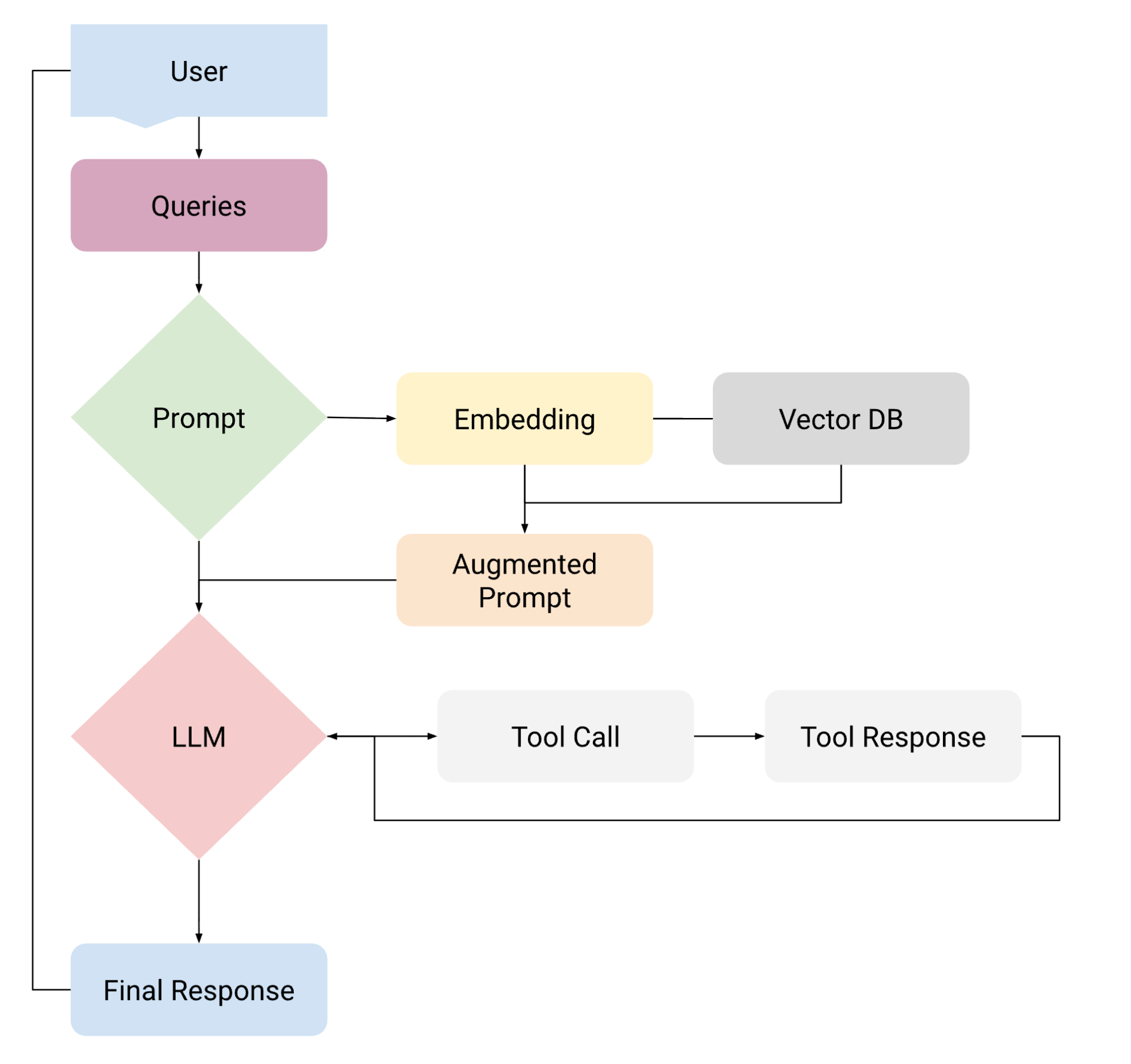
You will see that all the components in the application revolve around prompts. This is true for the most complex agentic systems. But these components have to be monitored or observed. Why? Because through monitoring or observability, we can understand the behaviour of each and every component. In the previous blog, I defined observability as “the practice of monitoring every layer of the application, right from the LLM, multiple APIs, databases, prompts, context, tools, etc. This helps us to see their behaviour in production, allowing us to identify which layer is causing the problem or is on the verge of failing.”
With Adaline, you can monitor the entire journey of the prompt through traces. And simultaneously monitor how each and every component behaves through spans. Meaning, you can observe latency, throughput, and reliability of your prompt. Essentially, asking questions like:
Which component/span takes the longest time to process the information?
What must be done to reduce the latency of the component?
Should you change the configuration of embeddings or try another embedding provider?
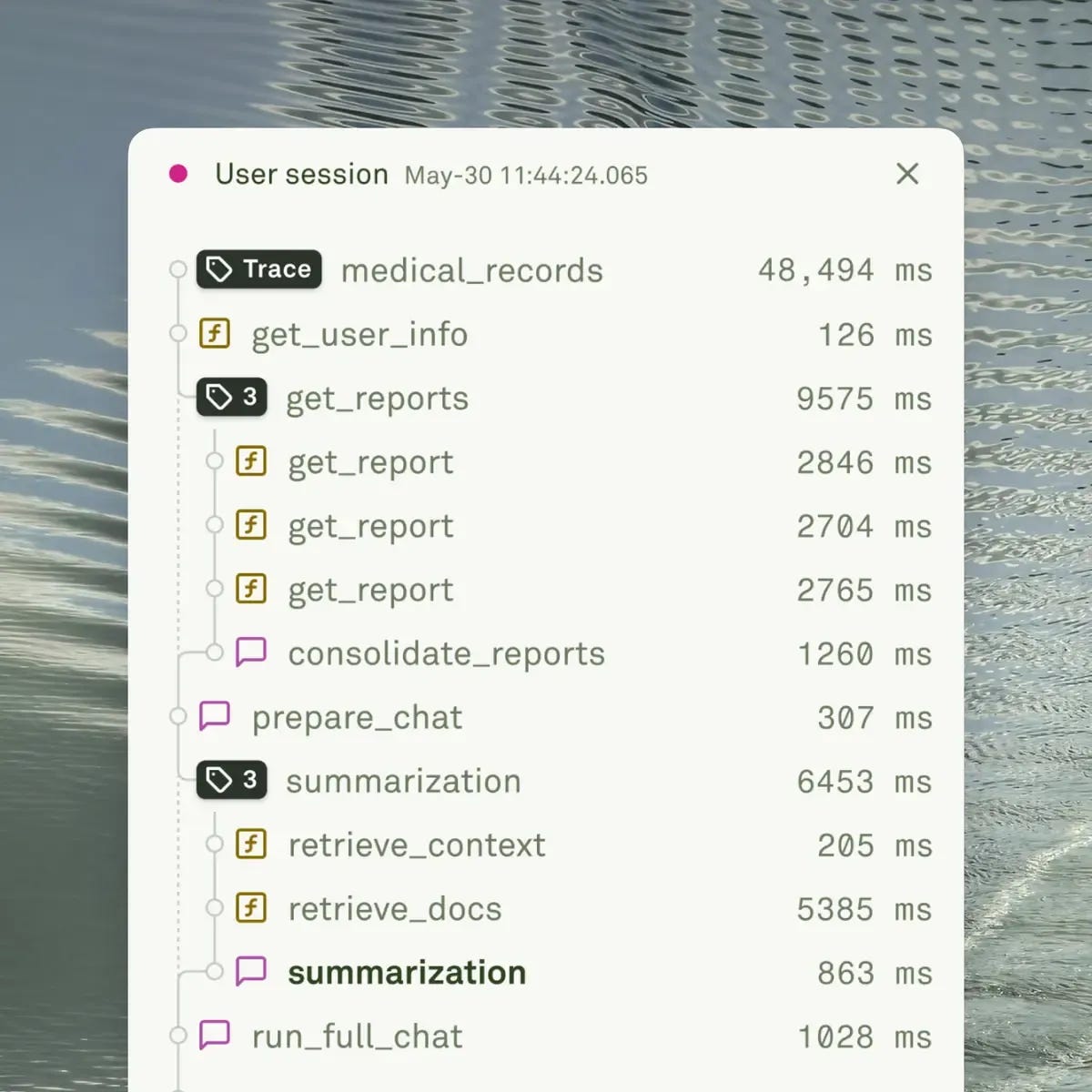
Monitoring or observability makes you ask questions based on the performance of the trace. It gives you essential information to make decisions. These insights drive continuous improvement of your AI product in production. As a product leader, this is one of the crucial features. It allows you to explore and test what works best and what doesn’t.
LLM Observability For Product Leaders

We are in a period where LLMs have become the core of many software. They are brains that gather information, provide insight, and help us make decisions. In one way, they do all the cognitive and tedious work of collecting and processing information.
Closing
Prompt management transforms how teams build AI products. It creates clarity where chaos existed before. Adaline makes this transformation practical and achievable.
The iteration playground lets you test prompts safely before production. The variable editor simplifies collaboration between domain experts and engineers. Deployments become straightforward with version control built in. Gateway ensures secure, reliable prompt delivery to your applications.
Most importantly, Adaline becomes your single source of truth. Every prompt lives in one place. Every change is tracked. Every team member sees the same version. This removes confusion and prevents costly production failures.
Start managing your prompts systematically today. Your users will notice the difference immediately.
