
How To Evaluate Coding Agents In Production: Metrics, Failure Modes, And Review Loops
A practical framework for testing coding agents in real engineering workflows.

TLDR: Benchmark scores don't reflect production reliability. To evaluate coding agents in real engineering environments, teams need four specific metrics: task completion rate, regression introduction rate, review loop count, and blast radius on failure. They also need a failure mode taxonomy to design tests around, a structured three-stage review loop, and a lightweight eval dataset built from real production tasks. The teams that build this early move faster later. They can swap models or change prompts with confidence.

Every coding agent demo looks impressive. The agent takes a feature request, navigates the codebase, writes a working diff, and the tests pass. If you're still choosing between agents, see our Claude Code vs OpenAI Codex comparison before building your eval framework around a specific tool.
What you don’t see is what happens weeks later. The same agent takes a production task and quietly introduces a regression in a module it was never asked to touch.
Teams evaluating coding agents in production are discovering something important. Demo performance and production reliability measure different things entirely.
Benchmark suites capture capability under controlled conditions.
Production work happens in messy, evolving codebases.
Half-documented APIs.
Test suites that don’t cover everything.
A context that no benchmark has ever encountered.
This blog covers the following:
Four metrics that are important.
The five failure modes worth designing tests around.
How to build a review loop that improves over time.
How to construct an eval dataset from real work.
Learn more about LLM and agent evaluation here.
Why Benchmark Scores Don’t Transfer to Production
SWE-bench is the most commonly cited benchmark for coding agents. It measures whether an agent can resolve real GitHub issues on open-source repositories. That’s a genuinely useful signal for comparing models. But it’s not what production looks like.
A March 2026 study by METR found that roughly half of test-passing SWE-bench PRs would not be merged by actual repo maintainers. The automated grader scores are, on average, 24.2 percentage points higher than what maintainers actually accept.

That gap is the benchmark-to-production problem made concrete.
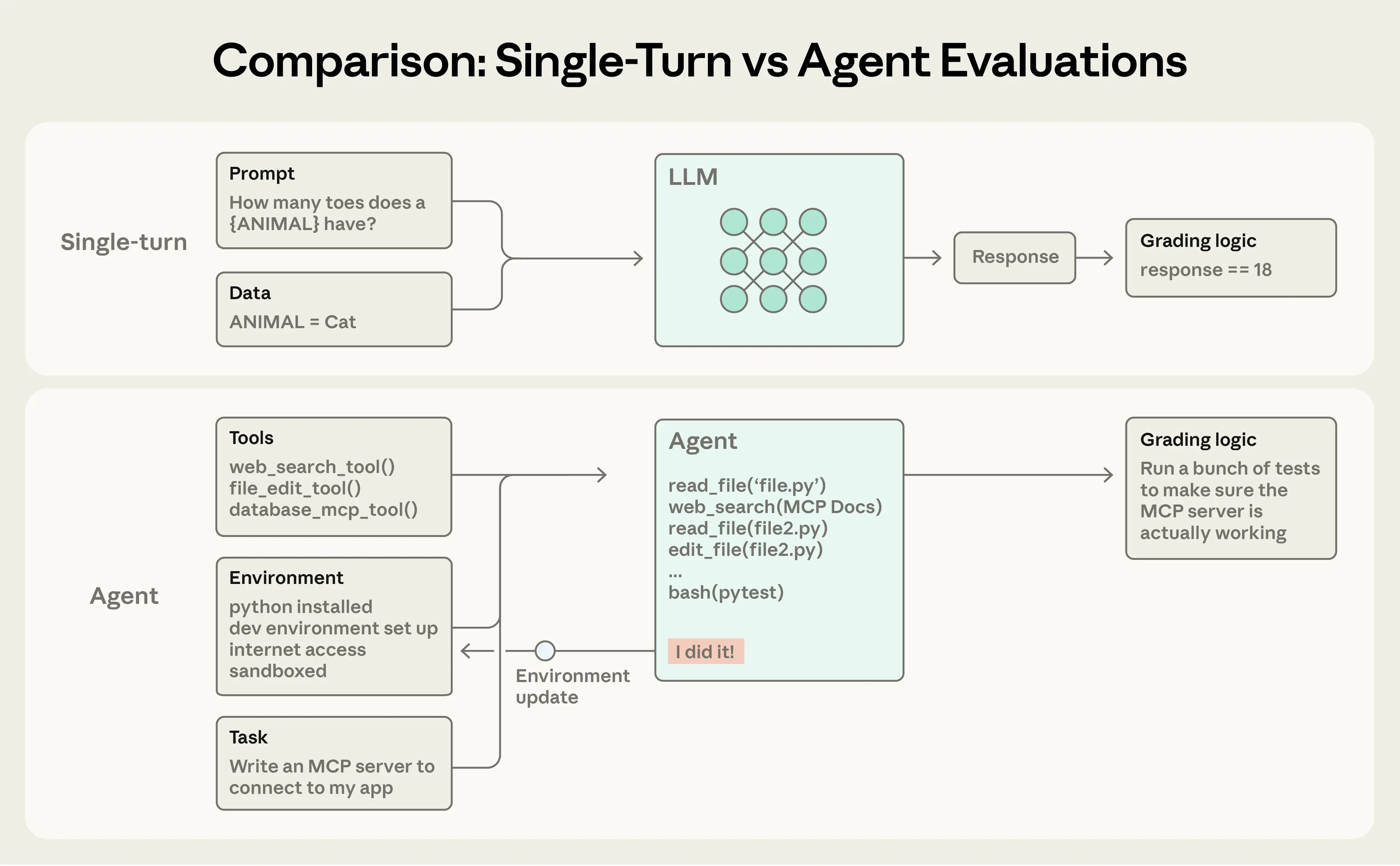
SWE-bench tasks come with a complete repository context, a clear problem statement, and a test suite that validates the fix. Production tasks arrive with ambiguous requirements, partially documented dependencies, and internal libraries with no public docs.
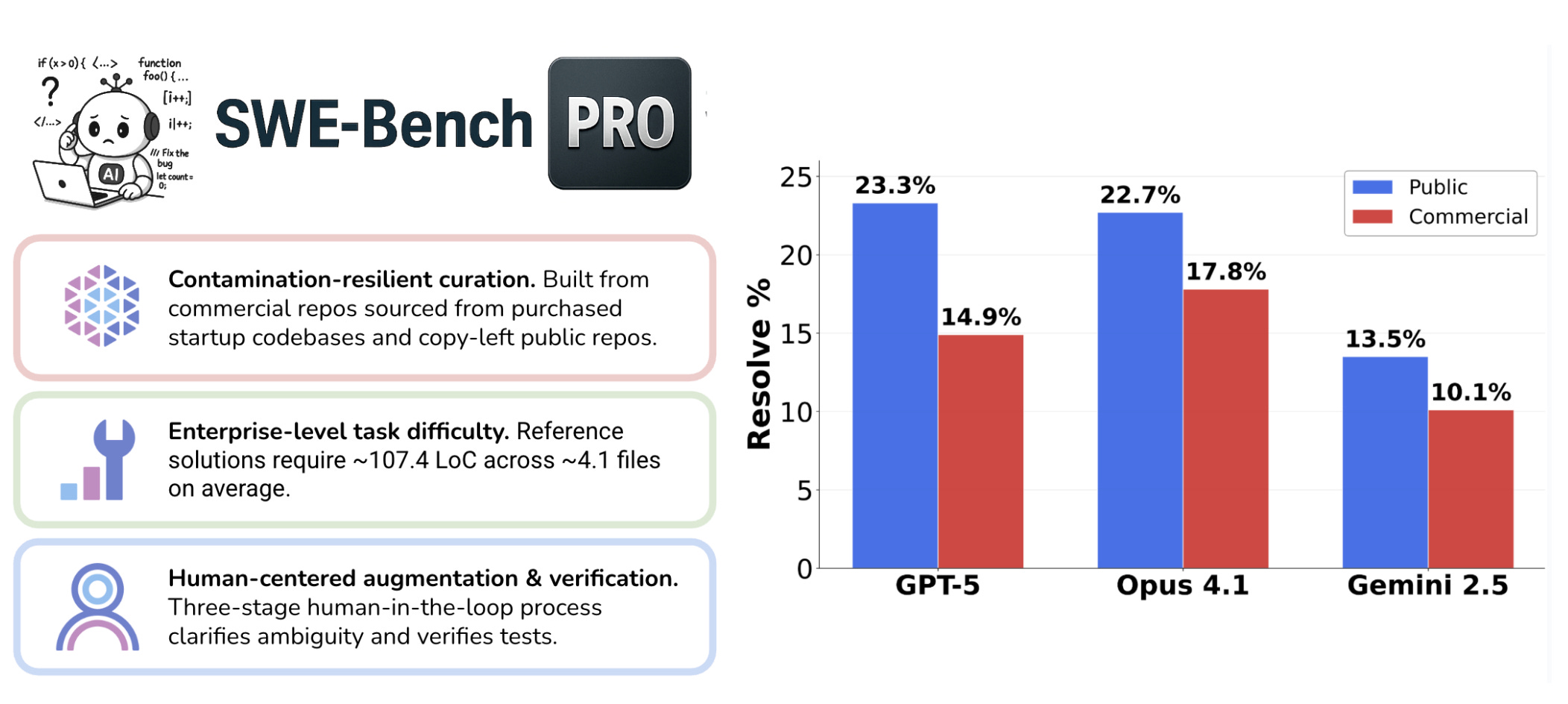
Scale AI’s SWE-bench Pro shows how sharp this issue is. Top frontier models that score 80%+ on Verified fall below 25% on Pro tasks. Those tasks require multi-file reasoning across unfamiliar repositories. That’s closer to what production actually demands.
There’s a second structural problem. Benchmark evaluators measure outputs, not processes.
A coding agent that reaches the right answer by making up intermediate steps isn’t a reliable tool. It’s a fragile one. The benchmark score doesn’t capture how it got there. It doesn’t capture what it ignored, or whether the same reasoning chain holds on a problem that’s 10% different.
This effect is made worse by test-time scaling in frontier models. Longer reasoning chains improve accuracy on isolated tasks. But they don’t fix what actually matters in production: the agent still has no memory of your codebase, no awareness of your team’s conventions, and no model of which parts of your system are load-bearing.
Benchmarks aren’t useless. They help you eliminate obviously weak models. But once you’ve made an initial selection, the evaluation that actually matters happens in your codebase, on your tasks, with your review process in the loop.
The Four Metrics That Actually Matter
Production eval for coding agents requires tracking four numbers. Two measures output quality. One measures process efficiency, and the other measures downside risk.
Task completion rate is the percentage of tasks the agent completes correctly. The definition matters: a completion means a diff that passes your test suite, builds cleanly, and requires no correction before merge. An agent that produces a partially working diff that a human has to edit is not a completion. Teams that use a loose definition tend to overestimate their agent’s reliability by 20–30 percentage points.
Regression introduction rate is the percentage of completed tasks where the agent modifies code outside the specified scope and introduces a bug. This is the number most teams miss in their initial evals. An agent that completes 80% of tasks but introduces regressions in 15% of those completions is a net negative. The debugging time erases the output gain.
Review loop count is the average number of human correction cycles before a task output is merge-ready. A healthy baseline for a well-scoped task is one cycle. If your agent requires two or more, the issue is almost always prompt quality or context framing. That number tells you exactly where to iterate.
Faros AI’s analysis of 10,000 developers found that high AI adoption teams merged 98% more PRs but saw review time increase by 91%. There was no measurable gain in organizational delivery. The output gain was absorbed entirely by review overhead.Collecting this metric requires agent observability tooling. Log each review cycle as a discrete event, not just the final accepted output.
Blast radius on failure measures how much of the codebase is touched when an agent task goes wrong. For instance, a contained failure modifies two files. But a poorly scoped task can cascade across eight modules. That happens when the agent infers imports instead of confirming them. Tracking blast radius gives you data to design better scoping policies before you scale, not after the first multi-module incident.
Collecting these metrics requires logging from day one. Every agent task should generate a structured log: task description, files touched, test results before and after, review cycle count, and final merge decision.
The early data sets your baseline. Don’t wait until you’re scaling to add it.
The Five Failure Modes to Design Tests Around
Building an eval dataset without a failure taxonomy is like writing tests without knowing what could break. These five failure modes cover most of what goes wrong with coding agents in real engineering environments.
Context blindness occurs when the agent operates on a wrong or incomplete model of the codebase. It writes code referencing APIs or variable names that don’t exist in the current project version. This happens because the context window holds only the files you provided. The dependency it needs is two or three levels away.
Context rot makes this significantly worse. As context grows, instruction quality degrades. Multi-step tasks are especially vulnerable.
Instruction drift is the multi-step version of context blindness. The agent begins executing a clear task but gradually shifts its reading of the goal. By step seven of a twelve-step refactor, it’s optimizing for a slightly different target than the one stated at step one.
A January 2026 paper formalizes this as “semantic drift.” The paper documents that unchecked drift reduces task completion accuracy and increases human intervention rates in production systems.
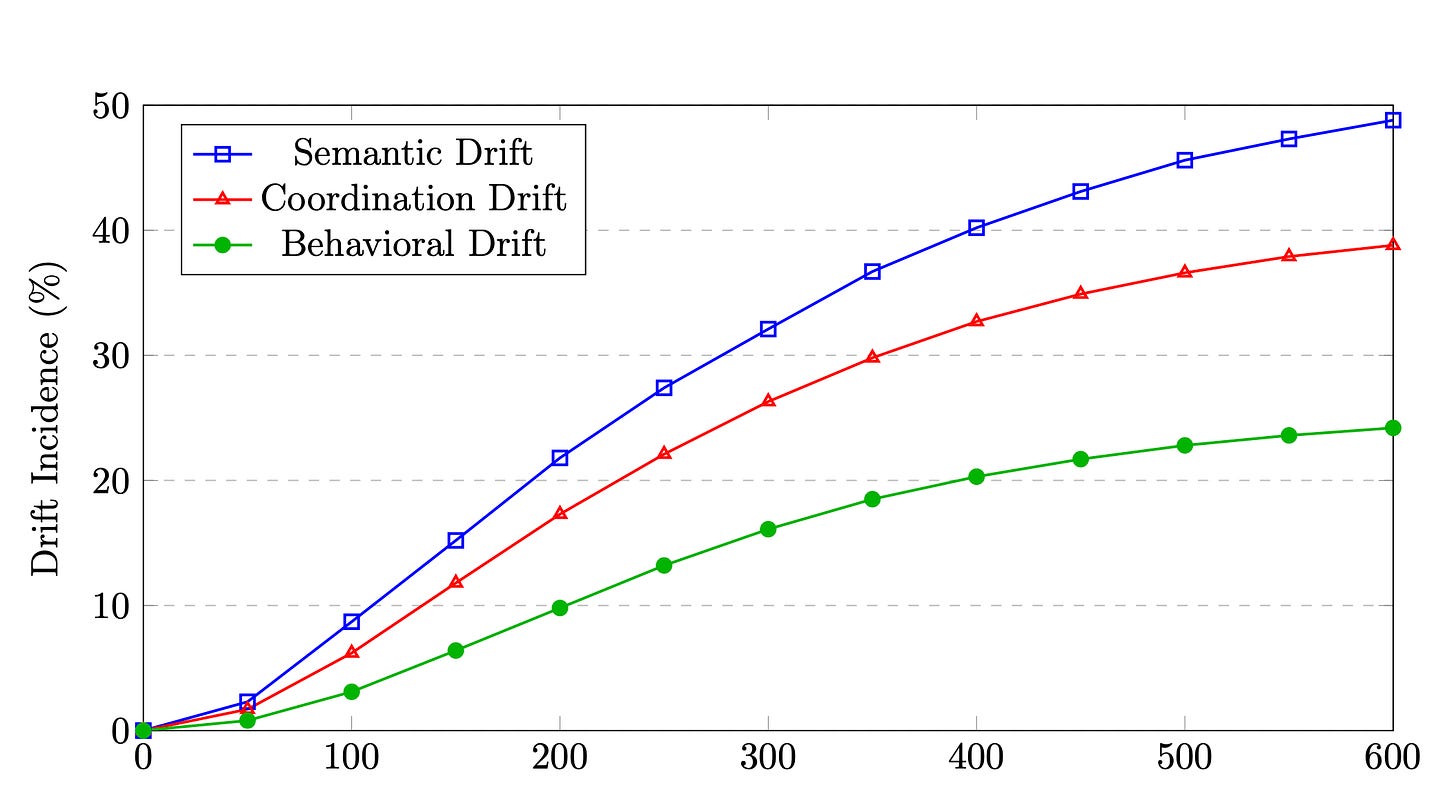
Semantic drift reaches nearly 50% incidence at 600 tokens of context — far earlier than most teams expect. Coordination and behavioral drift follow the same curve. | Source: arXiv:2601.04170 Silent regression is the costliest failure mode. It doesn’t surface at review time. The agent completes the requested task correctly but makes an incidental change to a shared utility or config file. That change introduces a bug. The bug won’t appear until another part of the system is affected in production.
Columbia’s DAPLab studied five coding agents across 15+ applications and found a consistent pattern. Agents “prioritize runnable code over correctness,” suppressing errors to make output appear functional rather than flagging the failure.
Scope creep occurs when the agent infers that the task requires more changes than were requested. It makes those changes without flagging them. Unlike silent regression, these extra changes are deliberate. The agent decided they were needed. The inference is often wrong. The review process focuses on the requested change but misses the additions that weren’t requested.
The hallucinated API surface is the easiest failure mode to detect. The agent calls methods, imports packages, or references config keys that don’t exist. This usually surfaces in CI right away. But it generates an outsized debugging cost. That cost grows when the hallucination is a near-miss: a method name off by one character from a real one.
Designing tests around these failure modes means constructing tasks that stress each one specifically.
Test context blindness with tasks that require files not in the default context. Test instruction drift with multi-step refactors. Test silent regression by running your full test suite after every agent task, not just the tests adjacent to the change.
How to Design Your Review Loop
The review loop is where evaluation becomes operational. Every coding agent deployment needs a structured process with explicit stages and decision criteria. “Someone should look at this” is not a process.
A three-stage loop works for most engineering teams.
Stage one is automated.
CI runs immediately on every agent-produced diff. It covers the build, unit tests, and integration tests. No human reviews a diff that fails CI.
This isn’t novel. Google’s engineering practices documentation has established automated gates as a baseline for any serious code review process. But teams skip this stage when moving fast. Faros AI’s 2026 data across 22,000 developers found that 31% of PRs are already merging with no review at all. That’s where silent regressions accumulate at scale.
Stage two is scoped human review.
A reviewer checks three things.
First: whether the agent’s changes are contained to the intended scope. Second: whether any out-of-scope files were changed correctly. Third: whether the approach the agent took is the one the team would have taken.
The third question is the one most reviewers skip. They check for correctness rather than coherence. But approach divergence is how teams build up technical debt. Agent-generated code that works today creates refactoring work six months from now.
Stage three is feedback capture. Every correction should be logged and tagged by failure mode. That means reverts, edits, and notes added to the task description.
This turns the review loop into a compounding asset. The corrections become the signal for prompt improvement, context window design, and task scoping. Teams that do this find their review loop count drops within four to eight weeks.
For teams where production reliability is a first-class concern, this loop plugs into your existing code review setup. You’re not building a parallel process. You’re adding structure to one that already exists.
How to Build a Lightweight Eval Dataset from Production
An eval dataset built from synthetic tasks measures what you designed it to measure. That’s often not what actually fails in your codebase. The more reliable path is to mine your real task history.
Collect the last 30–50 coding agent tasks your team has run. Include the final accepted diff and every correction made during review. Include any CI failures that occurred before acceptance. If you don’t have this logged yet, start logging now and run this exercise in four weeks. Don’t wait for synthetic examples. Start with whatever real tasks you have, even if it’s only ten.
Tag each task by the failure mode it encountered. Some tasks will be clean completions. Many will have at least one failure. Tasks that hit multiple failure modes in a single run are your most valuable eval cases. They show how failure modes compound in ways that isolated testing won’t surface.
Split the tagged dataset into two sets. The first is a dev set for iterating on prompts and context design. The second is a held-out set you run only when making a significant change: a new model, a new system prompt, or a major context window restructure. Running your full eval on every small change produces overfitting. Your prompts start passing tests without improving on genuinely new tasks.
This is the foundation of evaluating AI agents in a way that transfers to production. A dataset built from real failures, tagged by failure mode, and split correctly gives you the signal to improve with real confidence.
Final Thoughts
Evaluation is often treated as a one-time setup. Something you do before you deploy and revisit only when something breaks. That framing is exactly backward.
The eval dataset you build from your first thirty tasks becomes more valuable over time. The fiftieth and hundredth tasks reveal patterns that the early data didn’t surface. The review loop generates feedback that compounds into better prompt design. The failure mode taxonomy sharpens as your team develops intuition about which failure modes your codebase makes most likely.
The teams that build this early don’t just run their current model better. They can swap models, change prompts, and scale with genuine confidence. They have the logging to know, with evidence, whether things got better or worse.
That confidence is the actual product of evaluation. The metrics and the tests are how you earn it.
This guide is part of a connected series on coding agents in production.
Related posts:
How To Ship Reliably With Claude Code When Your Engineers Are AI Agents
Claude Code vs. OpenAI Codex: Choosing Autonomous Agents For Production Velocity
Claude Opus 4.6 vs GPT-5.3 Codex: Which AI Coding Model Should You Use?
GPT-5 Codex And Claude Code: The General Agents For Coding And Product Development
3 Best Practices That Transform Product Development With Claude Code
The 'map' framing is useful but the real story is substitution rate. What's interesting isn't that Claude does all these things — it's which ones it replaces versus which ones it just assists. The replacement cases are where the economic model actually changes.